本文主要是介绍自监督、对比学习、contrastive learning、互信息、infoNCE等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
===== 更新时间:21.2.7 祝大家节日快乐 ============
73岁Hinton老爷子构思下一代神经网络:属于无监督对比学习
无监督学习主要有两类方法(所以在label少的时候,unsupervised learning可以帮助我们学到data本身的high-level information,这些information能够对 downstream task有很大的帮助。)
第一类的典型代表是 BERT 和变分自编码器(VAE),它们使用深度神经网络重建输入。但这类方法无法很好地处理图像问题,因为网络最深层需要编码图像的细节。
另一类方法由 Becker 和 Hinton 于 1992 年提出,即对一个深度神经网络训练两个副本,这样在二者的输入是同一图像的两个不同剪裁版本时,它们可以生成具备高度互信息的输出向量。这类方法的设计初衷是,使表征脱离输入的不相关细节。
NLP 里的无监督:语境信息对 BERT 非常重要,它利用遮蔽语言模型(masked language model,MLM)允许表征融合左右两侧的语境,从而预训练深度双向 Transformer。 Hinton 举了一个例子:「She scromed him with the frying pan」。在这个句子中,即使你不知道 scromed 的意思,也可以根据上下文语境进行推断。
视觉领域也是如此。然而,BERT 这类方法无法很好地应用到视觉领域,因为网络最深层需要编码图像的细节
Becker 和 Hinton 提出最大化互信息方法——可以尝试不再解释感官输入(sensory input)的每个细节,而专注于提取空间或时序一致性的特征(原来x和编码后的x 特征一致,最重要的特征保留了下来,忽略无关紧要的信息)
首先需要理解 互信息 ,因为只有知道了,我们需要加大什么互信息,才能更好的设计正负样本,从而利用对比学习来设计任务提高。互信息可以看做加强版的 correlation,correlation 只能反映变量之间的线性关系,但是互信息可以进一步反映变量之间的非线性关系;这一点在量化金融里面也非常有用
对比学习只是加大互信息的其中一种方式而已。infoNCE也是其中一种loss
更新理解:参考文献
作者的个人理解,其实任意挖掘对象之间联系、探索不同对象共同本质的方法,都或多或少算是自监督学习的思想。原始的监督学习、无监督学习,都被目所能及的一切所约束住,无法泛化,导致任务效果无法提升,正是因为自监督探索的是更本质的联系,而不是表像的结果,所以其效果通常出乎意料的好。自监督学习的前两类方法,其核心想法其实都是想去探索事物的本质。
参考资料
On Mutual Information Maximization
设计
对比学习(Contrastive Learning)相关进展梳理
互信息 [苏神]
互信息的概念大家都不陌生,它基于香农熵,衡量了两个随机变量间的依赖程度。而不同于普通的相似性度量方法,互信息可以捕捉到变量间非线性的统计相关性,因而可以认为其能度量真实的依赖性
好特征的基本原则应当是“能够从整个数据集中辨别出该样本出来”,也就是说,提取出该样本(最)独特的信息(表示学习算法并不一定要关注到样本的每一个细节,只要学到的特征能够使其和其他样本区别开来就行)如何衡量提取出来的信息是该样本独特的呢?我们用“互信息”来衡量。就是说 你是一个女人并不能很好从一堆人中知道你,但是你很爱学习,长相的特点区别其他人,姓名等独特的信息。就能把你进行编码,和其他人的编码区分出来。或者身份证也是这个信息。这个信息在计算机中叫 互信息。
互信息是一个非常重要的指标,它衡量了两个东西的本质相关性,你看那些 表示学习 pretrain得到的编码信息。就是为了用这些信息来操控下游任务。因为物体在表示上面都已经不同了,下游任务相对负担就少了,更容易的解决下游任务(很多研究者认为,深度学习的本质就是做两件事情:Representation Learning(表示学习)和 Inductive Bias Learning(归纳偏好学习)。目前的一个趋势就是,学好了样本的表示,在一些不涉及逻辑、推理等的问题上,例如判断句子的情感极性、识别图像中有哪些东西,AI 系统都可以完成非常不错;而涉及到更高层的语义、组合逻辑,则需要设计一些过程来辅助 AI 系统去分解复杂的任务,ICLR 19 的一篇 oral 就是做的类似的事情。因为归纳偏好的设计更多的是 任务相关的,复杂的过程需要非常精心的设计,所以很多工作都开始关注到表示学习上,NLP 最近大火的预训练模型,例如 BERT,就是利用大规模的语料预训练得到文本的好的表示。那么,CV 领域的 BERT 是什么呢?答案已经呼之欲出,就是对比学习---参考)
参考1 wordvec
所以我们任务的互信息是什么非常重要,必须弄懂互信息才能很好的进行任务的设计。
举例子:利用典型的论文分析
一般对比学习的 loss 都是 infoNCE那个(自己查)。
Contrastive Predictive Coding : 这篇论文的锚点数据x是现在的表示,x+样本是未来的。互信息是希望现在的表示和未来的大体一致,比如语音是统一个人,视频是统一动作,图像是同一物体等。所以要加大这个表示的相近,优化目标就是编码函数 或编码器 f 使得互信息更大。
DIM旨在最大化一个图像的局部和整体表示向量的互信息
这篇文章说得很好,就其实对比学习就是在一个加大互信息的。
对比学习
对比学习的loss 为
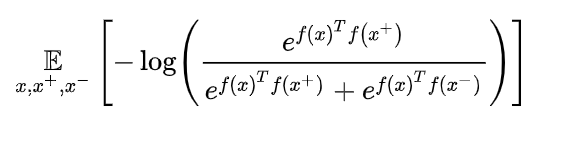
最小化这一 loss 能够最大化 锚点数据 和 正样本 互信息的下界,加大互信息,学习是学习f函数
怎么 样设计正负样本呢?最好能覆盖所有的关系,这种看你的设计把,是预训练表示?还是基于任务的。
参考文章---这篇挺好的。
然后据说 负样本越多效果越好,但是多了就效率又降低了。不过都有相关论文,这个自己查把。感觉到处是hhh
自监督写的好的
基本总结完了。看看后面我看论文的程度把。
科研好难,但是还是要加油..>.<
ps: 点个赞吧嘤嘤嘤╥﹏╥...
欢迎私戳进阶版本
这篇关于自监督、对比学习、contrastive learning、互信息、infoNCE等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



