本文主要是介绍激光雷达上车,自动驾驶的下一步?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2021年-2030年,自动驾驶已然步入了高速发展的黄金十年。
公开资料表明,到2030年,市场每年将有20%-25%比例的车辆会具备高级别辅助驾驶功能,类似特斯拉的NOA。
这意味着,每年将有400-500万辆的标配空间,市场潜力超乎想象。
目前,除特斯拉、蔚来、小鹏等新势力之外,北汽极狐、吉利极氪、上汽智己、长城摩卡等也都已推出了各自的领航辅助驾驶系统。
而这也意味着“激光雷达上车”已经成为了汽车智能化的最新“标签”。
在今年的广州车展上,包括小鹏G9、威马M7、哪吒s、沙龙机甲龙等越来越多的车型都搭载了激光雷达。
各大车企都在全力升级自身的硬件配置,同时也在进行着一系列的针对复杂场景的数据积累。一场围绕高阶自动驾驶的量产排位争夺战已经打响。
掌握数据融合,才能掌握未来
“在整个自动驾驶的黄金十年中,我们可以把汽车智能化的发展看作是一个指数函数,先平滑前进,再加速跨越式发展,直冲云霄。”觉非科技CEO李东旻表示。
因此,前五年便可视为行业的关键转折点。无论是主机厂、激光雷达厂商,还是其他研发厂商,都要抓住这次的增长期。
而不得不提的是,伴随这场拉力赛产生的,还有业内对于高等级数据融合的刚性需求,并且也在不断增强。
其中,以激光雷达为传感器并融合其他感知数据的路线已在Robo-taxi、低速物流等L4场景得到验证并规模化部署。
但在乘用车走向高级别自动驾驶的应用中,依然存在不小的挑战。
“目前,业内基于激光点云本身的目标感知和目标决策相关的算法并不够丰富,其模型的精准度与训练程度也并不是很高。”李东旻表示。
其次,激光雷达也要与其他传感器、高精地图、惯导进行相应的融合计算。
这对于整个汽车行业来说,都是一个新的课题与命题。在技术的产品化方面,整个行业依然有非常大的技术鸿沟要去跨越。
为了配合主机厂攻克乘用车量产的难题,觉非科技此前进行了一系列的基于激光点云的融合感知能力实践,并自研多个点云算法。
如稀疏点云卷积算法和单目尺寸还原算法,能使得较大的模型在量产车的嵌入式控制器上实现精度更高的激光雷达+多路视觉的融合感知,包括环境感知、态势感知与行为预测,并已形成了量产的融合感知解決方案。
融合感知是无人驾驶的关键步骤,也是目前研究最多的课题。
觉非科技的融合感知算法将视觉、点云与毫米波的原始数据进行融合计算,而后进行3D追踪,输出更加精准与完整的感知结果。同时借助高精地图和路端全局样本,对交通参与者的行为轨迹进行精准预测。
“不过,多传感器融合面临的最大技术难点就是实现时间和空间的同步。”李东旻介绍。
为此,觉非科技自研基于FPGA高精度授时板卡,采用传感器统一授时,同步UTC时间,误差不超过100微秒。
同时结合丰富可扩展的多传感器融合交通算法库,以更低的计算时延提供单点精准感知和及时的管控触达,为自动驾驶各类应用场景提供了感知和定位软硬一体化的解决方案。
以“路”为始,发力车端,打造完整闭环
觉非科技自成立起便确立了无比清晰的产品定位与战略规划:以数字化道路为底座,以多传感器融合为核心技术,为自动驾驶车辆提供全场景的领航服务。
配合今年激光雷达上车的大趋势,觉非科技推出了“全栈融合感知与定位解决方案”。
这套方案可针对不同场景和客户提供定制化的前装与后装定位算法、多传感器融合感知算法及动态交通信息服务,为自动驾驶车辆从低级别辅助驾驶功能升级为NOA赋能。
而在融合感知技术与数据闭环能力的搭建上,觉非科技则通过此前部署于路侧的“知寰™”得以实现。
