本文主要是介绍数值优化(三)——线搜索最速梯度下降,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 无约束优化
2. step size(步长)选择策略
3.结语
1. 无约束优化
首先,先回顾一下函数的无约束优化。无约束优化,就是不存在inequality或者equality constraint的情况,minimize找到最优的solution。

所谓最初梯度下降,其实就是利用函数的一阶信息局部地找一个让函数值下降最快的方向,然后沿着方向去不断地逼近局部极小值。
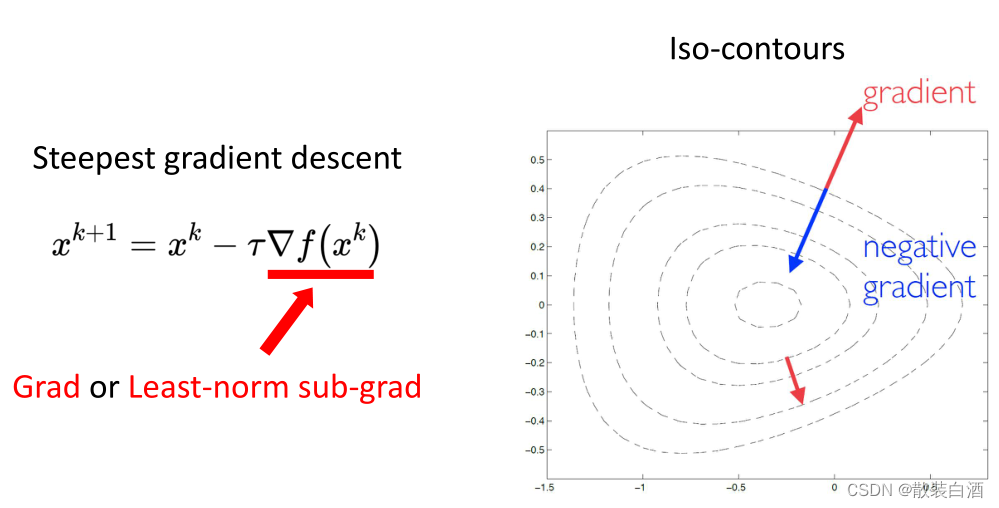
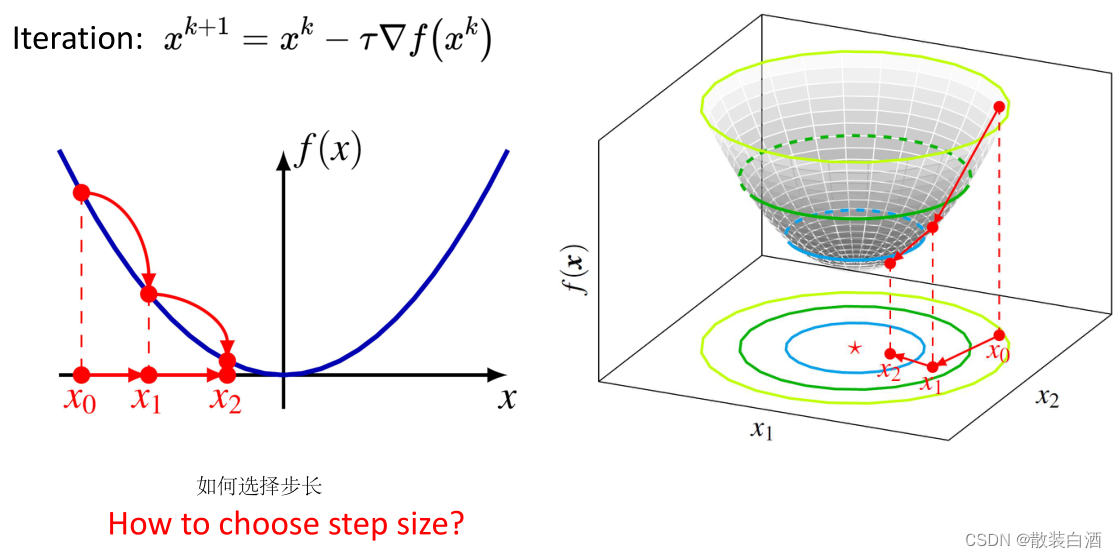
当x越趋于最优解时,更新值越小,它会慢慢地收敛。而如何去选择step size?这是一个值得研究的问题。
2. step size(步长)选择策略
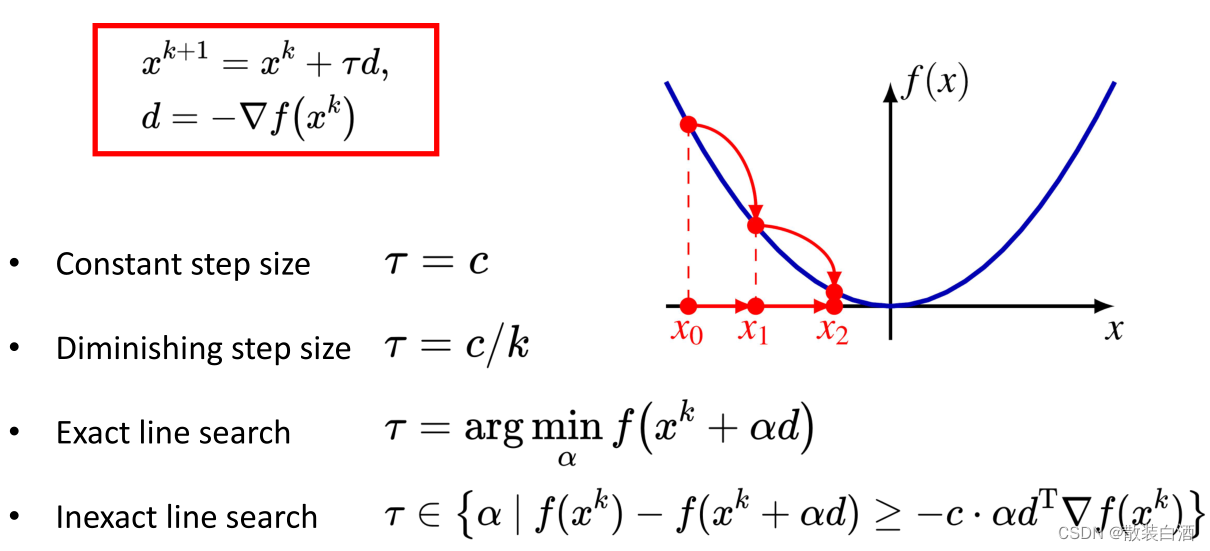
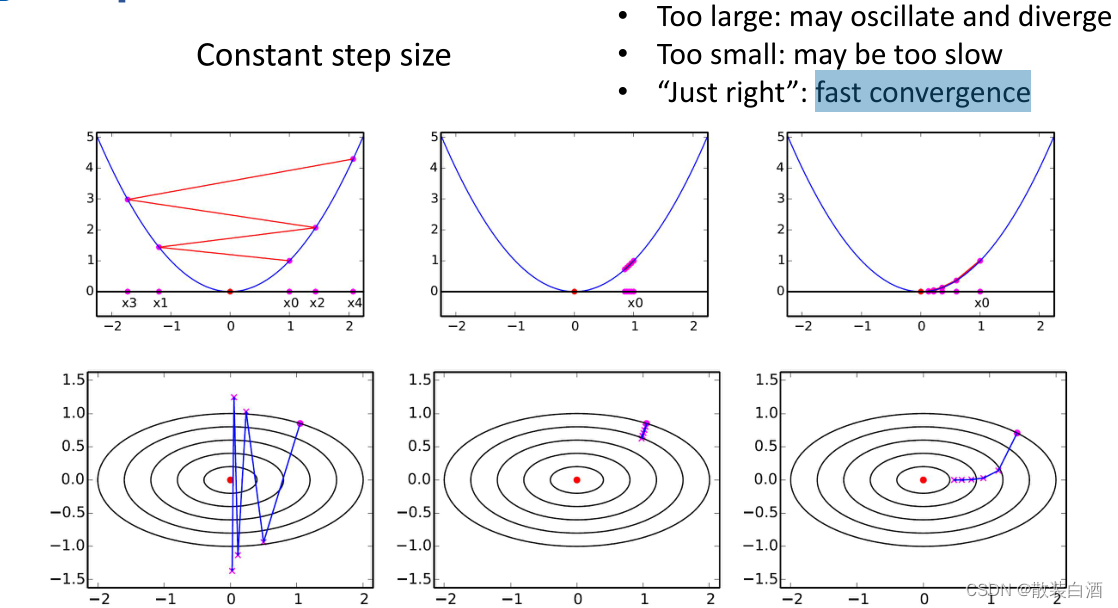
