本文主要是介绍kitti数据集转换成voc数据集格式(rpn训练三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
近来冠状病毒肆虐,还是好好响应国家号召待在家里。闲来无事就搞一下用于faster-rcnn训练用的数据集。这篇博客详细地注释了将kitti数据集转换成pascal voc格式的代码,结合网上各个前辈的博客,记录了自己动手实验的过程。转换完成后的标签以及图片,将用于训练faster-rcnn关于车辆检测识别的模型。
第一部分:数据集的准备
1. 下载kitti数据集
参考博主micro wen的博客,可以通过kitti数据集的介绍进行详细了解数据集的形式。通过进入原网址下载或者Kitti数据集下载百度云下载data_object_image_2.zip和data_object_label_2.zip。
下载后得到两个文件:
- 原始图片集:data_object_image_2.zip,解压后得到png格式的训练集和测试集对应元素图片;
- 标签集为:data_object_label_2.zip,解压后得到为txt格式的训练集对应标签文件,包含诸如下列形式的内容:
Car 0.00 0 -1.75 685.77 178.12 767.02 235.21 1.50 1.62 3.89 3.27 1.67 21.18 -1.60
每一行就是一个object,第一个即为类别信息,后面是bounding box信息,具体可以查看相关博客。
2. pascal voc2007介绍
这里只简单介绍一下,详细可移步这里。VOC2007包含3个文件夹:
-
JPEGImages ==》》 用来存放所有的原始图片,格式为JPG。
-
ImageSets ==》》(包含多个子文件夹,目标检测中只用到Main文件夹)
Main —>存放一些txt文件,用来标明训练时候的train数据集、val数据集和test数据集
Layout
Segmentation
- Annotation ==》》 存放一些xml文件,xml文件中包含相对应的bounding box位置信息,以及类别,每个xml文件对应JPEGImages文件夹中的一张图片。内容如下:
<?xml version="1.0"?>-<annotation><folder>VOC2007</folder><filename>000001.jpg</filename>-<source><database>The VOC2007 Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image><flickrid>341012865</flickrid></source>-<owner><flickrid>Fried Camels</flickrid><name>Jinky the Fruit Bat</name></owner>-<size><width>353</width><height>500</height><depth>3</depth></size><segmented>0</segmented>-<object><name>dog</name><pose>Left</pose><truncated>1</truncated><difficult>0</difficult>-<bndbox><xmin>48</xmin><ymin>240</ymin><xmax>195</xmax><ymax>371</ymax></bndbox></object>-<object><name>person</name><pose>Left</pose><truncated>1</truncated><difficult>0</difficult>-<bndbox><xmin>8</xmin><ymin>12</ymin><xmax>352</xmax><ymax>498</ymax></bndbox></object></annotation>
3. 转换成JPG格式
因为voc是JPG格式的,还没拿去训练不知道PNG格式的会不会有影响,所以先转换成JPG格式以防万一。采用格式工厂批量处理,一次只能999张图片,所以要先划分出各个文件夹方便处理。PS也可以通过动作和录制功能批处理,不过效率有点慢就没采用。
4. 创建VOC2007文件夹
在JPEGImages放入转换完成的train图片的JPG图片(有博客说直接将下载的PNG放入,但有test和train两个文件夹,查看原voc2007文件夹,发现里面只有train的图片,于是只放入转换完成的trainJPG图片)。
在ImageSet文件夹里创建如下3个文件夹。
第二部分:转换数据集
1. 介绍
这部分主要还是参考micro wen的博客。之前看的时候实验做起来很简单,不过还是要认真看一下代码。看代码时候就很多不懂,所以更新了代码备注,希望能帮到有需要的人。
由于“DontCare”,“Misc”,“Cyclist”三个类别在图片中太小且标注信息也不准确,在转换的时候需要将其忽略。根据之前的博客还将“Person_sitting”和“Pedestrian”合并为一个类别,统一标记为“Pedestrian”。采用python语言进行转换。
创建的python文件我是放在和label同一级目录下,不过把代码里的绝对路径写好应该也可以放在别的地方。
2. 转换kitti数据集类别
创建python文件modify_kitti_type.py
# -*-coding:utf-8-*-import glob
import string# glob: return document/file path
# 存储Labels文件夹所有txt文件路径,Win下修改路径要注意反斜杠用法,不要用成\
txt_list = glob.glob('E:/111/rpntrain-data/data_object_label_2/training/label_2/*.txt')# 输出所有文件中的物体类别
def show_category(txt_list):category_list = []for item in txt_list:try:with open(item) as tdf:for each_line in tdf:labeldata = each_line.strip().split(' ') # 去掉前后多余的字符并把其分开category_list.append(labeldata[0]) # 只要第一个字段,即类别except IOError as ioerr:print('File error:' + str(ioerr))print(set(category_list)) # 输出集合# 这里是将每个文件的每行写入line中
def merge(line):# 列表推导式(又称列表解析式)提供了一种简明扼要的方法来创建列表,# 它是利用其创建新列表list的一个简单方法。列表推导式比较像for循环语句,# 必要时也可以加入if条件语句完善推导式。each_line = ''# add space to last word in each linefor i in range(len(line)):if i != (len(line) - 1):each_line = each_line + line[i] + ' 'else:each_line = each_line + line[i] # 最后一条字段后面不加空格each_line = each_line + '\n'return (each_line)# print('before modify categories are:\n')
