本文主要是介绍编译原理实验:自下而上的语法分析(LR分析程序),附代码(C++),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、写在前面
二、实现要求
三、思路及代码
文法分析
构造DFA:
构造LR分析表
移进
归约
非终结符
构造SLR分析表
归约
一、写在前面
2023.7.7更新,针对这篇文章提到的不足更新了新的文章:
其中实现了大于一个字符变量的运算和扩展了运算符(这个程序只有加法和乘法),并且做了完整的编译器:自下而上的编译器
1.本人并不擅长编程和编译原理这门课程,只是写代码之后蛮有意义。觉得可以分享出来,各位可以交流学习,如果有错误欢迎指出。
2.不保证思路和解决方式是最佳思路,也不能保证正确性,请勿将本文当做考试复习参考。其中涉及到专业名词的部分可能会有描述错误,请谅解。
3.本人个人写代码不习惯写注释,变量的命名也很随意,请谅解。
4.本文会讲述全部代码思路,代码是按模块分段展示的(也会在文中提及主函数的编写逻辑),代码需要自己整合,有编程基础的朋友一定能在阅读后根据提示写出完整程序。因为看到很多朋友在解决此法时遇到困难,仅作为交流。如果是想要直接复制完整代码的本站有其他大佬的分享帖。
5.请谅解文章中的错别字,标点符号,以及的地得!
6.ncwu慎用。
二、实现要求
(1)根据给定文法,先对文法进行解析,构造识别活前缀的 DFA 并输出;
(2)根据 DFA 构造 LR 分析表并输出;
(3)分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程)
(4)假如给定表达式文法为:
G(E’): E’→#E#
E→E+T | T
T→T*F |F
F→(E)|i
分析的句子可为: (i+i)*i 和 i+i)*i
三、思路及代码
这里受篇幅限制就不介绍LR分析法的原理了,大家可以自行阅读教材,这里我使用的是陈火旺编写的《编译原理》教材。
这个代码实现步骤其实很清晰,我们可以把他拆分成四步:拿到文法进行分析->构造DFA->构造LR分析表->归约。那么这里就按照这四步分别展开阐述。
-
文法分析
为了后面阅读的通畅这里介绍一下程序的一些前期的初始化。我们建立了类word,在构造函数中提前把表达式文法放到了数组id[]中。关于word类中后续的元素以及作用会在后面的文章中提及。
class word{public:string id[50];string w[50];//存放完整的文法string VN[50],VNPLUS[50][50];//存放非终结符string VT[50];//存放终结符string cla[50],flag[50][50];//flag是是否存放非终结符的标志 string gui[50],yuan[50];string LR[50][50],action_goto[50][50];int n=4,n1,x,numlr;//x是非终结符个数 numlr为lr的行 int list[50][50],numplus[50],nnn[50]; //numplus为 VNPLUS数量 nnn为lr的每个元素数量 int t,f[50],numvex[50],deff[50],numdef; //终结符个数 int SLR[50],slr,notes,numfollow[50];//这里如果出现移进归约冲突,用SRL标记其是否为LR文法 string fx1,fx2;string follow[50][50];word();void makefollow();//求follow集 void flit();void settle(); //整理前面不完美的 VNPLUS,VNPLUS的目的是把规范族整理方便计算 bool flagVN(string a);void copy(int a,int b);int number(string a,int i);//返回坐标函数,i=1表示终结符 void guiyue(string a);//开始归约 int getLR(string a);//寻找这是第几个生成式 string int_tostr(string a[],int i);string suibianla(string a);//这个是取数字的,不知道起什么名字 typedef struct //这是一个图 {string vex[50][50];//存放顶点string arcs[50][50];//邻接矩阵int vexnum,arcnum;//边数和节点数量 }AMGC;void Createamg(AMGC &G,string str[],int a);void foll(AMGC &G,string str,int a);void full(AMGC &G);void makelist(AMGC &G);void check(AMGC &G,int i,int dot,int chaoji);//用于检查,如果新生成的规范组是之前有的,那么及时地删掉,也可以防止死循环 void makeslr(AMGC &G);//如果不是LR,就生成SLR
