本文主要是介绍Multi-Modal MRI Reconstruction Assisted with Spatial Alignment Network【论文阅读】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Multi-Modal MRI Reconstruction Assisted with Spatial Alignment Network
摘要
在医疗引用中,核磁共振经常要分析不同分辨率的数据,在实际采集过程中,对某一些模态降采样,并利用模态间数据的冗余性,由全采样的模态对这部分模态进行更加有效的重建是一种思路,然而,由于空间不对齐(spatial misalignment),这种重建可能带来负面影响,本文通过引入空间对齐,提升了目标模态的重建质量。

方法
为了实现空间对齐,本文使用了两种方式:
- 衡量源模态图像(reference image)和生成目标模态图像(target image)之间的空间对齐关系,从而扭曲源模态图像。
- 为了解决二者对比度不同的问题,在重建损失(本文中使用了L1范数,除此之外还引入了GAN损失)之外额外引入了配准损失(registration loss)。我看了一下实际上就是在扭曲源模态图像的时候对变换进行优化。
变量定义
定义全采样的MRI图像 x ∈ C N x \in \mathbb{C}^{N} x∈CN,其中 N = N x ∗ N y N=N_x*N_y N=Nx∗Ny,x为负数。
空间对齐网络(Spatial Alignment Network)与 L s m o o t h \mathcal{L}_{smooth} Lsmooth计算
估计一个置换场 Φ \Phi Φ,为0填充k空间复原的高分辨率target模态图像和reference模态图像的空间差异计算出。
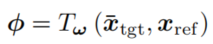
Φ ∈ R 2 ∗ N \Phi \in \mathbb{R}^{2*N} Φ∈R2∗N,相当于把x从复数域展开了,所以维数是两倍,具体使用 Φ \Phi Φ进行配准的操作是:
A r e f A l i g n = S ( Φ , x r e f ) A_{ref}^{Align}=S(\Phi,x_{ref}) ArefAlign=S(Φ,xref)
S ( Φ , x r e f ) [ p ] = x r e f [ p + Φ [ p ] ] S(\Phi,x_{ref})[p]=x_{ref}[p+\Phi[p]] S(Φ,xref)[p]=xref[p+Φ[p]]
而根据这个置换场计算出smooth损失,用以调优这个置换场。配准中的常规操作。

整体算法流程
θ \theta θ定义重建算法参数, w w w定义配准参数, ρ \rho ρ定义GAN的生成器参数, γ \gamma γ定义GAN的判别器参数。


这篇关于Multi-Modal MRI Reconstruction Assisted with Spatial Alignment Network【论文阅读】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