(一)常数步长
步长太大会导致发散和震荡。为了收敛稳定性,我们可以将固定的步长设的很小,但我们需要调用太多次f(x)和函数的梯度,会浪费很多时间。当步长比较智能时,会快速收敛。“just right”是一个很难实现的情况。因此,常数步长不是一个智能的策略。
(二)逐渐减少步长
Diminishing step sizes方法主要是保证步长逐渐变小,同时,变化幅度还不会特别快。这里需要注意的是,次梯度算法并不像梯度下降一样,可以在每一次迭代过程中自适应的计算此次步长(adaptively computed),而是事先设定好的(pre-specified)。
此策略适用性很强,对于非光滑函数和梯度有噪声的情况下,仍可以收敛到最优解附近,但收敛速率较慢。此策略适用于函数先天条件很差,对收敛速率要求不高的情况。
(三)精确搜索
exact line search涉及一个权衡问题,想要得到精准解是一个困难的任务,我们通过迭代的方法来求解f的最优解,在每次迭代中都要解决这样一个任务是很困难的,而且即使计算得到了精准解,这也只是第k次迭代的最优解,对于整个优化问题来说并非关键的。
算法总的效率取决于迭代次数和每次迭代的代价,求解精确解花费了巨大的代价,但可能迭代次数减少的不多,那就得不偿失了。因此会选择花费很少的代价寻找一个差不多的步长,使得目标函数能有充分的下降,虽然迭代次数会多一点,但总的代价反而更少。此策略计算开销较大,由于计算复杂度在实际应用中已很少使用。
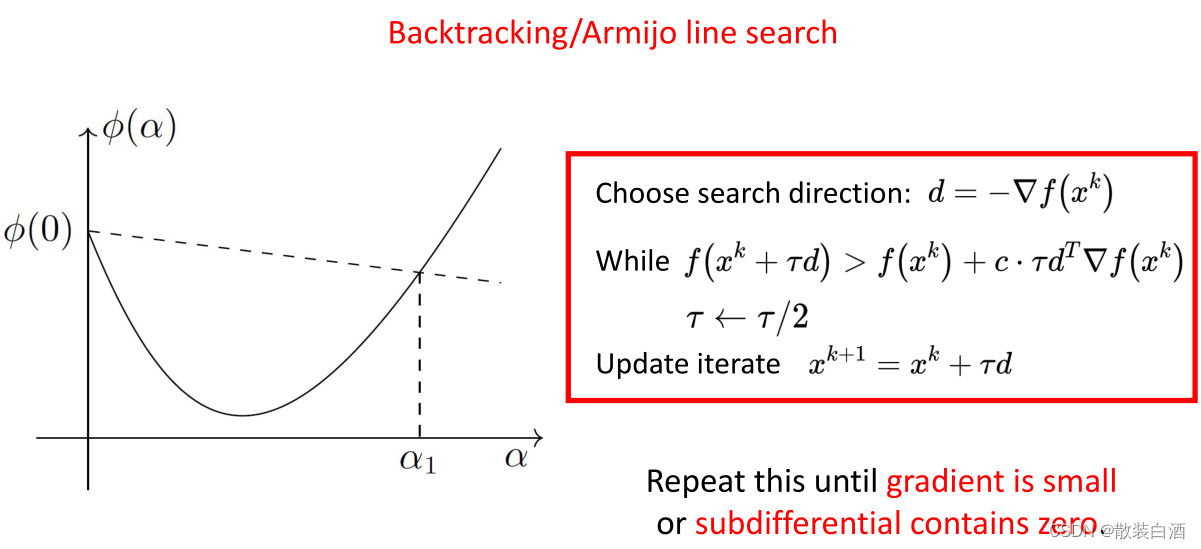
(四)不精确搜索
inexact line search的搜索条件如下:

既然不要求得到精确的步长,只需要使目标函数充分下降,那么前进一步至少比现在强,但这样够充分吗?显然是不行的。
3.结语
更少的迭代并不保证更高的效率。线搜索的缺点也很明显,由于梯度与等高线是垂直的,当条件数很大或者曲率很大时,等高线几乎平行,迭代次数会很多。当条件数很小时,会导致性能下降。要更快地收敛,曲率是必不可少的。
这篇关于数值优化(三)——线搜索最速梯度下降的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