}; word::word(){this->id[0]="E'->#E#";this->id[1]="E->E+T|T";this->id[2]="T->T*F|F";this->id[3]="F->(E)|i";this->fx1="#(i+i)*i#";this->fx2="#i+i)*i#";this->n1=0;this->t=0;this->numlr=0; this->numdef=0;this->slr=0;for(int i=0;i<50;i++){this->numplus[i]=0;this->nnn[i]=0; this->f[i]=0;this->numvex[i]=0;this->deff[i]=0;this->SLR[i]=0; this->numfollow[i]=0;}for(int i=0;i<50;i++){for(int j=0;j<50;j++){this->list[i][j]=2;this->action_goto[i][j]="-1";this->follow[i][j]="";}}
}文法分析其实和算符优先分析程序并没有太大差异,这里简单回顾一下,在分离文法时,利用“->”和“|”做判断符,将前者a与后者yuan[i]做链接形成单独的文法,将产生式的非终结符,终结符,单个产生式分别保存,便于日后使用。产生的结果放在数组w[]中,非终结符和终结符分别保存在数组VN[]和VT[]。
void word::flit(){//分离文法 string a,a1;int k=0,j,flag;x=0;for(int i=0;i<n;i++){if(id[i].substr(id[i].length()-1,1)=="#"){continue;}for(j=0;j<id[i].length();j++){if(id[i].substr(j,2)=="->"){a=id[i].substr(0,j+2);a1=id[i].substr(0,j);k=j+2;VN[x]=id[i].substr(0,j);x++;}if(id[i].substr(j,1)=="|"){//根据“|”符号进行拆分 yuan[n1]=id[i].substr(k,j-k);//yuan是表达式箭头后面的部分gui[n1]=a1;//gui是表达式箭头前面的部分w[n1]=a+yuan[n1]; k=j+1;n1++;}}}gui[n1]=a1;//这一部分和第二个if一样,因为后面的产生式没有“|”结尾yuan[n1]=id[i].substr(k,j-k);w[n1]=a+id[i].substr(k,j-k);n1++;
}for(int i=0;i<n;i++){//这个循环是为了保存产生式中的终结符 for(j=3;j<id[i].length();j++){flag=0;for(int p=0;p<x;p++){if(id[i].substr(j,1)==VN[p] || id[i].substr(j-1,2)=="->"){//防止“->”和非终结符被放入flag=1;break;}if(id[i].substr(j,1)=="|"){//防止“|”被放入flag=1;break;}}for(int p=0;p<t;p++){if(id[i].substr(j,1)==VT[p]){//排除重复flag=1;break;}}if(flag==0){VT[t]=id[i].substr(j,1);t++;}}
}但是对于LR分析程序我不同的是需要对文法进行拓广,那么我们手动的删去id[0],并新增一个产生式“S’->E”,如方代码所示(这段代码要加到上面函数的开头):
w[n1]="S'->"+id[0].substr(0,1);
n1++;
VN[0]="S\'" ;//新加入的S’要放入非终结符数组中
x++;//x是非终结符的数量接下来生成每个产生式的项目,这里很简单,只需要用一个循环,循环变量从每一个产生式的“->”的下一个位置开始,直到结尾,每一遍循环就在循环变量的位置添加上“.”。这里采用的方法是拆分头尾字符串然后与点号链接。(这里我一开始弄错了,其实项目加的应该是“·”而不是“.”后面没来得及修改)这一部分的代码如下:
