本文主要是介绍LongAdder为什么在高并发下保持良好性能?LongAdder源码详细分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、LongAdder概述
- 1、为什么用LongAdder
- 2、LongAdder使用
- 3、LongAdder继承关系图
- 4、总述:LongAdder为什么这么快
- 5、基本原理
- 二、Striped64源码分析
- 1、Striped64重要概念
- 2、Striped64常用变量或方法
- 3、静态代码块初始化UNSAFE
- 4、casBase方法
- 5、casCellsBusy方法
- 6、getProbe方法
- 7、longAccumulate方法
- 三、深入分析LongAdder的核心add方法
- 1、单线程更新LongAdder的值
- 2、多线程竞争创建cells数组
- 3、有了Cells之后,再次进行add
- 4、总结
- 四、LongAdder的sum方法求和
- 参考资料
一、LongAdder概述
1、为什么用LongAdder
《阿里巴巴Java开发手册中》:
【参考】 volatile 解决多线程内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,同样无法解决线程安全问题。
说明: 如果是 count++操作,使用如下类实现: AtomicInteger count = new AtomicInteger();
count.addAndGet(1); 如果是 JDK8,推荐使用 LongAdder 对象,比 AtomicLong 性能更好(减少乐观锁的重试次数)。
在低并发下,LongAdder和AtomicLong具有相似的特征。但在高并发下,LongAdder的预期吞吐量要高得多,但代价是空间消耗更高。
2、LongAdder使用
Java-Atomic原子操作类详解及源码分析,Java原子操作类进阶,LongAdder源码分析
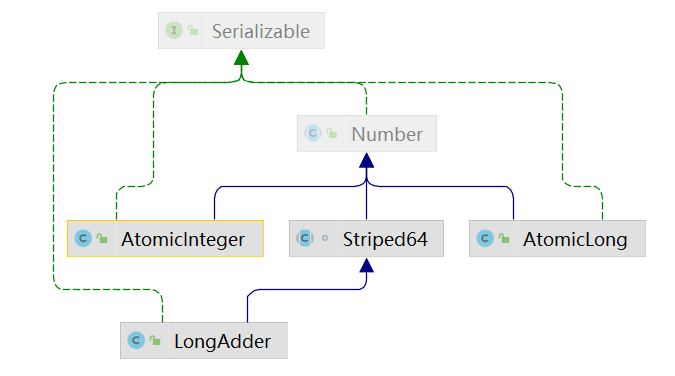
3、LongAdder继承关系图
LongAdder继承了Striped64,而Striped64同样也是JUC包下一员。LongAdder有着这么特殊的特性,是离不开Striped64的。
4、总述:LongAdder为什么这么快
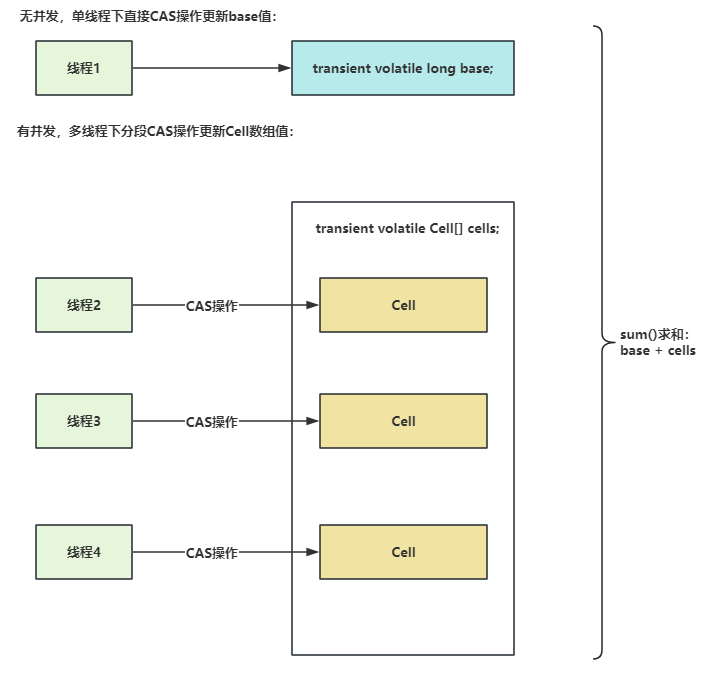
LongAdder的基本思路就是分散热点,将value值分散到一个Cell数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
sum()会将所有Cell数组中的value和base累加作为返回值,核心的思想就是将之前的AtomicLong一个value的更新压力分散到多个value中区,从而降级更新热点。
这也是“分段锁”的实现思想。
5、基本原理
LongAdder在无竞争的情况,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则是采用分散热点的做法,用空间换时间,用一个数组cells,将一个value拆分进这个数组cells。多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和base都加起来作为最终结果。(注:多个线程是有可能操作同一个cell的,因为其hash映射有可能相同)
二、Striped64源码分析
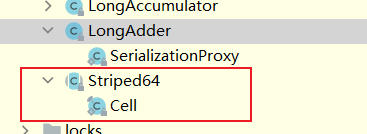
1、Striped64重要概念
2、Striped64常用变量或方法
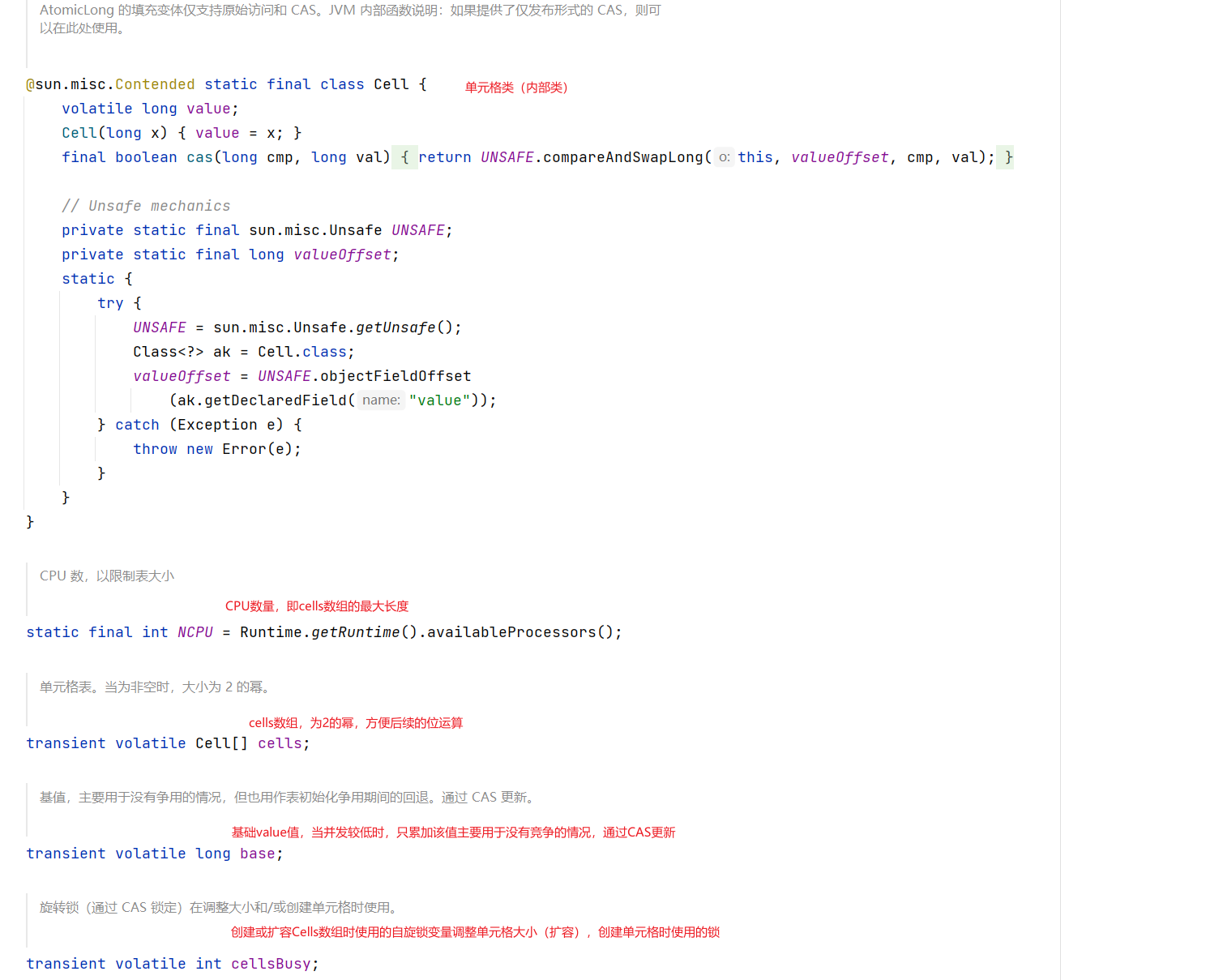
base:类似于AtomicLong中全局的value值,在没有竞争情况下数据直接累加到base上,或者cells扩容时,也需要将数据写入到base上。
collide:表示扩容意向,false一定不会扩容,true可能扩容。
