本文主要是介绍The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文信息
标题:The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation
作者:Xiaoming Zhao, Harsh Agrawal
来源:ICCV
时间:2021
项目地址:https://xiaoming-zhao.github.io/projects/pointnav-vo/
Abstract
个人机器人可靠地导航到指定目标至关重要。为了研究这项任务,在模拟的 Embodied AI 环境中引入了 PointGoal 导航。
最近的进展在逼真的模拟环境中以近乎完美的精度(99.6% 的成功率)解决了 PointGoal 导航任务,假设无噪声的自我中心视觉、无噪声的驱动以及最重要的是完美的定位。然而,在视觉传感器和驱动的真实噪声模型下,并且无法访问“GPS 和指南针传感器”,PointGoal 导航的 99.6% 成功代理仅成功了 0.3%。在这项工作中,我们展示了视觉的令人惊讶的有效性在这种现实环境中执行 PointGoal 导航任务的里程计,即使用用于感知和驱动的现实噪声模型,并且无需访问 GPS 和指南针传感器。我们表明,将视觉里程计技术集成到导航策略中可以大幅提高流行的 Habitat PointNav 基准测试的最新水平,将成功率从 64.5% 提高到 71.7%,同时执行速度提高 6.4 倍
Introduction
Anderson 等人 [2] 提出了 PointGoal 导航的任务。在 PointGoal 导航中,代理在以前未见过的环境中随机生成,并且必须导航到相对于代理的初始位置和方向指定的点目标,例如,“相对于起点向北 5m,向西 3m”。代理使用离散的动作空间(例如,向前移动 0.25m,左转或右转 30㼿,然后停止)在环境中导航。在无噪声自我中心视觉(无噪声 RGB + 深度传感器)、无噪声驱动(例如,左转总是精确地转 30㼿)和使用 GPS+罗盘传感器完美定位的假设下,最近的方法解决了这个任务近乎完美的准确性(99.6%的成功)[53]。
然而,这些假设是不现实的。请注意,GPS 传感器通常无法在室内环境中提供精确位置。此外,真实机器人的感知和驱动通常在很大程度上取决于环境照明和表面摩擦系数。为了研究这种更真实的设置,在最近的基准测试2中,PointGoal 导航进行了更新,以包含来自真实机器人的噪声驱动模型 [35]。例如,对于单个左转动作,实际转动角度变化很大,如图 1 的第二列所示。此外,还结合了 [9] 中的 RGB 和深度噪声模型来模拟真实世界的相机。
