本文主要是介绍7.17~7.23周记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这天主要就讲了一个结构体和递归函数
这边就主要放几个例题来回顾递归
1.输入非负整数m和n,输出组合数 其中m≤n≤20;

这个是一个很经典的递归题目 根本思想是 C(n-1,m-1)*m/n=c(n,m); 当然如果出现像C(4,6)这种情况的数字 我们要把它转化为C(2,6)然后进行递归。
代码详解:
#include <stdio.h>double Cmb(int x, int y);int main()
{int m, n;scanf("%d%d", &m, &n);printf("%.10g\n", Cmb(m, n));return 0;
}
double Cmb(int x, int y) {//主要的递归部分。if (x == y) {return 1;}else if (y == 0) {return 1;}else if (y == 1) {return x;}else if (y > x / 2) {//转化y = x - y;return Cmb(x, y);}else {return Cmb(x - 1, y - 1) * x / y;}
}2.辗转相除法之最大公约数的求解
代码详解:
Bool check(int a, int b){Int r;if(a<b){Int t=a;a= b;b= t;}//这个是让最后输出的a>bwhile(b!=0){r=a%b;a=b;b=r;}//辗转相除法最后出来的a就为最大公约数
3.切面条
一根高筋拉面,中间切一刀,可以得到2根面条。
如果先对折1次,中间切一刀,可以得到3根面条。
如果连续对折2次,中间切一刀,可以得到5根面条。
那么,连续对折10次,中间切一刀,会得到多少面条呢?
解析:由于对折次数仅为10,数据规模并不大,可以通过手算简单的完成。
对折0次,得到2根;
对折1次,得到2 * 2 - 1 = 3
对折2次,得到3 * 2 - 1 = 5
对折3次,得到5 * 2 - 1 = 9
对折4次,得到9 * 2 - 1 = 17
对折5次,得到17 * 2 - 1 = 33
对折6次,得到33 * 2 - 1 = 65
对折7次,得到65 * 2 - 1 = 129
对折8次,得到129 * 2 - 1 = 257
对折9次,得到257 * 2 - 1 = 513
对折10次,得到513 * 2 - 1 = 1025
代码详解
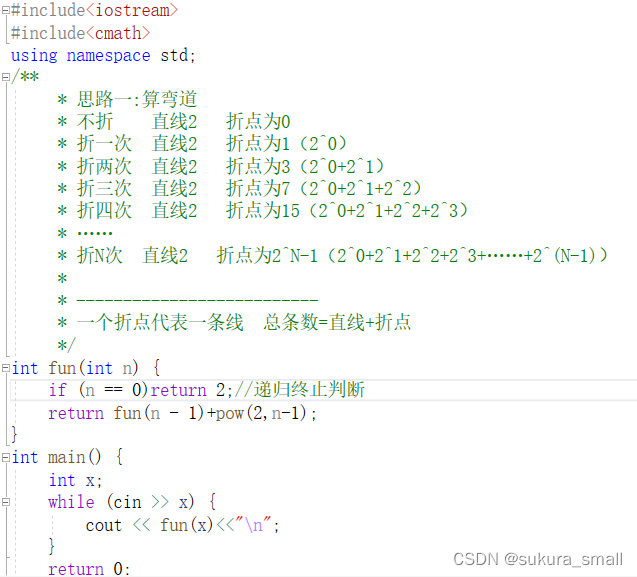
4.车队
X星球特别讲究秩序,所有道路都是单行线。
一个甲壳虫车队,共16辆车,按照编号先后发车,夹在其它车流中,缓缓前行。
路边有个死胡同,只能容一辆车通过,是临时的检查站,如图所示。
X星球太死板,要求每辆路过的车必须进入检查站,也可能不检查就放行,也可能仔细检查。
如果车辆进入检查站和离开的次序可以任意交错。那么,该车队再次上路后,可能的次序有多少种?
为了方便起见,假设检查站可容纳任意数量的汽车。
显然,如果车队只有1辆车,可能次序1种;2辆车可能次序2种;3辆车可能次序5种。
代码详解
#include <stdio.h>int f(int n,int m)
{if(n==0) //如果左边没有车返回1return 1;if(m==0) //如果检车站没车就入栈return f(n-1,1);if(m>0)//如果检车站有车//分两种情况,车辆入站和出站return f(n-1,m+1)+f(n,m-1);return 0;
}int main()
{printf("%d",f(16,0));return 0;
}第一天的内容还是相对比较简单的 随着第二天的stl的涉及我发现我的脑子逐渐开始不够用了......