cellsBusy:初始化cells或者扩容cells需要获取锁,0表示无所状态,1表示其他线程已经持有了锁。
casCellsBusy():通过CAS操作修改cellsBusy的值,CAS成功表示获取锁,返回true。
NCPU:当前计算机CPU数量,Cell数组扩容时会使用到。
getProbe():获取当前线程的hash值。
advanceProbe():重置当前线程的hash值。
3、静态代码块初始化UNSAFE
下面的源码中我们可以看出,Striped64在静态代码块中初始化了Unsafe类,并且初始化了Unsafe类的对于对象属性的更新,其中包括base、cellsBusy、threadLocalRandomProbe,用于线程安全的更新Striped64的属性。
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long BASE;
private static final long CELLSBUSY;
private static final long PROBE;
static {try {UNSAFE = sun.misc.Unsafe.getUnsafe();Class<?> sk = Striped64.class;BASE = UNSAFE.objectFieldOffset(sk.getDeclaredField("base"));CELLSBUSY = UNSAFE.objectFieldOffset(sk.getDeclaredField("cellsBusy"));Class<?> tk = Thread.class;PROBE = UNSAFE.objectFieldOffset(tk.getDeclaredField("threadLocalRandomProbe"));} catch (Exception e) {throw new Error(e);}
}
4、casBase方法
casBase用于CAS更新base字段,通过预期值来更新Striped64中的base字段:
// java.util.concurrent.atomic.Striped64#casBase
finalboolean casBase(long cmp, long val) {return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}
5、casCellsBusy方法
casCellsBusy():通过CAS操作修改cellsBusy的值,CAS成功表示获取锁,返回true。
// java.util.concurrent.atomic.Striped64#casCellsBusy
final boolean casCellsBusy() {return UNSAFE.compareAndSwapInt(this, CELLSBUSY, 0, 1);
}
6、getProbe方法
该方法获取线程的hash值(probe值)
static final int getProbe() {return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
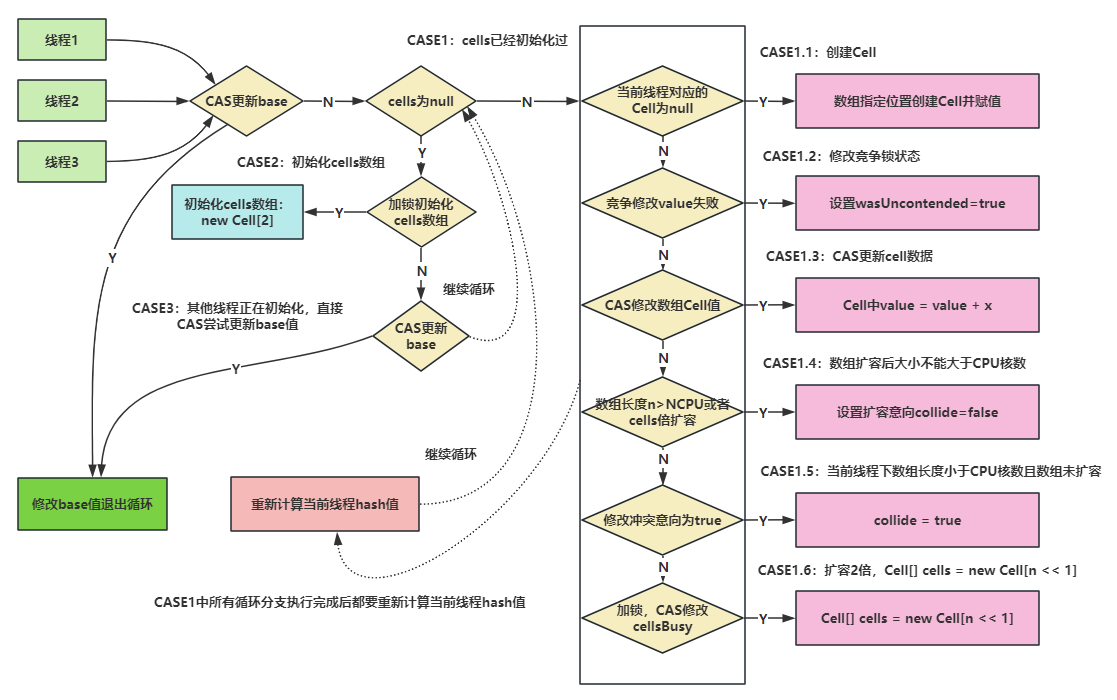
7、longAccumulate方法
final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended) {// 存储线程的probe值int h;// 如果getProbe() 为0 ,说明随机数未初始化(极端情况)if ((h = getProbe()) == 0) {// 使用ThreadLocalRandom 为当前线程重新计算一个hash值,强制初始化ThreadLocalRandom.current(); // force initialization// 重新获取probe值, hash值被重置就好比一个全新的线程一样,所以设置了wasUncontended竞争状态为trueh = getProbe();// 重新计算了当前线程的hash后,认为此次不算是一次竞争,都未初始化,肯定还不存在竞争激烈,wasUncontended竞争状态设为truewasUncontended = true;}boolean collide = false; // True if last slot nonempty// 自选,共分三个分支for (;;) {Cell[] as; Cell a; int n; long v;// CASE1:表示cells数组已经被初始化了if ((as = cells) != null && (n = as.length) > 0) {// ...}// CASE2:cells数组没有加锁且没有初始化,则尝试对它进行加锁,并初始化else if (cellsBusy == 0 && cells == as && casCellsBusy()) {// ...}// CASE3:兜底,cells正在初始化,则尝试直接在基数base上进行累加else if (casBase(v = base, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break; // Fall back on using base}
}
三、深入分析LongAdder的核心add方法
1、单线程更新LongAdder的值
// java.util.concurrent.atomic.LongAdder#add
public void add(long x) {/**as表示cells(Striped64的cells数组)的引用;b表示获取的Striped64的base属性;v表示当前线程hash到Cell中存储的值;m表示cells数组的长度-1,hash时作为掩码使用;a表示当前线程命中的cell单元格*/Cell[] as; long b, v; int m; Cell a;// cells是Striped64中的cells,初始是null// 当没有线程竞争时,casBase方法更新base值,是可以更新成功的,if条件不成立,方法执行完成if ((as = cells) != null || !casBase(b = base, b + x)) {boolean uncontended = true;if (as == null || (m = as.length - 1) < 0 ||(a = as[getProbe() & m]) == null ||!(uncontended = a.cas(v = a.value, v + x)))longAccumulate(x, null, uncontended);}
}
上面我们分析到,当单线程更新LongAdder的值时,由于没有线程竞争,直接通过cas更新base的值,更新成功后方法直接结束。
2、多线程竞争创建cells数组
public void add(long x) {Cell[] as; long b, v; int m; Cell a;// 当多个线程执行casBase时,会有可能cas失败,此时就进入if逻辑if ((as = cells) != null || !casBase(b = base, b + x)) {// uncontended默认为true,无竞争,false表示竞争激烈,多个线程hash到同一个Cell,可能要扩容boolean uncontended = true;// 首次进来时,as为null,进入longAccumulate方法if (as == null || (m = as.length - 1) < 0 ||(a = as[getProbe() & m]) == null ||!(uncontended = a.cas(v = a.value, v + x)))longAccumulate(x, null, uncontended);}
}
longAccumulate方法较长,for(;;)中,有个if:
if ((as = cells) != null && (n = as.length) > 0) {