最重要的是,如图 1 的第三列所示,代理无法访问 GPS+罗盘数据,并且必须仅基于以自我为中心的 RGB + 深度 (RGBD) 测量进行导航。在这样一个更现实的环境下,在无噪声场景下近乎完美的策略性能[53]急剧下降至 0.3%。在此基础上进行改进,现有最先进的技术[24]将粒子SLAM融入视觉导航中,并在如此真实的环境下实现了64.5%的成功率。与无噪声版本任务的 99.6% 成功率相比,具有噪声感知和驱动以及没有定位信息的导航仍然具有挑战性。
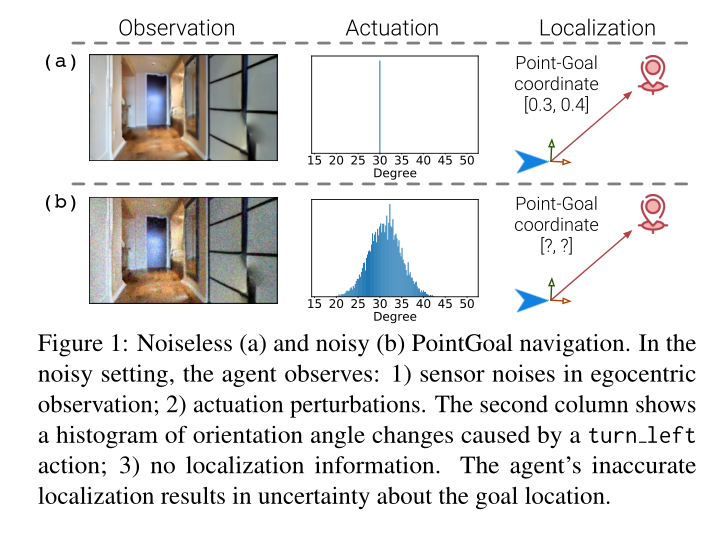
为了更好地理解这种现实环境中导航的挑战,我们研究了三种视觉里程计 (VO) 技术。我们发现这些 VO 技术对于这种现实环境中的 PointGoal 导航非常有效。
具体来说,我们
- 利用视觉里程计的几何不变性;
- 结合离散化和集成来防止噪声;
- 使用自上而下的深度信息正交投影作为附加信号。
对于 1),我们注意到给定观测值对的运动估计与排列观测值的运动估计相关。两个损失项促进了这种关系。
对于2),我们在视觉里程计模型的最后两层中研究Dropout [46],以防止自我运动预测中的不确定性,如[25]。我们还发现深度离散化是有效的。
对于 3),我们从每个单独步骤的深度信息推断出以自我为中心的自上而下的投影。我们发现这样一个简单的投影(对于每个步骤都是局部的)有利于自我运动估计。
重要的是,我们单独训练这个视觉里程计模型,而不是通过策略在线学习它。使用 VO 模型作为完美 GPS+指南针的直接替代品,可以重复使用通过完美定位信息(即使用 GPS+指南针传感器)学习到的导航策略,而无需进行任何昂贵的重新训练。
总而言之,我们研究了三种用于现实 PointGoal 导航的技术:
1)通过损失利用几何不变性;
2)结合离散化和集成;
3)使用自上而下的深度信息投影。
Related work
相机姿态估计和视觉里程计 (VO)。相机位姿估计与定位估计相关。例如,按照上述自我运动估计 [11],研究了直接使用卷积神经网络 (CNN) 来估计相对相机姿势 [59, 30]。这些模型通常不考虑鲁棒性。同时,在过去的几十年里,已经开发了许多针对 VO 的方法 [42, 14]。该流程通常由几个步骤组成,从相机校准、特征选择和匹配到根据对应关系进行运动估计、异常值检测和捆绑调整。最近,人们提出了各种基于深度学习的 VO 架构。例如,Wang 等人[49]提出了一种 CNN + 循环神经网络(RNN)来根据 RGB 输入估计室外环境中的 VO。由于室内导航中的三个连续帧几乎没有重叠,因此我们发现使用 RNN 进行顺序训练没有帮助。相比之下,我们使用更快的 ResNet18 [17] 架构从嘈杂的 RGB-D 输入对中学习 VO。 Wang 等人 [50] 利用刚性运动的数学群特性来学习用于户外导航的 VO 模型。同样,我们还在训练过程中利用几何不变性约束作为自我监督信号。此外,我们刻意利用使模型对观察噪声具有鲁棒性的表示。