(一)vector容器
对于vector容器我是这么理解的 他可以当成一个随意可以变化大小内存的数组 他不像我们之前学的数组要提前给他一个比如说a[1000]的内存 它是你给他存多少它就有多少
1.存放并输出一般的函数
1.存放并输出一般函数
#include<bits/stdc++.h>
using namespace std;int main() {vector<int >v;int x;for (int i = 0; i < 3; i++) {cin >> x;v.push_back(x);}/*for (auto it = v.begin(); it != v.end(); it++) {cout << *it << endl;}*/sort(v.begin(), v.end());for (int i = 0; i < 3; i++) {cout << v[i]<<" ";}
}像上述代码一样的 我们可以吧vector看成一个数组就行 怎么对待数组就怎么对待vector
像结构体一样的数组我们也可以用vector来运行
#include<bits/stdc++.h>
using namespace std;struct stu {int num;string x;
};bool cmp(stu a,stu b) {return a.num < b.num;
}
int main() {vector<stu>v;stu l;int h;string name;for (int i = 0; i < 3; i++) {cin >> name>>h;l.x = name;l.num = h;v.push_back(l);}sort(v.begin(), v.end(), cmp);for (auto it = v.begin(); it != v.end(); it++) {cout << (*it).x << (*it).num<<endl;}return 0;
}
字符串也是可以的啦
3.存放并输出字符串类型数组
#include<bits/stdc++.h>
using namespace std;int main() {vector<string>v;for (int i = 0; i < 3; i++) {string s;cin >> s;v.push_back(s);}for (int i = 0; i < 3; i++) {cout << v[i]<<" ";}
}当时在看到输出能用cout<<v[i]的时候就在想是否能有方法让其输入的时候用cin>>v[i] 因为vector一开始是没有内存 所以必须用push_back来给vector创造一个内存空间 后来想到用resize这个函数 先给vector赋值一个内存
具体代码如下:
#include<bits/stdc++.h>
using namespace std;int main() {vector<int >v;int x; cin >> x;v.resize(x);for (int i = 0; i < 3; i++) {cin >> v[i];}/*for (auto it = v.begin(); it != v.end(); it++) {cout << *it << endl;}*/sort(v.begin(), v.end());for (int i = 0; i < 3; i++) {cout << v[i]<<" ";}
}还有一些赋值的方法比如assign()函数
assign有两种方法的赋值
1.assign(区间)
它输出的数据是这个区间里面的所有数
具体代码如下
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v1(10,100);vector<int>v2;v2.assign(v1.begin(), v1.end());for (int i = 0; i < 10; i++) {cout << v2[i]<<" ";}
}2.assign(n,elem)
它给n个数字附上elem类型的数据(这个elem代表的是任意类型的数据的值)
具体代码如下
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v2;v2.assign(10, 55);for (int i = 0; i < 10; i++) {cout << v2[i]<<" ";}
}它其实跟一开始对v2赋值一样;
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v2(10,55);for (int i = 0; i < 10; i++) {cout << v2[i]<<" ";}
}对于vector有几个函数
v.begin() v数组的开头
v.end()v数组的结尾
v.capacity()v的容量
v.size() v的大小
其中v的容量>=v的大小
v.resize(n)指定v的容量为n
如果变大 那么超出的部分就自动为0;如果变小 那么超出的部分就自己删除。
v.empty()返回值为bool类型 判断v数组是否为空;
v.push_back(ele) 在v函数的尾部插入元素ele
v.pop_back();删除最后一个元素
insert(const_iterator pos,ele)//在pos的位置插入ele
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v2(10,55);v2.insert(v2.begin() + 2, 100);for (int i = 0; i <=10; i++) {cout << v2[i]<<" ";}
}在v2的第三位(开头后两位)插入数据100
insert(const_iterator pos,n,ele)//在pos位置插入n个ele
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v2(10,55);v2.insert(v2.begin() + 2,2, 100);for (int i = 0; i <=10; i++) {cout << v2[i]<<" ";}
}erase是删除 也跟上述insert同理
例子:
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v2(10,55);v2.insert(v2.begin() + 2,2, 100);for (int i = 0; i <=10; i++) {cout << v2[i]<<" ";}cout << endl;v2.erase(v2.begin(), v2.begin()+2);for (int i = 0; i <= 8; i++) {cout << v2[i] << " ";}
}结果
55 55 100 100 55 55 55 55 55 55 55
100 100 55 55 55 55 55 55 55
cout<<v.front()<<end; 和cout<<v.back()<<endl
分别是输出第一个数和最后一个数;
互换容器
v1.swap(v2); 其中v1和v2容器交换这个swap有什么用呢?