// ...// CASE2:cells数组没有加锁且没有初始化,则尝试对它进行加锁,并初始化
// cellsBusy初始就是0, cells == as == null,并且casCellsBusy拿到锁定
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {boolean init = false;try { // Initialize tableif (cells == as) { // 双重检查,保证线程安全// 创建Cell[2]数组Cell[] rs = new Cell[2];// 计算下标,初始化一个cell,初始值为xrs[h & 1] = new Cell(x);cells = rs;init = true;}} finally {cellsBusy = 0;}if (init)break;
}
到此,我们知道,当有线程cas竞争之后,会初始化2个长度的Cell数组,并创建一个Cell。
3、有了Cells之后,再次进行add
public void add(long x) {Cell[] as; long b, v; int m; Cell a;// cells 不再为null了,而是2个长度的Cell数组if ((as = cells) != null || !casBase(b = base, b + x)) {boolean uncontended = true;// as 不为null// as.length 为2 (m = as.length - 1) < 0也不成立,正常不会成立,相当于as == null的兜底// as[getProbe() & m]) 表示cells数组的该槽位为null,还没初始化,就会执行longAccumulate初始化一个Cell// 如果上述还不成立,a.cas(v = a.value, v + x) 直接执行Cell中的value的cas操作,如果成功就退出,如果cas失败就执行longAccumulate,并且将cas的结果赋值给uncontendedif (as == null || (m = as.length - 1) < 0 ||(a = as[getProbe() & m]) == null ||!(uncontended = a.cas(v = a.value, v + x)))longAccumulate(x, null, uncontended);}
}
for (;;) {Cell[] as; Cell a; int n; long v;// CASE1:cells已经被初始化了if ((as = cells) != null && (n = as.length) > 0) {// if总结:判断当前线程hash后指向的数据位置元素是否为空,为空则将Cell数据放入数组跳出循环,不为空则继续循环if ((a = as[(n - 1) & h]) == null) { // 当前线程的hash值运算后映射得到的Cell单元为null,说明该Cell没有被使用if (cellsBusy == 0) { // Try to attach new Cell Cell[]数组没有正在扩容(没有锁)Cell r = new Cell(x); // Optimistically create 创建一个Cell单元if (cellsBusy == 0 && casCellsBusy()) { // 尝试加锁,成功后cellsBusy == 1boolean created = false;try { // Recheck under lock 在有锁的情况下再进行一次检查Cell[] rs; int m, j; // 将Cell单元附到Cell[]数组if ((rs = cells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {rs[j] = r;created = true;}} finally {cellsBusy = 0;}if (created)break;continue; // Slot is now non-empty}}collide = false;}// wasUncontended表示cells初始化后,当前线程竞争修改失败// 若wasUncontended = false,这里只是重新设置了这个值为true,紧接着执行advanceProbe(h)重置当前线程hash,重新循环else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehash// 说明当前线程对应的数组中有了数据,也重置过hash值,这时通过CAS操作尝试对当前数中的value值进行累加x操作,如果CAS成功则直接跳出循环else if (a.cas(v = a.value, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break;// 如果n大于CPU最大容量,不可扩容,紧接着执行advanceProbe(h)重置当前线程hash,重新循环else if (n >= NCPU || cells != as)collide = false; // At max size or stale// 如果扩容意向collide是false,则修改它为true,然后执行advanceProbe(h)重置当前线程hash,重新循环// 如果当前数组长度已经大于了CPU核数,就会再次设置扩容意向collide = false (见上一步)else if (!collide)collide = true;// 加锁、扩容else if (cellsBusy == 0 && casCellsBusy()) {try { // 当前的cells数组和最先赋值的as是同一个,表示没有被其他线程扩容过if (cells == as) { // Expand table unless staleCell[] rs = new Cell[n << 1]; // 按位左移1位,扩容大小为之前容量的2倍for (int i = 0; i < n; ++i)rs[i] = as[i]; // 扩容后再将之前数组的元素拷贝到新数组cells = rs;}} finally {cellsBusy = 0; // 释放锁}collide = false; // 设置扩容状态,继续循环continue; // Retry with expanded table}// 兜底:重置当前线程的hash,重新循环h = advanceProbe(h);}else if (cellsBusy == 0 && cells == as && casCellsBusy()) {// ...
4、总结
四、LongAdder的sum方法求和
sum()会将所有Cell数组中的value和base累加作为返回值。在没有并发更新的情况下调用将返回准确的结果,但在计算总和时发生的并发更新可能不会合并。
sum执行时,并没有限制对base和cells的更新。所以LongAdder不是强一致性的,它是最终一致性的。
首先,最终返回的sum局部变量,初始被赋值为base,而最终返回时,很可能base已经被更新了,而此时局部变量sum不会更新,造成不一致。其次,这里对cell的读取页无法保证是最后一次写入的值。所以,sum方法在没有并发的情况下,可以获得正确的结果。
public long sum() {Cell[] as = cells; Cell a;long sum = base; if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value; // base + 所有cell中的value}}return sum;
}
参考资料
https://zxbcw.cn/post/214652/
这篇关于LongAdder为什么在高并发下保持良好性能?LongAdder源码详细分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