while(k<=w[i].length()){LR[numlr][nnn[numlr]]=w[i].substr(0,k)+"."+w[i].substr(k,w[i].length()-k);k++;nnn[numlr]++;
}完整代码如下:
k=0;
for(int i=0;i<n1;i++){//这里推导每个产生式对应的项目 while(w[i].substr(k,1)!=">"){k++;} k++;nnn[numlr]=0;//while循环前是一些初始化工作,没有这些代码也没关系LR[numlr][nnn[numlr]]=w[i].substr(0,k-2);nnn[numlr]=1;VNPLUS[number(w[i].substr(0,k-2),0)][numplus[number(w[i].substr(0,k-2),0)]]=w[i].substr(0,k)+"."+w[i].substr(k,w[i].length()-k);numplus[number(w[i].substr(0,k-2),0)]++;while(k<=w[i].length()){LR[numlr][nnn[numlr]]=w[i].substr(0,k)+"."+w[i].substr(k,w[i].length()-k);k++;nnn[numlr]++;}k=0;numlr++;
}结果保存在二维数组LR中,此外还建立了一个二维数组VNPLUS,这个数组的作用有点类似于firstvt集,由于E->T的存在,当存在项目E->.T时,必然要将T的所有项目集也放到E->.T的项目集中,所以VNPLUS的作用就是在出现E->.T项目时,将T的所有T->.α的项目放在数组VNPLUS中与E->.T同一列的位置,方便日后复制。
void word::settle(){//这里有点像求firstvt集的做法 int k(0),k2;for(int i=x-1;i>=0;i--){for(int j=0;j<numplus[i];j++){k=0;while(VNPLUS[i][j].substr(k,1)!="."){k++;}k++;if(VNPLUS[i][j].substr(k,1)!=VNPLUS[i][j].substr(0,k-3) and not flagVN(VNPLUS[i][j].substr(k,1)))copy(number(VNPLUS[i][j].substr(k,1),0),number(VNPLUS[i][j].substr(0,k-3),0));}} //顺便整理一下action_gotofor(int i=0;i<=t;i++){action_goto[0][i+1]=VT[i];k2=i+1;}for(int i=1;i<x;i++){action_goto[0][k2]=VN[i];k2++;} char str[5]={0};action_goto[0][0]=" ";for(int i=1;i<50;i++){itoa(i,str,10);action_goto[i][0]=str;}
}这里IF的两个条件分别是E->.T中E与T不相等(相等不就死循环了),并且T为非终结符,flagVN函数用来判断当前字符是否为终结符,是终结符返回TRUE。Copy函数用来复制两个数组,将前面参数的数组复制到后面参数对应的数组。
bool word::flagVN(string a){for(int k=0;k<x;k++){if(a==VN[k]) {return false;}}return true;
}同时这里出现的number函数介绍一下,number函数是用来返回当前字符在某个表中的位置,整个表是根据参数来定的。比如说参数为3,那么返回的是在LR分析表中每个字符对应的列,参数为2则表示行,参数为0 则返回下面VNPLUS的行,举个例子:number(“E->.E+T ”,0)返回的值就是1(开始为0 )。当然,由于所有的非终结符和终结符排列顺序都基本一致,所以也可以按需求得到很多不同的表中的值。你可以根据自己的需要编写自己的number函数。
int word::number(string a, int i){if(i==1){for(int p=0;p<t;p++){if(a==VT[p]) return p;}}if(i==0){for(int p=0;p<x;p++){if(a==VN[p]) return p;}}if(i==2){for(int p=1;p<=notes;p++){if(a==action_goto[p][0]) return p;}}if(i==3){for(int p=1;p<=x+t-1;p++){if(a==action_goto[0][p]) return p;}}
}得到的两个数组如下:


-
构造DFA:
接下来我们就要根据得到的LR与VNPLUS构造DFA,这一步是最难的,因为要一边生成新的节点一边检查循环状况防止出现死循环。我在这里用到了数据结构中的图,用图节点的值存放每一个项目集中闭包的元素,图的邻接矩阵存放DFA中项目集转化情况。

首先我建立了函数foll (AMGC &G,string str,int a),参数分别为:图、要添加的项目、项目加入的项目集的编号。这个函数并不考虑循环问题(只考虑一个,就是当前添加的项目是否是之前添加过的,如果有就退出循环,这部分代码见下图),这个函数做的事情就是将项目加入到项目集a中,然后添加他的所有闭包元素,而闭包元素恰恰是我们之前求过的VNPLUS,那么我们只需要把对应的VNPLUS添加进来即可。

if(not flagVN(str.substr(p,1)))//(如果是非终结符那么加入VNPLUS中的元素)for(int i=0;i<numplus[number(str.substr(p,1),0)];i++) {numvex[a]++;G.vex[a][numvex[a]]=VNPLUS[number(str.substr(p,1),0)][i];}在程序的开头我调用函数foll最开始用了这个语句W.foll(G,W.LR[0][1],1);也就是将第一个项目S'->.E添加到DFA的项目集1中,使DFA中有初始值,方便后续计算。
接下来对于添加元素的选择和死循环的规避,我放在了函数full中(这两个差不多我也不知道取啥名字,乱取的)。在函数full中,我们建立一个循环,循环变量从1开始,一直到等于当前图中节点个数时结束,即i==G.vexnum,因为图G每存在一个节点,相应的,我们就要对这个节点中所有的项目进行一次遍历,所以当节点全部遍历完成后,循环也就结束了。
在循环的过程中,首当其冲要考虑的就是结尾的归约项目,也就是“.”点号出现在结尾的项目,这些项目我们不用去考虑因为他既不会生成新的节点也没有闭包集。
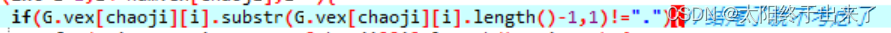
然后我们对于每一个不是归约项目的项目找到他在LR数组中右边的项目,因为这个项目就是他下一步要转换的项目(这里的专业名词有点小混乱,求谅解)。

接下来要考虑两种情况:
一是这个项目的路径之前项目集中的项目就已经创建过,如:【S'->.E E->.E+T E->.T T->.T*F T->.F F->.(E) F->.i】这个项目集中,E->.E+T和S'->.E对应的下一个项目是属于同一个项目集【S'->E. E->E.+T】的,所以针对这种情况,我们调用foll是要将a的参数设为k,k即为上一次S'->.E 生成的项目集编号,即foll(G,LR[mmm][jj+1],k);
第二种则是其他状况,我们把象征着项目集总量的G.vexnum自增一,然后调用foll(G,LR[mmm][jj+1],G.vexnum); 即可。

每一次foll函数生成完节点后,我们都要用check函数做一次检查,因为存在求闭包的环节,所以不可避免的会出现后面生成和前面一模一样的节点的情况,这时,我们只需要将其删除即可。当然啦,删除并不是每个清空,我们只需要把相关的计数项减一或置零即可,当有新的节点生成数据会进行覆盖,所以不用担心。
check函数如下:
void word::check(AMGC &G,int i,int dot,int chaoji){int flag1;for(int x=1;x<G.vexnum;x++){flag1=0;for(int y=1;y<=numvex[x];y++){if(G.vex[x][y]!=G.vex[G.vexnum][y]){flag1=1;break;}}if(flag1==0){//找到一样的,删除 G.arcs[chaoji][x]=G.vex[chaoji][i].substr(dot,1);G.arcs[chaoji][G.vexnum]="-1";numvex[G.vexnum]=0;G.vexnum--;}}
}foll和full函数如下:
void word::foll(AMGC &G,string str,int a){int p,dot,point,j,flag,mm,mmm,jj;for(int i=0;i<=numvex[a];i++){ //防止死循环 if(str==G.vex[a][i]) return;}numvex[a]++;G.vex[a][numvex[a]]=str;for(p=0;p<=str.length();p++) {if(str.substr(p,1)==".") break;}p++;if(not flagVN(str.substr(p,1)))for(int i=0;i<numplus[number(str.substr(p,1),0)];i++) {numvex[a]++;G.vex[a][numvex[a]]=VNPLUS[number(str.substr(p,1),0)][i];}else return;
} void word::full(AMGC &G){int p,dot,point,j,flag,mm,mmm,jj,flag1;char str[5]={0};for(int chaoji=1;chaoji<=G.vexnum;chaoji++)for(int i=1;i<=numvex[chaoji];i++){if(G.vex[chaoji][i].substr(G.vex[chaoji][i].length()-1,1)!="."){//结尾了就不考虑了 for(point=0;point<=G.vex[chaoji][i].length();point++) {//这俩是定位用的if(G.vex[chaoji][i].substr(point,2)=="->") break;}for(dot=0;dot<=G.vex[chaoji][i].length();dot++) {if(G.vex[chaoji][i].substr(dot,1)==".") break;}dot++;for(mm=0;mm<=numlr;mm++)for(j=0;j<nnn[mm];j++){//从LR表中找到他的下一个项目集 if(LR[mm][j]==G.vex[chaoji][i]) {mmm=mm;jj=j;break;}}flag=0;for(int k=1;k<=G.vexnum;k++){if(G.arcs[chaoji][k]==G.vex[chaoji][i].substr(dot,1)) {flag=1;foll(G,LR[mmm][jj+1],k);check(G,i,dot,chaoji);//去重 防止死循环 }}if(flag==0) {G.vexnum++;G.arcnum++;G.arcs[chaoji][G.vexnum]=G.vex[chaoji][i].substr(dot,1); foll(G,LR[mmm][jj+1],G.vexnum);check(G,i,dot,chaoji);} }else if(G.vex[chaoji][i].substr(0,2)=="S'"){//这里后面会解释action_goto[chaoji][number("#",3)]="acc";SLR[chaoji]=1;//标记归约项 }else SLR[chaoji]=1;//标记归约项 }
}好啦,这样我们就得到了我们想要的DFA啦,输出看看。好吧由于是二维数组,输出起来有点麻烦,不过至少是对了。