来看接下来的代码
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v2;for (int i = 0; i <=1000000; i++) {v2.push_back(i);}cout << "容器的容量" << v2.capacity()<<endl;cout << "容器的大小" << v2.size();
}运行结果:
容量的容量1049869
容器的大小1000001
这个容量是系统给你分配的 当你的数据开始逐渐变大的时候系统给你多分配一些容量
大小就是数据的个数
那么接下来我们用resize()让v2容器变小看看代码运行结果
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v2;for (int i = 0; i <=1000000; i++) {v2.push_back(i);}v2.resize(3);cout << "容器的容量" << v2.capacity()<<endl;cout << "容器的大小" << v2.size();
}运行结果:
容器的容量 1049869
容器的大小 3
我们不难发现虽然我们使用resize使vector的大小变小 但vector的容量仍然没有变 因此我们也可以得出vector只会拓展但不会减小 那这时候就得用上我们上面讲的swap 毕竟不能让内存白费~~O.o
#include<bits/stdc++.h>
using namespace std;int main() {vector<int>v2;for (int i = 0; i <= 1000000; i++) {v2.push_back(i);}v2.resize(3);vector<int>(v2).swap(v2);cout << "容器的容量" << v2.capacity() << endl;cout << "容器的大小" << v2.size() << endl;
}结果:
容器的容量3
容器的大小3
至于用vector存入二维数组以及对二维数组的每一行进行排序 我们可以看以下的代码:
#include<bits/stdc++.h>
using namespace std;
int main()
{vector<int>v[2];//其中[]中的2代表一共有2行 你给定了一个范围 至于列 也是随意变化for (int i = 0; i < 2; i++) {for (int j = 0; j < 3; j++) {int x;cin >> x;v[i].push_back(x);}sort(v[i].begin(), v[i].end());}for (int i = 0; i < 2; i++) {for (int j = 0; j < 3; j++) {cout << v[i][j]<<" ";}cout << endl;}return 0;
}结果可以复制自己看代码输出 它输出的是一个每行排过序的二维数组
(二)栈stack
stack<type>s;
常用接口 :
s.push(elem)向栈顶添加元素elem
s.pop() 从栈顶移除第一个元素
s.top()返回栈顶元素 返回类型为所定义的类型
s.size()返回栈中元素 返回类型为所定义的类型
s.empty()判断是否为空 空则返回true
//关于一些对栈的思考以及题目另写
(三)队列queue
常用接口:
queue<type>q
q.push(item); 把item放进队列
q.front():返回队首元素 不会删除
q.pop():删除队首元素
q.back():返回队尾元素
q.size():返回元素个数
q.empty():检查队列是否为空
这个队列和上面的栈的区别就是一个是只有一个口用来进出(栈) 另一个就是有两个口 但每个口要么只能进 要么只能出 那有没有一个更为简便的容器能做到(栈)和(队列)结合呢?
