本文主要是介绍利用PS进行墙面、道路、大坝、隧道等各种裂缝分割数据的高效标注——超详细,超实用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、为什么选择用ps进行标注
1、Labelme:
2、精灵标注助手:
3、PS
二、ps安装教程
三、标注步骤:
四、对标签进行二值化处理:
一、为什么选择用ps进行标注
结合我在各大学习平台搜索的资料,进行裂缝分割数据的标注,一般有三个软件,分别是Labelme,精灵标注助手还有ps。总结了这三款标注软件的优缺点如下:
1、Labelme:
优缺点:
1、环境配置及安装复杂
2、标注后的数据需要进行批量的Json文件转化。
3、标注数据精度较高,操作较简单
4、数据量大时有时会闪退,打开比较麻烦
2、精灵标注助手:
优缺点:
1、操作简单便捷。
2、只有一个涂抹工具可以用,要不断调整涂抹范围大小,非常繁琐。
3、标错后只能利用擦除工具进行擦除。
4、标注的道路裂缝的颜色只能通过修改标注信息名称来修改,不能指定颜色。
5、标注精度不高。
3、PS
优缺点:
1、标注精度较高,可达像素级。
2、操作较简单
3、占用内存大,不能同时打开多张图进行标注,容易卡
总体来说效果较好
从上述分析可知,ps的操作更加的灵活,而且标注的精度更高,省去了标注后的数据需要进行批量的Json文件转化的繁琐操作,达到了像素级标注的要求,实现了像素级分割。经过本人的大量实验总结出了以下标注步骤。
二、ps安装教程
Photoshop以其强悍的编辑和调整、绘图等功能得到广泛应用,各种图片的调整和图画绘制以及图像的修复、调色等工具数不胜数,从照片修饰到海报、包装、横幅的制作以及照片的处理,只要你想得到,总能在这里实现!丰富的预设让你的工作更加轻松。
【地址】链接:
https://pan.baidu.com/s/1ivtspC_QCjU0JBzaPwfenQ
提取码:cq4k
【操作系统】 64位
【安装环境】 Win10
【安装步骤】【软件】Photoshop 2022软件下载及安装教程
三、标注步骤:
1、将其他应用关闭,只打开PS软件,因为PS软件占用内存较大,容易卡或者出现功能异常
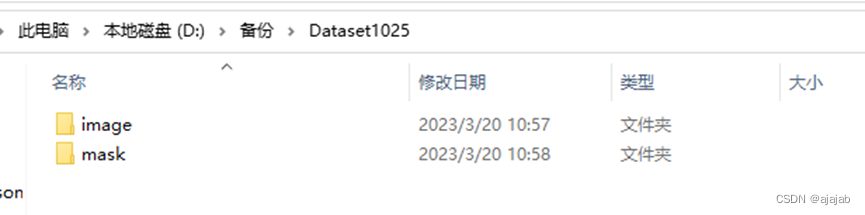
2、新建文件夹如图所示,新建一个以数据名命名的文件夹,然后再建下图两个文件夹,将需要标注的数据放入image中,mask文件夹保存最后的标注结果(现在为空)。
3、打开需要标注的图片
直接点击打开,或者点击文件--打开。一次建议打开5张图片,多的话PS容易闪退
打开后如图所示:

使用alt+鼠标滚轮可以对图片进行缩放。
4、选中背景图层,依次点击图像—自动对比度,对图片设置更高的对比度,便于分割裂缝。

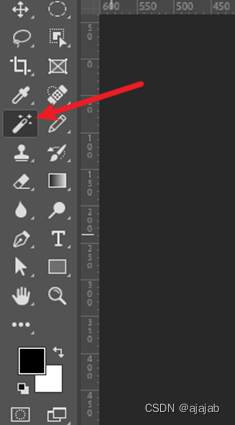
5、选择魔棒工具,特别注意使用魔棒工具之前要把取样大小设置为取样点,并把消除锯齿前面的勾去掉!!!!这点一定要注意,不然的话抠出的图就会有问题。