-
构造LR分析表
那么接下来我们就可以通过邻接矩阵构造我们的LR分析表啦!
当做到这一步我们的程序就完成60%啦,那我们慢慢地一种情况一种情况分析,这里的模块名是makelist。
移进
首先是移进:
关于移进,规则是如果项目A->α.aβ属于第K个项目集,且a为终结符GO(K,a)=J,J表示第J个项目集。那么在邻接矩阵中就可以表示为(K, J)=a。按照规则此时要将ACTION[K,a]置为SJ。
那么,我们就可以开始在邻接矩阵中遍历,当邻接矩阵中的元素为非终结符时把ACTION[K,a]设置为SJ。

归约
然后是归约:
归约的话是针对项目A->α.,对于所有的终结符都置为rj(j为A->α是文法的第j个产生式)。那这里我们又要回到前面去工作。在函数full中,之前的if规避了归约项目的讨论,所以在else中我们对它进行了标记。

这里其实还顺带解决了接受置“ACC”的这种情况,那后文就不谈了。当然啦,还有一个要解决的是,J的值,这里我之前做错了,这里没有改回来(当然这例子不会出问题,其他不同的文法可能会出问题)这里其实是要去DFA遍历找到归约项目(或者是在生成DFA时标记),我之前以为归约项目只会出现在第一个(后来做题目时发现的没有出现在第一个的情况)。这里如果老师给的文法例子和我不同的需要修改(日后有时间会PO出需要修改的代码,不过绝大多数情况是出现在第一个的)。
所以我们在makelist中对于SLR等于1的每一个项目集对应的ACTION表,置RJ。

在这里讲一下处理移进-归约冲突(以及归约-归约冲突),那么出现了移进-归约冲突肯定是表里边已经有了SJ或者说是RJ,所以判断的标志就是action表是否为初始值“-1”,也就是表里面的这个位置有没有写入东西。

在主函数中,我及时输出了不是LR(0)文法的提示:
if(W.slr==1){cout<<endl<<"该文法存在移进-归约,不是LR(0)文法"<<endl;W.makeslr(G);
}这里的makeslr后文会解释。
非终结符
最后是非终结符:
这个其实和移进是一样的只是把a变成了A,这里就不多赘述了。
这样我们就得到了一张LR分析表,输出后如下:

这个函数的全部代码如下:
void word::makelist(AMGC &G){char str[5]={0};notes=G.vexnum;int m;for(int i=1;i<=G.vexnum;i++){for(int j=1;j<=G.vexnum;j++){//根据邻接矩阵来构建分析表 if(SLR[i]==1) {if(G.arcs[i][j]!="-1"){slr=1;}}if(G.arcs[i][j]!="-1") {if(SLR[j]==1 && G.vex[i][1].substr(0,2)!="S'"){//下一个是归约项 for(int k=1;k<=t;k++){m=getLR(G.vex[j][1]);itoa(m,str,10);if(action_goto[j][k]!="-1" && action_goto[j][k].substr(0,1)=="s"){//是被移进-归约 action_goto[j][k]=action_goto[j][k]+"/r"+std::string(str); }else if(action_goto[j][k]!="-1" && action_goto[j][k].substr(0,1)=="r" and action_goto[j][k].substr(1,1)!=str){//是被归约-归约 action_goto[j][k]=action_goto[j][k]+"/r"+std::string(str); }else{action_goto[j][k]="r"+std::string(str);} }}if(!flagVN(G.arcs[i][j])) {//非终结符itoa(j,str,10);action_goto[i][number(G.arcs[i][j],3)]=str; }else{//终结符,这里要注意会出现移进-归约if(action_goto[i][number(G.arcs[i][j],3)]=="-1"){//未被占用 itoa(j,str,10); action_goto[i][number(G.arcs[i][j],3)]="s"+std::string(str); } else{//出现移进-归约冲突 itoa(j,str,10); action_goto[i][number(G.arcs[i][j],3)]="s"+std::string(str)+"/"+action_goto[i][number(G.arcs[i][j],3)]; }}}}}
}但是,我们得到的这张表并不是我们所希望的,因为这里出现了冲突(当然在其他例子里也会相应的出现归约—归约冲突),所以我们还要对LR分析表进行优化,使之变为SLR分析表。
-
构造SLR分析表
那么从书上的方法我们可以知道,要想要去求SLR分析表就要先求每个非终结符的FOLLOW集,这里我定义了求FOLLOW集的函数makefollow。
接下来我们就可以根据求到的follow集重新制作SLR的分析表了,当然其实简单的办法是在制作LR分析表的时候如果发现冲突就变成制作SLR表,这样可以放到一个模块里省去很多空间复杂度(不用多来很多次循环),但是这里做实验先怎么样后怎么样有条理一点,所以我们单独创建函数makeslr来制作SLR分析表。
我这里很简单粗暴的用action_goto[i][j].length()>3来识别冲突项,主要是一般情况也不会有三位数的规范族,所以这里就简单粗暴一点吧。这里吧冲突项“/”号左右的两个标志分别赋值给a和b。然后清空action表(置为“-1”),这里保留了前面的一项,别忘了我们之前制作LR分析表的时候是把移进项放前面的。
然后就很简单啦,只需要把b的值赋给归约项目开头非终结符对应的follow集中每个元素对应的SLR表中的位置就好啦(这话怎么这么绕)。
这段的代码如下:
void word::makeslr(AMGC &G){int k;string a,b;for(int i=0;i<=G.vexnum;i++){for(int j=0;j<=x+t-1;j++){if(action_goto[i][j].length()>3){//这里简单粗暴了 k=0;while(action_goto[i][j].substr(k,1)!="/"){k++; }a=action_goto[i][j].substr(0,k);b=action_goto[i][j].substr(k+1);for(int m=1;m<=t;m++){action_goto[i][m]="-1";}action_goto[i][j]=a;for(int m=1;m<numvex[i];m++){if(G.vex[i][m].substr(G.vex[i][m].length()-1)=="."){for(int n=0;n<numfollow[number(G.vex[i][m].substr(0,1),0)];n++){action_goto[i][number(follow[number(G.vex[i][m].substr(0,1),0)][n],1)+1]=b;}} }}}}cout<<endl<<"SLR分析表:"<<endl;for(int j=0;j<=G.vexnum;j++){for(int i=0;i<=x+t-1;i++){cout<<setw(5)<<action_goto[j][i]<<" ";}cout<<endl;}
}好啦,让我们输出SLR表看看:

太不容易啦,接下来就是最后一步啦。
-
归约
首先在这里进行一些说明,这里按照教材应该是建立一个符号栈和一个状态栈记录归约时的符号和状态,但是由于我们前面为了方便所有的数据变量存放在C语言的string这个类下面的(当然这个可以看做是字符串变量类型),如果用数据结构定义栈的结构体,栈的指针指向string很难弄,比较复杂,如果求方便要多次进行char和string的类型转换,特别麻烦。反过来想,我们的string类本身就可以看成是一个栈,在一个字符串中,左边可以视为栈底,右边可以视为栈顶,压入的过程就是右链接的过程,而取数据的过程只需要调用str.substr(str.length()-1,1)就可以把(栈顶)的元素取出来。
但在这里会出现问题,在状态栈中,状态并不一定是一个字符,可能会出现10,11这样的状态,如果直接用str.substr(str.length()-1,1)只取一个元素就会出现问题,而且状态栈是由数字组成的并不需要进行字符串操作。所以对于状态栈,我们为了统一把他定义为string status[20](这里当然可以把他定义成 char status[20],然后用数据结构中一般的栈来做,也就是新建一个栈的结构体那种方法,但是由于前面的符号栈已经用了 string类所以这里是为了统一)。各个变量的含义如下:

当然啦,说到这里其实在其他例子中,终结符和非终结符也不一定只有一个字符,(比如C语言中的++运算、&&运算)。但是由于时间关系这里就先不考虑了,日后有机会再完善,但其实思路是没有问题的,只是取数据的时候要加上位数的判断,这个可以参考下文对于状态的判断。
由于我们的SLR表是直接对LR分析表的覆盖,所以不会有什么影响下面就全部称为LR分析表。
根据LR分析表,这里会出现的一共是四种情况分别为acc、r(归约)、s(移进)和空(在我们的表中是为“-1”),那么我们就从简单到复杂一个一个分析。
首先是acc和空,出现这两种符号一个是表示归约过程中的接受,另一个可以理解为不能归约的报错。那么在代码段就可以很简单的进行表示。一个输出归约完成,一个输出无法归约,然后跳出循环。在这里我们的循环条件是一个while(1)也就是while(TRUE)的死循环,两个条件判断是循环跳出的唯一条件,当然这里不用担心会出现死循环,因为对于任意给定的句子,只会出现可以归约和不能归约两种情况,所以这两个条件判断能保证我们的程序跳出循环。
然后是较为简单的移进,这里解释一下为什么要建一个suibianla(随便啦)函数,最开始时的时候我思路错了,我想直接用LR表做,所以取数字的时候不能直接str.length(1),这样有可能会直接取到类似6/r3这样的不能识别的,所以就建了一个suibianla函数,那现在修改了之后没有删掉一个是我懒去掉了。

然后移进的代码如下,就是很简单的添加和删除,这里不作过多阐述。

在这里z表示的是剩余串,因为要移进所以剩余串最开头(左边)要截去。
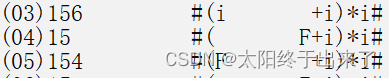
接下来归约同理,归约有一点要考虑的是,归了几个元素,状态栈的数字就要减去几。其实我们早在分离文法的时候,就把产生式箭头的左右两部分存放在了数组gui[]和yuan[]中(当时起名字想的是归约和原来的),请看下图。