当然是有的 那就是deque
(四)双端队列deque
dp[i]:返回队中下标为i的元素
dq.front():返回队头
dq.back():返回队尾
dq.pop_back():删除队尾
dq.pop_front():删除队头
dq.push_back(e):在队尾添加一个元素e
dq.push_front(e):在队头添加一个元素e
deque就实现了两端既能进又能出
(五)set集合
set<type>s;
s.insert(item); 把item放进set
s.erase(item); 删除元素item
s.clear(); 清空set
s.empty(); 判断是否为空
s.size(); 返回元素个数
s.fine(k); 返回一个迭代器,指向键值k
s.lower_bound(k); 返回一个迭代器,指向键值不小于k的第一个元素
s.upper_bound(k); 返回一个迭代器,指向键值大于k的第一个元素s.
s.swap(s2) s和s2两个容器交换
要注意 set容器里面的数据没有重复的
这里在打代码的时候突发奇想 我在想 如何输出我想要查找的数的下标 也就是在set容器里面的位置 这里我写了一个代码:
#include<set>
#include<iostream>
using namespace std;
int main()
{set<int> s;s.insert(8); //从尾部插入元素s.insert(1);s.insert(12);s.insert(6);s.insert(8); //重复的元素直接忽略//set<int>::iterator it;auto pos = s.find(8);if (pos != s.end()) {cout << *pos;}else {cout << "sb";}
}很难过 输出的内容是8而不是3 因为*pos是指针 输出对应的内容 所以当时就想了很久是否能输出
后来发现set容器不支持找出查找的数的下标 但有一个方法就是容器转换 把这个set容器转化为vector容器 具体代码如下
#include<bits/stdc++.h>
using namespace std;
int main()
{set<int> s;s.insert(8); //从尾部插入元素s.insert(1);s.insert(12);s.insert(6);s.insert(8); //重复的元素直接忽略//set<int>::iterator it;for (auto i = s.begin(); i != s.end();i++) {cout << *i<<" ";//指针i 输出对应的数据}cout << endl;std::vector<int> sVector(s.begin(), s.end());auto x = find(s.begin(), s.end(), 8);//这个x就相当于下标 他的类型是指针if (x != s.end()) {int ch =distance(s.begin(), x);cout << ch;}else {cout << "sb";}return 0;
}结果是
1 6 8 12
2
虽然没有必要这么写 但毕竟是我的突发奇想(8虽然是第三个数但下标要减一)
在一开始就对set这个容器有一个疑问就是你一放入一个变量他就自动给你从小到大进行排序 那我有什么方法能够不让他从小到大排 而按照我想要的方法进行排序呢?
当然有啦Ovo~~
对于一些内置数据进行排序
#include<bits/stdc++.h>
using namespace std;class x {
public:bool operator()(int x, int y)const{return x > y;}
};
int main()
{//内置数据改变sort原有排序 变成自己想要的顺序进行排序set<int,x> s;s.insert(10);s.insert(33);s.insert(25);s.insert(66);for (set<int,x>::iterator i = s.begin(); i != s.end(); i++) {cout << *i;}
}这样他输出的数据就是从大到小了
输出:
66 33 25 10
哎问题又来了 那如果我是结构体类型的数据应该如何操作呢?
方法如下:
#include<bits/stdc++.h>
using namespace std;struct pe {int name;int age;
};class x {
public:bool operator()(const pe &x, const pe &y)const{return x.age > y.age;}
};
int main()
{//内置数据改变sort原有排序 变成自己想要的顺序进行排序set<pe,x> s;for (int i = 0; i < 3; i++) {pe lm;cin >> lm.age>>lm.name;s.insert(lm);}for (auto it : s) {cout << it.age << " " << it.name << endl;}/*for (set<pe, x>::iterator it = s.begin(); it != s.end(); it++) {cout << it.age << " " << it.name << endl;}
}*/ //这个是错误的 系统自动报错O^o~~
(六)multiset
和set就差一个 multiset支持集合内的元素重复 而set是不允许元素重复 其他用法就不说了
(七)map
map<type,type>m;
对于内置数据赋值我们可以这样
map<int,int>m;
m.insert(pair<int,int>(1,10));
一些用法大差不差 具体情况等遇到题目再在解释那边细细描述
(由于写太多容器编者心态崩了 O.o)
近期遇到的有关stl的题目
(一)Where is the Marble?