6、按Alt+鼠标滚轮将图片放大至像素级,点击魔棒工具后再点击需要扣出的裂缝区域。点击一下鼠标左键只能选择一小块裂缝,想要继续选择更长更完整的裂缝,需要按住shift键再点击鼠标左键。如果标错了想要取消之前选中的裂缝,只需要按住Alt键再点击鼠标左键就可以。通过根据裂缝的粗细还可以适当的调整容差,提高选中效率,我这里设置为15,容差越小一次选中的区域越小,但也越精细,同理,容差越大一次选中的区域越大,但更粗劣,建议一开始用容差大的选中大部分目标,再选择容差小的选择小部分区域。只要是肉眼能看到的裂缝都要进行标注,太小的肉眼都难以辨别的不用标。井盖、坑槽、修补等不属于裂缝不用标。
7、遇到这种情况只需要多点击一下中间的没选中的区域就行。

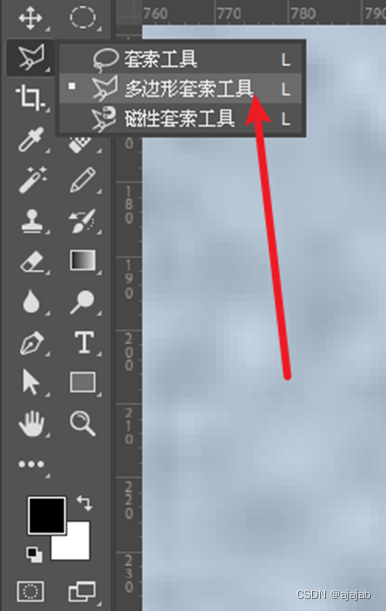
8、最后遇到这种魔棒工具都解决不了的,需要将这两个裂缝连接在一起的,修改长度的,选择多边形套索工具,注意套索工具也要把消除锯齿前面的勾去掉!!!按住shift键(增加选中)或者alt键(取消选中)对需要操作的地方进行编辑。

![]()
9、在标注过程中有标注错误的地方可以按ctrl+z进行撤回,然后继续标注。全部标注好后如图所示:

10、然后看下图左边前景色是否为黑色,后景色是否为白色,如相反点下图箭头指的符号进行改正。
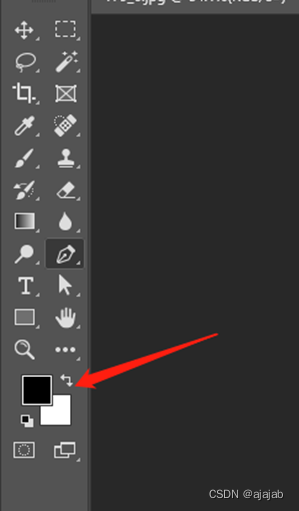
11、接着按ctrl+退格键(backspace)选择后景色白色。

12、然后按ctrl+shift+i 进行反选,选出非裂缝区域,如下图所示:

13、接着按alt+退格键(backspace)选择前景色黑色,选择后如下图所示:
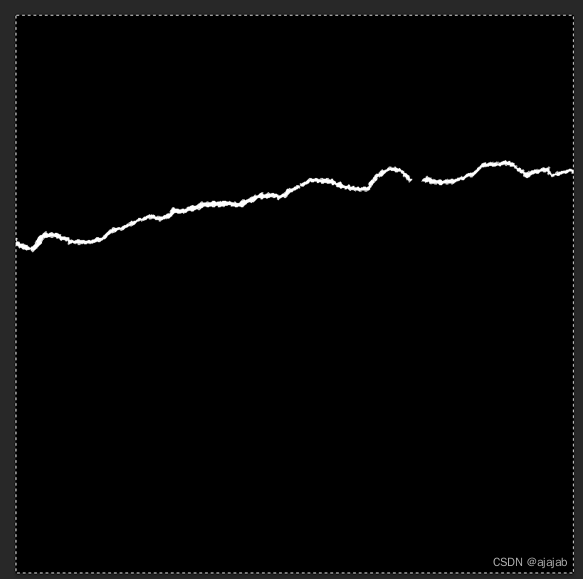
ctrl+退格键(backspace)和alt+退格键(backspace)这两个快捷键可以根据需要来回切换,最终的目的就是把裂缝区域变成白色,把非裂缝区域变成黑色。
14、最后按ctrl+shift+s进行保存,保存位置选择之前新建的mask文件夹中。注意最后保存为.png格式的文件,文件名不变还是原来的名字,只是原来的.jpg类型变成了.png类型。
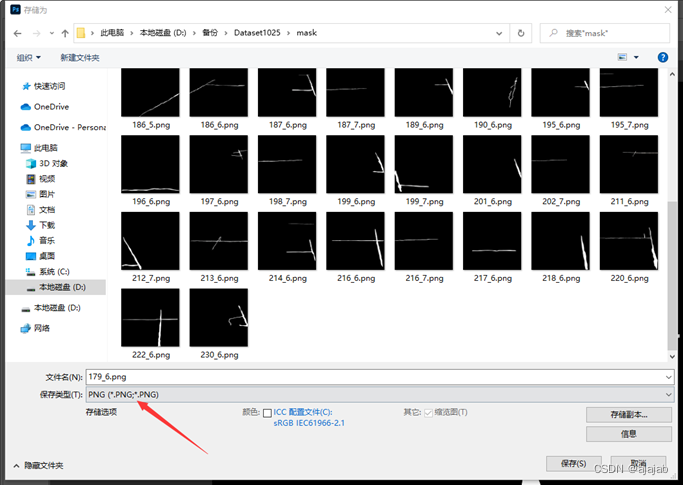
选择默认选项,按确认。
15、最后得到如图所示标签(mask)。

16、将最后得到的标签(mask)图片放大检查,正确的情况应该是第一张图,如果出现第二张图边缘有灰色像素很糊的情况,就是多边形套索工具或者魔棒工具的消除锯齿前面的勾没有去掉。


四、对标签进行二值化处理:
二值图像的用处
二值图像通常用于图像简化,以便进行后续分割、结构元素提取等操作。
另外就是很多的算法都是基于二值图像进行的,所以我们下面我们继续聊聊怎么生成二值图像。
最基本的一个思路就是我们得到的灰度图像,所有的像素值是0-255之间的,打个比方,我们进行图像处理,让像素值小于100的设其像素为0,大于100的设其像素值为1,就得到二值图像了。这个100必然不是固定的,需要进行分析找到这个最适合的值,下面说一下比较常见的算法。
生成二值图像
图像二值化有多种方式,其中最常用的就是采用阈值法进行二值化。而阈值法又细分出来一些算法,像OpenCV的Threshold函数,典型的算法就有Otsu(大津法)、Triangle(三角法)。
以上的方法都是全局阈值技术,另外OpenCV还提供了自适应阈值函数AdaptiveThreshold,自适应阈值一次考虑一小部分相邻像素,计算该特定局部区域的阈值,然后执行分割。
当然,目前利用深度学习进行分割的效果可能很多时候都很不错,不过还是那句话,未必能有那么多的数据来完成任务,这时候还是得选择传统的分割算法。
对数据进行训练时通常需要将图片转化成二值图(只有0和255)的图,具体实现见下列代码:
import cv2
import oswork_dir = r"C:\Users\liu\Desktop\hh" # 图像所处文件夹
result_dir = r'C:\Users\liu\Desktop\hh2'
file_names = os.listdir(work_dir)
for file_name in file_names:# 读取图像文件file_path = os.path.join(work_dir, file_name)image = cv2.imread(file_path, 0) # 以灰度模式读取图像# 对图像进行二值化处理ret, binary_image = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)result_path = os.path.join(result_dir, file_name)cv2.imwrite(result_path, binary_image)print(file_name + ": " + str(set(binary_image.flatten())))点击运行即可进行批量的灰度处理。
感谢大家的支持,写这篇文章不容易,希望大家可以点点关注,点点赞。
这篇关于利用PS进行墙面、道路、大坝、隧道等各种裂缝分割数据的高效标注——超详细,超实用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