为了模拟智能体对其自我运动预测的不确定性,Kendall 等人 [25] 在每个卷积层和倒数第二个线性层之后使用了 Dropout [46]。在测试时,他们的模型使用 40 个随机样本来获得自我姿态的稳健估计。当用作导航策略的输入时,模型在每个时间步的 40 次前向传递的成本极其昂贵。此外,由于 VO 模型的输入已经充满噪声,因此在 CNN 架构中添加 Dropout 几乎没有什么好处。相反,我们将 Dropout 添加到模型的最后两层,并通过缩放最后两层的参数来近似平均多个模型的预测的效果。这允许通过单次前向传播进行稳健估计
Approach
Overview
该模型如图 2 所示。PointGoal 导航 [2] 需要代理导航到点目标 v t g v^g_t vtg ,该目标是相对于代理在每个时间步 t 的当前位置指定的。第一次移动后,由于噪声,智能体仅具有相对位置的估计 v ^ t g \hat{v}^g_t v^tg 。
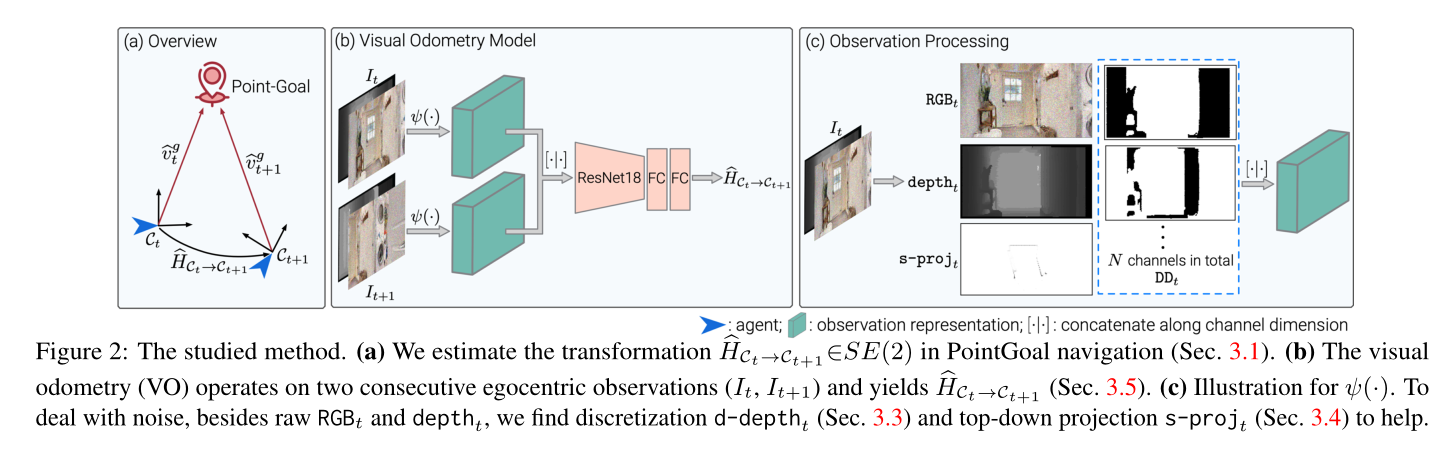
基于估计的相对坐标 v ^ t g \hat{v}^g_t v^tg 以及时间 t 之前的以自我为中心的观察结果 I ≤ t I_{\le t} I≤t(例如来自 RGB-D 传感器的测量结果),智能体选择实现目标的下一个动作。为此,代理计算动作空间 A = {向左转,向右转,… 的分布。 。 。 },即策略 π ( ⋅ ∣ v ^ t g , I ≤ t ) \pi(\cdot|\hat{v}^g_t,I_{\le t}) π(⋅∣v^tg,I≤t)。在 2 A 处执行操作后,智能体的位置和方向会发生变化。这会导致代理的局部坐标系从 C t C_t Ct 更改为 C t + 1 C_{t+1} Ct+1。坐标系 C t C_t Ct 中任意点的位置都可以使用变换 H C t → C t + 1 H_{C_t \rightarrow C_{t+1}} HCt→Ct+1 变换到坐标系 C t + 1 C_{t+1} Ct+1 的位置,这是 2D 平面刚性变换组的一个元素,即 SE(2)。这假设智能体的运动是平面的,这是成立的,因为情节是在单个楼层上定义的。请注意,如果需要,所有技术都可以轻松扩展到 SE(3)。
然而,变换 H C t → C t + 1 H_{C_t \rightarrow C_{t+1}} HCt→Ct+1 不可用,因为无法获得完美的位置变化测量。因此,我们需要根据智能体的自我中心观察来估计 H ^ C t → C t + 1 ∈ S E ( 2 ) \hat{H}_{C_t \rightarrow C_{t+1}}\in SE(2) H^Ct→Ct+1∈SE(2)。使用变换 bHCt!Ct+1,智能体根据其先前估计 bvg t 通过
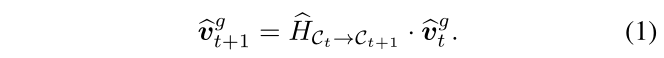