代码详解
#include<bits/stdc++.h>
using namespace std;int main() {int n, m;int a[10000];//存放需要判断的数组int flag[10000];//判断该个数组是否被找到 int ans = 1;while (cin >> n >> m && m != 0 && n != 0) {cout << "CASE# " << ans << ":" << endl;vector<int >v;for (int i = 0; i < n; i++) {int x;cin >> x;v.push_back(x);//输入数据}for (int i = 0; i < m; i++) {cin >> a[i];flag[i] = 1;//赋值1}sort(v.begin(), v.end());for (int i = 0; i < m; i++) {for (auto it = v.begin(); it != v.end(); it++) {//双重循环//外循环是数组a[i]的数量 内循环是待寻找的数组 用了个vectorif (*it == a[i]) {//it是指针类型flag[i] = 0;//赋0 说明我做过了cout << a[i] << " " << "found at " << it - v.begin() + 1 << endl;//距离要加1break;}}if (flag[i] == 1) {//要还是1 那我就输出没有找到cout << a[i] << " not found" << endl;}}ans++;}
}
这个题目大致意思就是去寻找数据的位置 要明白一点就是我去寻找的那堆数据已经是排序过得 因此要先用个sort函数 其他就是比较正常的思维 这个题目其实用数组也能写 但毕竟学了新的知识点当然要用上了 不难算是水题
(二) Reversible
.


代码详解
#include<iostream>
#include<set>
#include<string>
using namespace std;int main() {long long n;cin >> n;set<string>s;for (int i = 0; i < n; i++) {string x;cin >> x;int lm = x.length();int j = 0;while (lm != 0) {if (x[j] > x[lm - 1]) {//我们想一致排序就是 小的字母永远在前面 那么就可以判断那些倒序字符串是否出现过reverse(x.begin(), x.end());//翻转字符串break;}else if (x[j] == x[lm - 1]) {//但是我们要思考一种情况就是 头和尾一模一样的时候 也就如abda adba 这两个数其实也是相同的 那么我们就继续进入循环 判断前面数据的后者和后面数据的前者就行 一直循环lm = lm - 1;j++;}else {break;}}s.insert(x);}cout << s.size();