所以我们在进行归约时,只需要把symbol和k减去yuan的长度,然后在Z的开头(左边)添加上gui数组中对应的元素即可,那么下一步由于Z开头的元素变为了非终结符(通常情况,可能有特例)那么肯定会执行移进操作(书上这两步合到一起了,可能会有点混乱,我们这里分 开清晰一点),如图,04步骤就是我们上文提到的归约,而05步骤就是再次移进,书中这两步合为了一步。
这部分的代码如下:
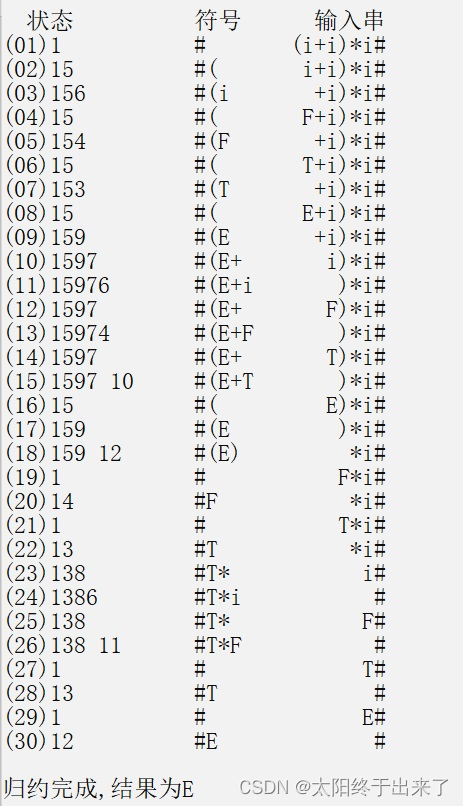
void word::guiyue(string a){string status[20],symbol,x,y,z,xg,i1,nu,nu1;//这里用string当作栈,反正原理差不多//status记录状态,symbol记录符号 x是当前要入栈的输入 y是当前要比较的状态int k,n,i; //k记录status的数量 status[1]="1";symbol="#";k=1;i=2;nu="";nu1="";z=a.substr(1);char str[5]={0};for(int m=1;m<=6-int_tostr(status,k).length()+symbol.length();m++){nu=nu+" ";}for(int m=1;m<=8-symbol.length();m++){nu1=nu1+" ";}cout<<" 状态 符号 输入串"<<endl; cout<<"(01)"<<int_tostr(status,1)<<nu<<setw(6)<<symbol<<nu1<<setw(8)<<a.substr(1)<<endl;nu="";nu1="";while(1){x=z.substr(0,1);y=status[k];if(action_goto[number(y,2)][number(x,3)].substr(0,1)=="s"){//移进k++;status[k]=suibianla(action_goto[number(y,2)][number(x,3)]);symbol=symbol+x;z=z.substr(1);}else if(action_goto[number(y,2)][number(x,3)].substr(0,1)=="r"){//归约xg=suibianla(action_goto[number(y,2)][number(x,3)]);n=number(xg,2);symbol=symbol.substr(0,symbol.length()-yuan[n-1].length());z=gui[n-1]+z;k=k-yuan[n-1].length();}else if(action_goto[number(y,2)][number(x,3)]=="acc") {cout<<endl<<"归约完成,结果为"<<symbol.substr(1)<<endl; break;}else if(action_goto[number(y,2)][number(x,3)]=="-1") {cout<<endl<<"无法归约"<<endl;break; }else{k++;status[k]=action_goto[number(y,2)][number(x,3)];symbol=symbol+x;z=z.substr(1);} itoa(i,str,10);if(i<10) i1="0"+std::string(str);else i1=itoa(i,str,10);for(int m=1;m<=6-int_tostr(status,k).length()+symbol.length();m++){nu=nu+" ";}for(int m=1;m<=8-symbol.length();m++){nu1=nu1+" ";}cout<<"("<<i1<<")"<<int_tostr(status,k)<<nu<<setw(6)<<symbol<<nu1<<setw(8)<<z<<endl;nu="";nu1="";i++;} }到这一步,我们的程序就正式完成啦!输出看看!
string word::int_tostr(string a[],int i){string b;b="";for(int j=1;j<=i;j++){if(a[j].length()>1) b=b+" ";b=b+a[j];}return b;
} 接下来这里放的是前文中漏掉没有PO出代码的函数:
int word::getLR(string a){
//这个是找第几个归约项目,用在制作分析表时for(int i=0;i<numlr;i++){for(int j=0;j<nnn[i];j++){if(LR[i][j]==a) {return i+1;}}}
}最后关于主程序这里进行说明。主程序中(见下图),首先定义了类W和图G,然后下面的循环目的是初始化图G。接下来只要按照上文提到的顺序调用函数就可以了,由于归约模块的输出放到了模块内,所以归约函数的调用要放在最后(当然不影响,只是打印的逻辑看起来顺畅一点)。

而其他的输出可以按需取用,如下图所示:
主函数代码如下:
main(){word W;word::AMGC G;G.vexnum=1;G.arcnum=0;for(int i=0;i<50;i++){for(int j=0;j<50;j++){G.arcs[i][j]="-1";}}W.flit();W.makefollow();W.settle();W.foll(G,W.LR[0][1],1);W.full(G);W.makelist(G);//for(int j=1;j<=G.vexnum;j++){// for(int i=1;i<=W.numvex[j];i++){cout<<G.vex[j][i]<<" "<<endl;}// cout<<endl;//}cout<<endl<<"文法项目如下:"<<endl; for(int i=0;i<W.numlr;i++){for(int j=0;j<W.nnn[i];j++){cout<<W.LR[i][j]<<" ";}cout<<endl;}cout<<endl<<"LR分析表:"<<endl;for(int j=0;j<=G.vexnum;j++){for(int i=0;i<=W.x+W.t-1;i++){cout<<setw(5)<<W.action_goto[j][i]<<" ";}cout<<endl;}if(W.slr==1){cout<<endl<<"该文法存在移进-归约,不是LR(0)文法"<<endl;W.makeslr(G); }cout<<endl;W.guiyue(W.fx1);//for(int j=1;j<=G.vexnum;j++){//for(int i=1;i<=G.vexnum;i++){cout<<setw(2)<<G.arcs[j][i]<<" ";}//cout<<endl;//}//for(int i=0;i<W.n1;i++){cout<<W.deff[i]<<" "<<endl;}//cout<<endl;W.makefollow();
}以上,谢谢阅读,感谢你的时间。
这篇关于编译原理实验:自下而上的语法分析(LR分析程序),附代码(C++)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