计算目标在时间 t + 1 时的相对位置。 ( 3.2 讨论了如何使用几何不变性从自我中心观察中估计变换 H C t → C t + 1 H_{C_t \rightarrow C_{t+1}} HCt→Ct+1。 3.3 解释了一种使视觉里程计模型对自我运动估计的不确定性具有鲁棒性的简单方法。 3.4 讨论了一种简单的方法,利用自我中心观察的自上而下的投影作为附加信号。 3.5 细节训练。
Geometrics Invariances for Visual Odemetry

注意,使用等式(3)中给出的损失。 对于学习 VO 模型的参数很常见,该模型通常表现出等式 (4) 中给出的结构。 例如,[49, 11]。然而,正如我们在第二节中所示。 4.3,如果不专门考虑感知和驱动噪声,纯回归效果不佳。接下来我们讨论稳健性改进。

总结:利用损失利用几何不变性就是转动的角度和平移要和真值一致,同时前一帧到当前帧的转移应该是可逆的,核心就是下面两个式子
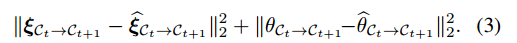
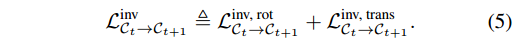
Robustness to Uncertainty
除了利用几何不变性之外,我们发现进一步提高模型 SE(2) 估计的稳健性也很重要。这很重要,因为测量存在噪声:1)即使相机位置和方向相同,由于观察噪声,视觉观察也会有所不同。这使得观测数据的处理变得脆弱; 2) 驱动中的扰动会影响 VO 模型的预测,因为它们会增加旋转和平移的方差。为了鲁棒性,我们使用两种经典技术:
Ensemble 集合。为了提高鲁棒性,可以训练一组模型。对整体的预测进行平均通常会减少方差。然而,基于强化学习(RL)的导航系统需要数十亿个样本来训练良好的策略[53]。由于该策略依赖于 VO 模型来提供代理的当前位置估计,因此提高推理速度并避免不必要的计算非常重要。因此,我们发现,在最后两个全连接 (FC) 层添加 Dropout [46] 的同时训练一个 CNN 架构,而不是集成多个模型,会很有帮助。这在经济上类似于训练大量集成的行为 [4, 18]。
在训练过程中,Dropout 以概率 p 随机禁用 FC 层中的隐藏单元,本质上是从子网络集合中采样。在推理过程中,FC 层中的每个隐藏单元都使用相同的因子 p 进行缩放,以模拟来自多个子网络的预测的平均值
Depth discretization 深度离散化。此外,我们发现深度离散化可以更稳健地表示距离传感器的自我中心观察。具体来说,使用 one-hot 编码将单通道深度图深度离散化为具有 N 个通道的表示 d 深度。给定图像坐标 (x, y) 处的深度像素,我们通过以下方式获得 d 深度的第 i 个通道的值

这不就是量化?
Top-Down Projection as Addional Signal