}
这个题就小心相等的那种情况就行 一开始没注意到卡了很久 当你发现有这种特殊情况之后就很好写啦Ovo.
(三)单词数
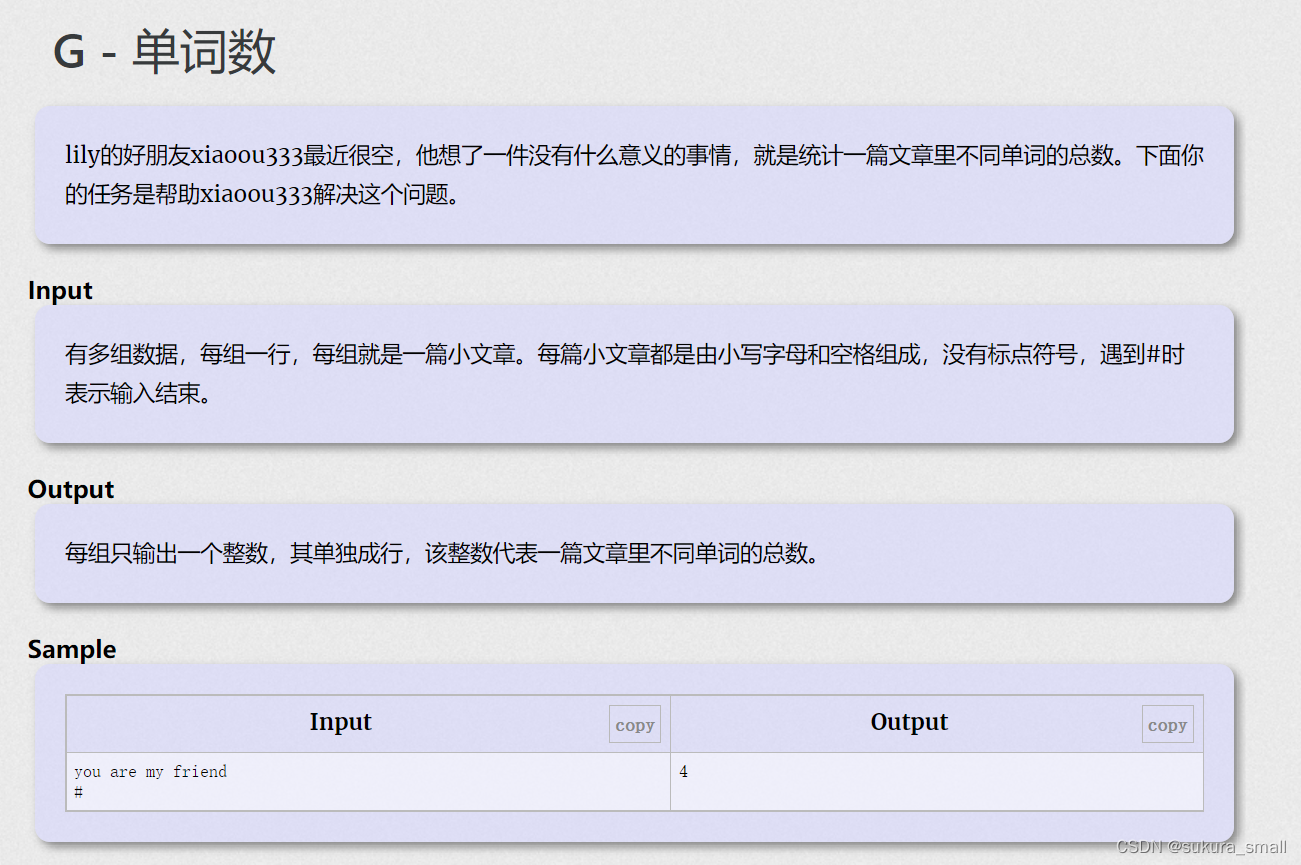
代码详解
#include<iostream>
#include<cstdio>
#include<set>
#include<sstream>
using namespace std;int main() {string s;set<string>x;while (getline(cin, s) && s != "#") {x.clear();//每次做之前先把之前存在容器里的数据删除istringstream str(s);//istringstream就相当于分割字符串的功能 它相当于自动把s这//么大长串的字符串按照空格分开存入一些数组里面string str2;while (str >> str2) {//就是给str2输入 当不能输入的时候自动退出x.insert(str2);//存入x容器 }cout << x.size() << endl;}
}
//我们这里就运用这个题目巧用了一个istringstream的这么一个函数 关于istringstream的用法可以参考别处的详解,(因为我本身还没有完全理解这个东东的用法) 一旦你懂了这个题目其实也挺好做的当然用其他方法(类似数组..)我想应该也是可以的 整体这个题理解起来不难
(四)ugly numbers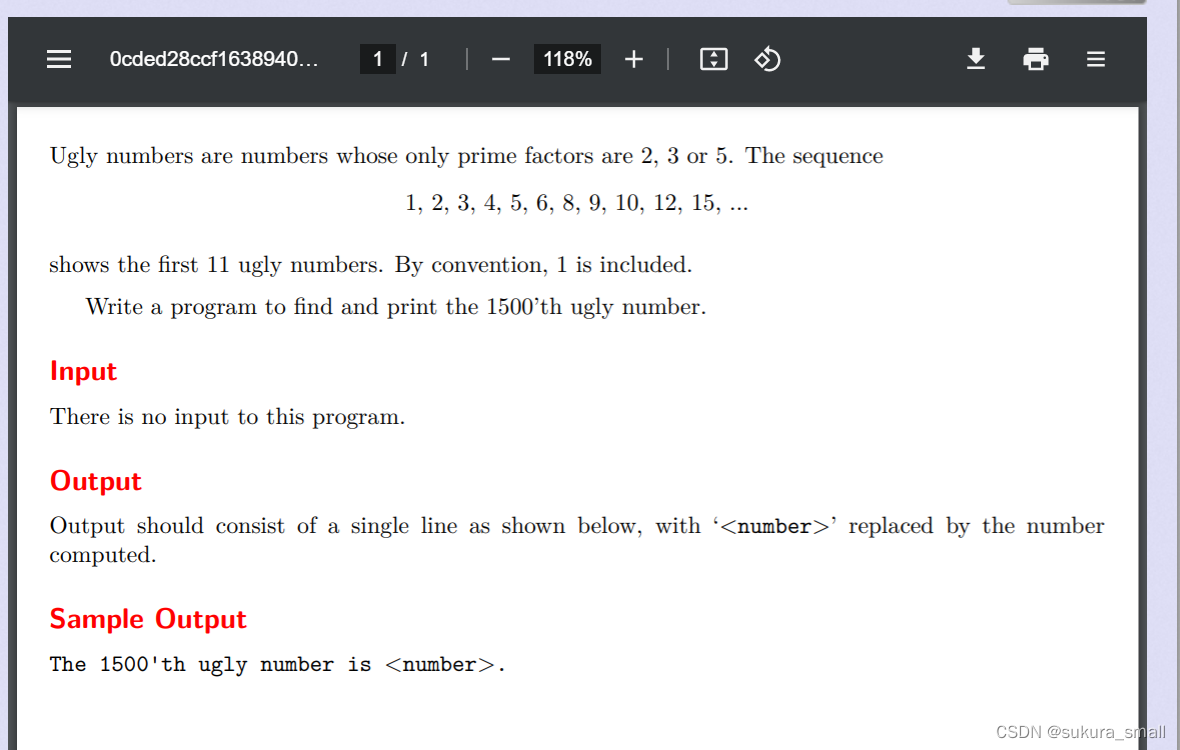
代码详解
#include <iostream>
#include <stdio.h>
#include <queue>
#include <set>
using namespace std;
int main()
{set<long long>s;s.insert(1);set<long long>::iterator it = s.begin();long long cont = 0;while (cont < 1500 - 1){long long now = *it;s.insert(now * 2);s.insert(now * 3);s.insert(now * 5);//上述的操作就是保证s里面的数据就是只乘2 3 5 其他跟235无关的数字统统踢掉//然后自动排序之后从大到小开始数 cont记录运行了几遍 it++;cont++;}cout << "The 1500'th ugly number is " << *it << "." << endl;return 0;
}这个题目只要思路想清楚,在set容器里只存2 3 5的倍数 然后一个一个数过去 因为set容器自动给我们排好序了 我们只需要一个一个找就行了
(五)Molar mass


代码详解
#include<iostream>
#include<string.h>
using namespace std;int main()
