本文主要是介绍读论文系列(一)Automated software vulnerability detection with machine learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Methods
- Build-based feature extraction(基于编译的特征提取)
- Source-based feature extraction(基于源的特征提取)
- Labels(生成标签)
- Models
- Source-based models(基于源代码的模型)
- Build-based models (基于编译的模型)
- Experimental results
- Source-based detection
- Build-based detection
- Comparison and combined model performance
Methods
为了检测C和c++代码中的漏洞,我们考虑了两种互补的方法。
第一种使用从编译和构建过程中生成的程序的中间表示(IR)中提取的特性。
第二种方法直接对源代码进行操作
Build-based feature extraction(基于编译的特征提取)
在函数层,我们提取了函数的控制流图(CFG)。
在控制流图中,我们提取特征关于每个基本块中发生的操作(操作码向量,或 op-vec)以及定义和使用变量(使用定义矩阵)。
CFG是程序在执行过程中可以采用的不同路径的图形表示。每个节点都是一个基本块——一个没有分支行为的代码单元。

Source-based feature extraction(基于源的特征提取)
- 定义一个词法分析程序:解析代码并将元素分类到不同的容器中
comments (which are currently removed) 注释
string literals 字符串
single character literals 单个字符
multiple character literals 多字符文字
numbers 数字
operators 运算符
pre-compiler directives 预编译指令
names 名称 - 名称进一步细分为关键字(如for、if等)、系统函数调用(如malloc)、类型(如bool、int等)或变量名。

3.标记序列转换为向量表示 - bag-of-words vector
- word2vec

Labels(生成标签)
在函数级别进行标记
在特征提取过程中为每个函数生成标签
使用Clang static analyzer (SA)
去除掉那些和安全漏洞无关的警告
将这些结果与函数相匹配
对标签进行二值化,根据有没有静态分析结果 分别标记为good(negative)和buggy(positive)。
如果我们的检测模型将一个函数标记为buggy,并且还有一个静态分析结果,这将被视为真正的阳性。类似地,当函数没有静态分析结果时,将其标记为buggy会被视为假阳性。
Models
构建机器学习模型来检测BUGGY函数时,我们考虑两个目标。
首先,我们的目标是评估整体可能的性能——每个模型能够预测代码中存在的不安全行为的程度。
其次,我们的目标是比较基于构建和基于源代码的功能的性能,以发现哪一组更能预测代码质量。
因此,我们构建独立的基于源和基于构建的模型,并考虑组合的方法。
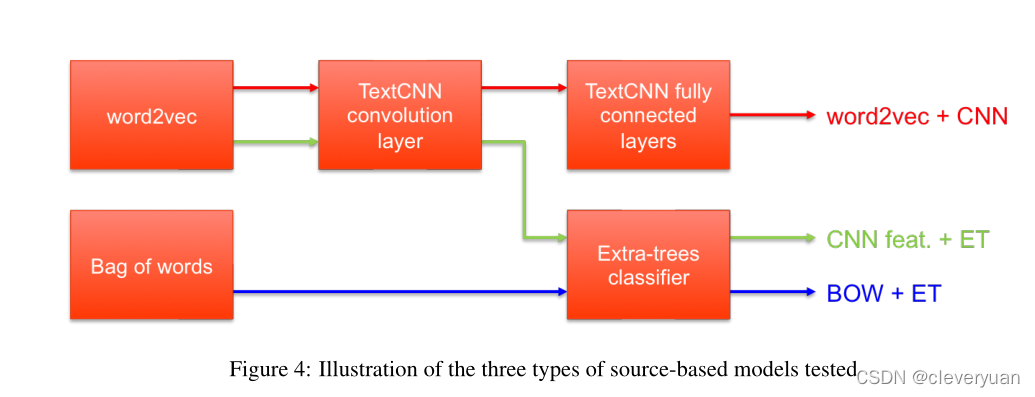
Source-based models(基于源代码的模型)
我们基于源代码的模型直接从单个函数的源代码中获取一个特征向量,并输出一个对应于给定函数包含bug的可能性的分数。
根据前面提到的bag-of-word vector和word2vec 两种向量表示方法,构建了多个模型
Build-based models (基于编译的模型)
random forest
Experimental results
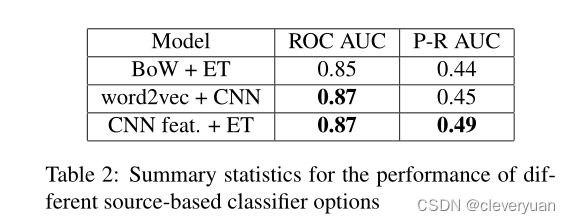
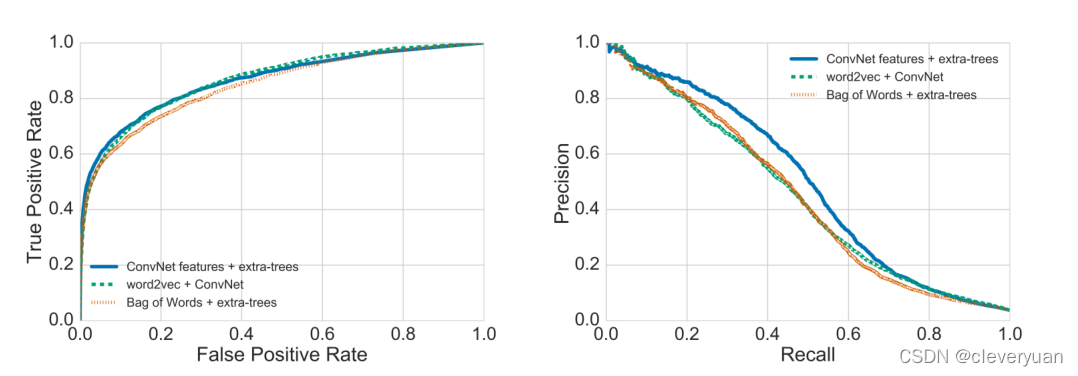
Source-based detection
Build-based detection

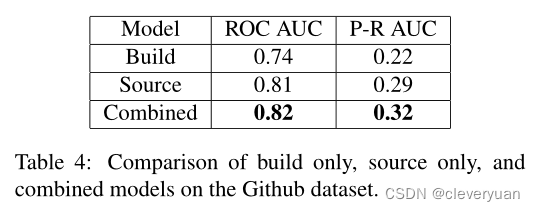
Comparison and combined model performance

这篇关于读论文系列(一)Automated software vulnerability detection with machine learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