知寰™本身即具备LiDAR+Camera的感知能力,它可以以上帝视角的方式,7×24小时高效收集全局视角下的交通数据。
李东旻表示:“路侧一个传感器点位一天产生的数据量就高达50TB,是一辆无人驾驶汽车收集数据量的3~5倍”。
车端雷达只能扫描车辆的一面、两面,而路侧传感器却能从俯视角采集车辆的三面、四面形成几何立体视觉,并且路侧也能完整采集到很多类似交通事故等车端难以获取的低频率Corner Case,并记录下它们的数据状态。

觉非科技多传感器融合感知全息路口
觉非科技通过这些数据优化自己的融合感知算法,为在车端部署感知定位功能提供了关键的技术支持。
如果说,之前觉非科技在路侧的发力是在深挖智能汽车数据平台的护城河,那么下一步,觉非面向量产车提供的“全栈融合计算解决方案”便是为攻克高阶自动驾驶城提前做好了准备。
无数实践经验表明,要想横向地打通不同场景,无论是面向开放、半开放,还是封闭道路,无论是商用车还是乘用车,其对于全栈融合解决方案商的要求非常之高,相当于要满足每一个业务场景的定制化需求。
但行业中却极少出现可以跨品类、跨公司、跨车型和场景的方案商去支撑这些高定制化需求。
觉非科技的出现填补了尴尬的市场空白。
针对高级别自动驾驶,觉非科技可整合华为MDC、地平线J5、英伟达Orin等高性能平台,按照不同的算力需求,从中等算力平台和大算力平台两个纬度,精细化地部署融合感知、融合定位等产品与解决方案。
与此同时,觉非针对车端推出了高精融合定位终端系统“鸣鸿™”,其内置环境感知算法,FPGA车规级计算芯片等技术能力,可与车上搭载的高精地图进行特征匹配,利用视觉与特征匹配结果为惯导与卫导提供关键信息输入。
特别是在城市多路径场景、多层立交或隧道等卫导与惯导干扰严重的场景中,可保持车辆定位精准稳定的输出。
“今年开始,整个汽车的算力正在不断提升,这时,一个独立的硬件终端便有了存在的必要。其高鲁棒性与即插即用的特性,可快速帮助主机厂完成整个迭代过程。”李东旻表示。
而在整体解决方案上,车端数据配以OTA,与路端积累的训练模型、训练数据、数据真值,共同完成了自动化的数据更新和闭环,形成车端环境数据自更新方案。
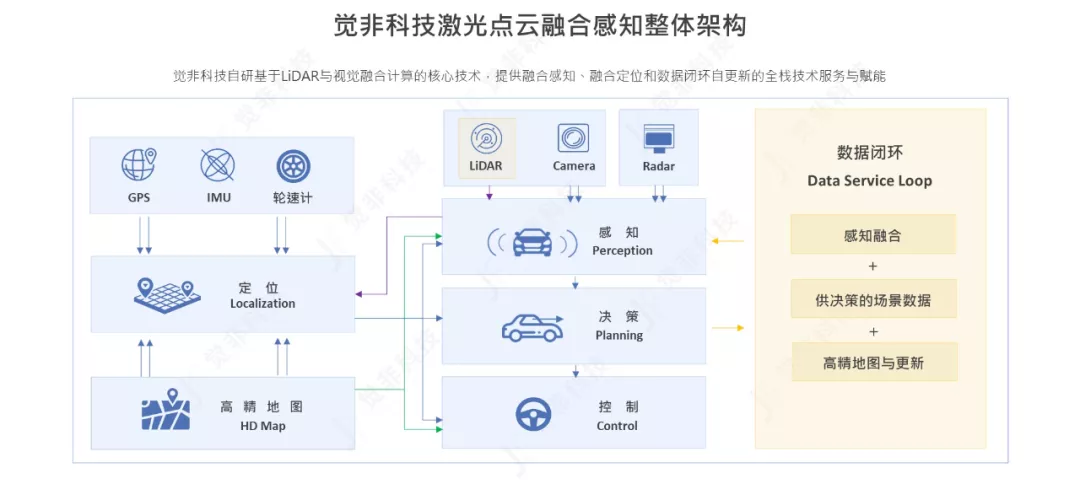
觉非科技激光点云融合感知整体架构
在过去的实践中,觉非已积累了非常重要的能力——用业务前台实现的技术落地、数据和场景的经验,以及know how闭环,来反哺其技术中台,加强技术实力。
目前,觉非已将“自动驾驶全栈融合解决方案”应用于不同场景,包括车辆变道、长隧道、高架桥下.
同时已与多个主机厂合作伙伴达成合作,从精度、可靠性、成本维度,为众多合作伙伴提供定制化、高规格、可量产落地的产品方案与服务。
在自动驾驶车辆尚未大规模落地量产的前夜,觉非科技已经率先在路端积累了大量的模型训练和优化经验,并在多种不同的场景下验证了自身的项目能力。
如今,随着2022年即将有十几款前装激光雷达的车型量产,更高等级智能驾驶的“未来”已经到来。
觉非科技希望将多传感器融合感知赋能于自动驾驶能力,服务于产业的不同层面与细分场景。
“自动驾驶技术本身不是商品,而是一种能力,这个能力可以结合到不同场景与车辆上,产生不同的价值。觉非科技希望将多传感器融合感知赋能于自动驾驶能力,服务于产业的不同层面与细分场景。我们期待的产业终局是Copy From China。”李东旻表示。

这篇关于激光雷达上车,自动驾驶的下一步?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