{int n;cin >> n;while (n--) {int a[26] = { 0 };int i = 0;string s;cin >> s;while (s[i] != '\0') {//判断是否取到字符串的尽头if (s[i] >= 'A' && s[i] <= 'Z') {//判断这时候取到的字符是 C||H||O||Nint k = s[i] - 'A';if (s[i + 1] >= '0' && s[i + 1] <= '9') {//这个时候判断后面的数字还是字母 //如果是字母那么自动在这个字母所对应的数组加一 如果后面是数字的话 那么去//判断后面有几位数字 接下来的操作就是取后面数字大小 int x = i + 1;int num = s[x] - '0';while (s[x + 1] >= '0' && s[x + 1] <= '9') {num = num * 10 + (s[x + 1] - '0');x++;}i = x - 1;a[k] = a[k] + num;}else {a[k]++;}}i++;}double ans = a[2] * 12.01 + a[7] * 1.008 + a[13] * 14.01 + a[14] * 16.00;printf("%.3f\n", ans);}
}
这是一个纯字符串问题 没有什么比较有难点的地方 照着思路写下来就行
(六)Digit Counting

代码详解
#include<bits/stdc++.h>
using namespace std;int main() {int x;cin >> x;while (x--) {int list[10] = { 0 };int n;cin >> n;for (int i = 1; i <= n; i++) {int lm = i;while (lm != 0) {int k = lm % 10;list[k]++;lm = lm / 10;//这个操作就是将n放到原有的数中间;}}for (int i = 0; i <= 9; i++){cout << list[i];//根据出现次数 结合下标依次记录if (i != 9) {cout << " ";}}for (int i = 0; i <= 9; i++) {list[i] = 0;//再重新赋值为0 用于下一轮数据}cout << endl;}
}这个题目如果你想到用数 也就是int类型来做,那么会很简单很快 但如果你想用字符串来做 就比如我一开始一样,那么就会陷入一个问题 我怎么将数据存进去 怎么将整数类型的数据转化为字符串当然看到的宝子们可以试一下 我是一直没有想清楚如何操作
这篇关于7.17~7.23周记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![机器学习周记(第三十三周:文献阅读[GWO-GART])2024.4.1~2024.4.7](https://img-blog.csdnimg.cn/direct/7d84f739a5654eecbdc9cbbd204db945.png)