直观上,地图应该进一步提高模型的稳健性。然而,我们设置中的关键挑战是:深度传感器中的噪声相当微妙,而且通常几乎不可见(见图 3(a,d))。但一旦投影到 2D 布局,噪声就会表现为严重偏差、孔洞和堵塞,如图 3(b,e) 所示。为了应对这一挑战,我们使用归一化软投影。归一化软投影 s-projt,如图 3(c,f)所示,类似于深度图给出的房间布局。请注意,它们也比图 3(b,e) 中给出的投影有更多相似之处。
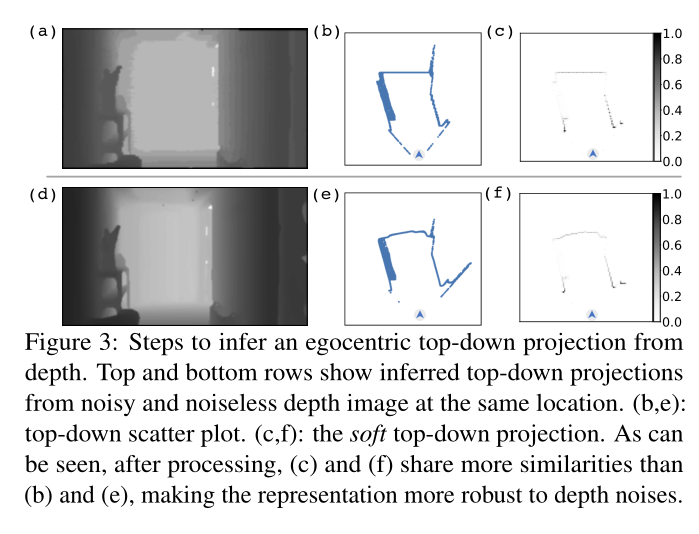
我们通过以下方式获得软投影:
- 将深度观测值映射到 3D 点云,
- 使用 2D 自上而下的正交投影,
- 根据每个像素内的点数对投影进行归一化。
VO Model Architecture,Training Details , and Integration with Navigation Policy

Navigation policy training。我们工作的重点是现实条件下的 PointGoal 导航,即嘈杂的观察和驱动以及无法访问 GPU+Compass 传感器。为了证明 VO 技术可以作为地面实况 GPS+罗盘传感器的简单替代品,我们直接使用[53]中的导航策略。
具体来说,导航策略⇡由 2 层 LSTM [19] 组成,并使用 ResNet-18 [17] 主干来处理视觉观察。该策略的学习独立于视觉里程计模型,并且可以访问完美的位置数据。在训练期间,在每个时间步 t,策略 ⇡ 对以自我为中心的观察 I ≤ t I_{\le t} I≤t、地面实况点目标 v t g v^g_t vtg 以及先验动作 a ≤ t − 1 a \le t-1 a≤t−1 进行操作,并计算动作空间 A 上的分布。学习我们使用 DD-PPO [53] 的策略,它是 PPO [44] 的分布式版本。我们使用相同的一组超参数和奖励塑造设置[53],我们将在附录中对此进行更多讨论。
Visual odometry for navigation。在推理过程中,在每个时间 t + 1 t + 1 t+1,智能体都会获得以自我为中心的观察 I t + 1 I_{t+1} It+1。
与之前的以自我为中心的观察 It 一起,VO 模型 f ϕ f_{\phi} fϕ 使用方程式计算 SE(2) 估计 H ^ C t → C t + 1 \hat{H}_{C_t \rightarrow C_{t+1}} H^Ct→Ct+1。 (4)。给定前一时间 t 的相对位置估计 v ^ t g \hat{v}^g_t v^tg,智能体通过等式更新当前估计 v ^ t + 1 g \hat{v}^g_{t+1} v^t+1g。 (1) 并将其用作政策输入。
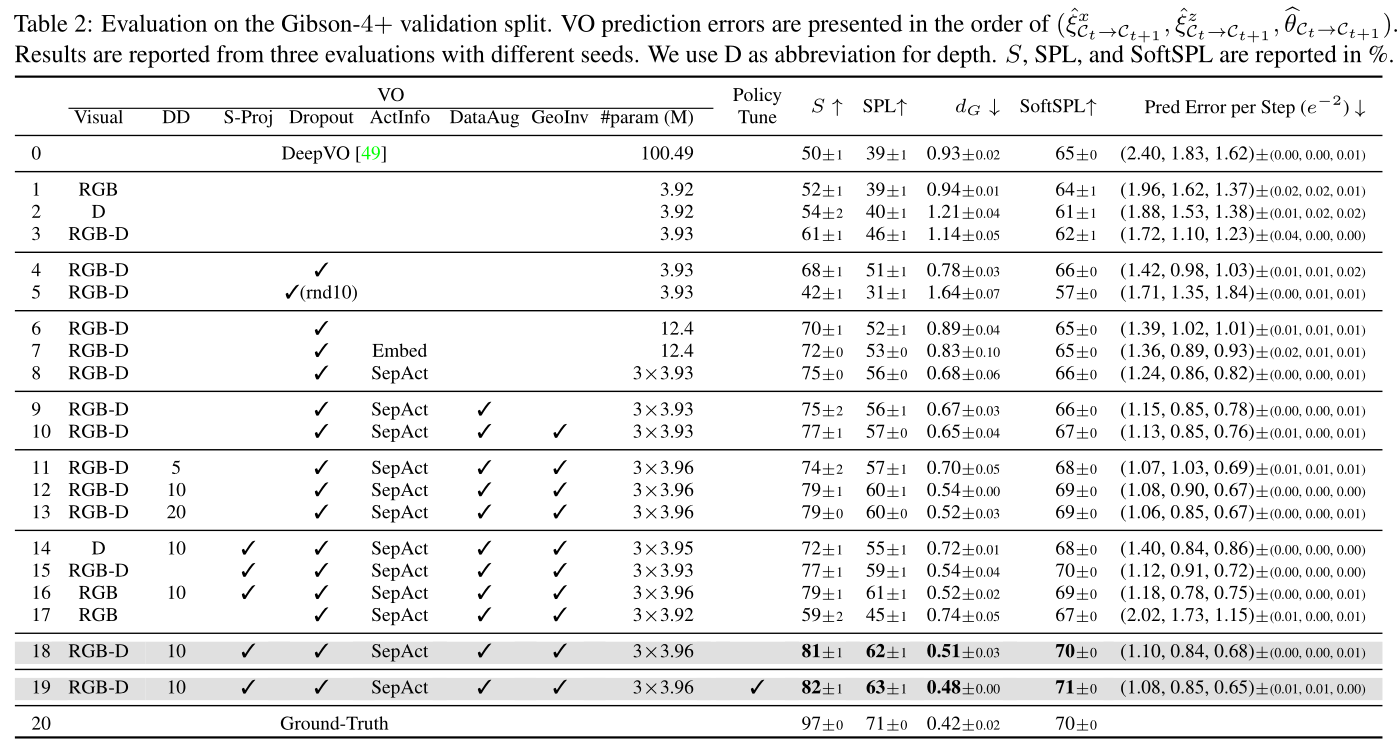
Experiments
这篇关于The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)