本文主要是介绍YOLOv5、YOLOv8改进:SEAttention 通道注意力机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
简介
SE 通道注意力机制
2.1 SE 通道注意力机制的定义与作用
2.2 SE过程: Squeeze + Excitation + Scale
3.YOLOV5改进
3.1首先common加入以下代码
3.2在yolo.py中进行注册
3.3yaml文件的配置,以yolov5s为参照
简介
SENet是2017年ImageNet比赛的冠军,2018年CVPR引用量第一
基于通道的注意力机制 源自于 CVPR2018: Squeeze-and-Excitation Networks
官方代码:GitHub - hujie-frank/SENet: Squeeze-and-Excitation Networks
较早的将attention引入到CNN中,模块化化设计。
SE模块的主要操作:挤压(Squeeze)、激励(Excitation
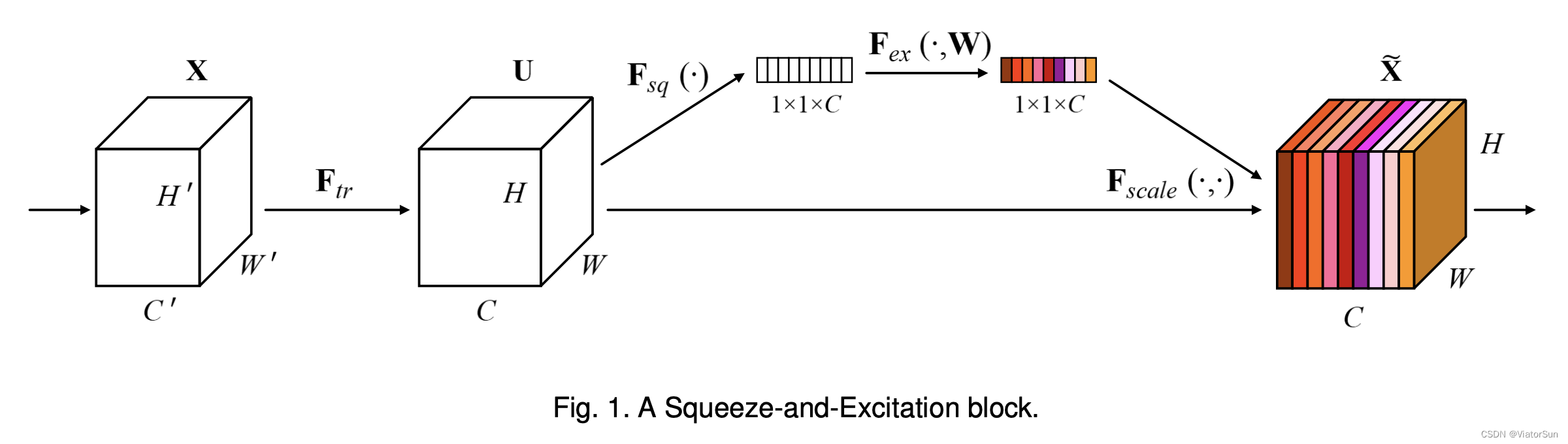
如图所示,其实就是将不同的通道赋予相关的权重。Attention机制用到这里用朴素的话说就是,把重要的通道赋予大的权重,然后将这些通道以及权重去线性组合。
至于这个权重是自己"学习"的。具体这样做,把每一个通道先下采样为一个实数,然后再通过两层全连接层,就会得到每个通道的权重。在训练构成中,这两个全连接层的参数也会和模型其他可训练参数一样一起更新。
SE模块是一个即插即用的模块,在上图中左边是在一个卷积模块之后直接插入SE模块,右边是在ResNet结构中添加了SE模块。

SE 通道注意力机制
2.1 SE 通道注意力机制的定义与作用
SE注意力机制,通过自动学习的方式,使用另外一个新的神经网络,获取到特征图的每个通道的重要程度,并赋值权重,从而让神经网络关注权重高的特征通道。
作用为,提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道。同时,全连接FC网络根据loss损失来自动学习特征权重。
2.2 SE过程: Squeeze + Excitation + Scale
SE :Squeeze + Excitation + Scale
① 压缩Squeeze
通过平均池化,将特征图合并压缩,从 H × W × channel,变为 1 × 1 × channel,后者的一个1×1就获得了原始特征图中 H × W 的感受野,
② 激发Excitation
进行FC全连接,每个通道都生成一个权值,并归一化,同时也是 1 × 1 × channel
③ 还原Scale
将原始图像乘以权值矩阵,[h,w,c]×[1,1,c] ==> [h,w,c]
3.YOLOV5改进
3.1首先common加入以下代码
class SEAttention(nn.Module):def __init__(self, channel=512,reduction=16):super().__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)3.2在yolo.py中进行注册
你准备的注意力机制都可以放在这里面
elif m in [S2Attention, SimSPPF, ACmix, CrissCrossAttention, SOCA, ShuffleAttention, SEAttention, SimAM, SKAttention]:3.3yaml文件的配置,以yolov5s为参照
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[-1, 1, SEAttention, [1024]],[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]以上就是完整的改法
YOLOv8和YOLOv5都是一个作者,common变成了conv yolo变成了task 其他都一样
这篇关于YOLOv5、YOLOv8改进:SEAttention 通道注意力机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