print('在修改类别之前:\n')
# 显示原有的类别
show_category(txt_list)# item为当前操作的文件,
for item in txt_list: new_txt = []try:# with as是控制流语句,可以处理异常而不用多写代码# 对item进行读取with open(item, 'r') as r_tdf:for each_line in r_tdf:# 实际上strip是删除的意思;而split则是分割的意思。因此也表示了这两个功能是完全不一样的,# strip可以删除字符串的某些字符,而split则是根据规定的字符将字符串进行分割。labeldata = each_line.strip().split(' ')'''if labeldata[0] in ['Truck','Van','Tram','Car']: # 合并汽车类 labeldata[0] = labeldata[0].replace(labeldata[0],'car') if labeldata[0] in ['Person_sitting','Cyclist','Pedestrian']: # 合并行人类 labeldata[0] = labeldata[0].replace(labeldata[0],'pedestrian')'''# print type(labeldata[4])# Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01# 没有研究label里数字具体的意思,直接使用前人的代码if labeldata[4] == '0.00':labeldata[4] = labeldata[4].replace(labeldata[4], '1.00')if labeldata[5] == '0.00':labeldata[5] = labeldata[5].replace(labeldata[5], '1.00')# 如果当前行0位置为truck则进行替换,使用小写怕训练时候出错if labeldata[0] == 'Truck':labeldata[0] = labeldata[0].replace(labeldata[0], 'truck')if labeldata[0] == 'Van':labeldata[0] = labeldata[0].replace(labeldata[0], 'van')if labeldata[0] == 'Tram':labeldata[0] = labeldata[0].replace(labeldata[0], 'tram')if labeldata[0] == 'Car':labeldata[0] = labeldata[0].replace(labeldata[0], 'car')if labeldata[0] in ['Person_sitting', 'Pedestrian']: # 合并行人类labeldata[0] = labeldata[0].replace(labeldata[0], 'pedestrian')if labeldata[0] == 'Cyclist':continueif labeldata[0] == 'DontCare': # 忽略Dontcare类continueif labeldata[0] == 'Misc': # 忽略Misc类continuenew_txt.append(merge(labeldata)) # 重新写入新的txt文件with open(item, 'w+') as w_tdf: # w+是打开原文件将内容删除,另写新内容进去for temp in new_txt:w_tdf.write(temp)except IOError as ioerr:print('File error:' + str(ioerr))# 显示处理后的种类,这里已经完成了对label的修改
print('\nafter modify categories are:\n')
show_category(txt_list)
3. 转换标注信息格式:txt到xml
处理完原始的txt文件后,接下来需要将标签集的txt标注文件转换成xml文件。去掉标注信息中用不上的部分,把坐标值从float类型转化为int类型,最后代码会将生成的xml文件存放到VOC数据集的Annotations文件夹中。创建python文件txt_to_xml.py
#-*-coding:utf-8-*-
# 根据一个给定的XML Schema,使用DOM树的形式从空白文件生成一个XML
from xml.dom.minidom import Document
# python3.7下安装cv2,本机不能直接pip安装,搜索安装包进行安装
import cv2
import os# 传入序号,
def generate_xml(name,split_lines,img_size,class_ind):doc = Document() # 创建DOM文档对象# 问题:创建document对象,如果存在则会把文件价名加在里面的文件前面?# 上述问题是在写路径时候Annotations没加反斜杠annotation = doc.createElement('annotation')# appendChild方法的规定就是向节点添加最后一个子节点。doc.appendChild(annotation)# 测试输出文件位置问题# print("document start")# 这里开始写入XML,可具体看每个xml的内容title = doc.createElement('folder')title_text = doc.createTextNode('VOC2007')#这里修改了文件夹名# appendChild:添加子节点title.appendChild(title_text)annotation.appendChild(title)# img_name=name+'.png'#要用jpg格式img_name = name + '.jpg'title = doc.createElement('filename')title_text = doc.createTextNode(img_name)title.appendChild(title_text)annotation.appendChild(title)source = doc.createElement('source')annotation.appendChild(source)title = doc.createElement('database')title_text = doc.createTextNode('The VOC2007 Database')#修改为VOCtitle.appendChild(title_text)source.appendChild(title)title = doc.createElement('annotation')title_text = doc.createTextNode('PASCAL VOC2007')#修改为VOCtitle.appendChild(title_text)source.appendChild(title)size = doc.createElement('size')annotation.appendChild(size)title = doc.createElement('width')title_text = doc.createTextNode(str(img_size[1]))title.appendChild(title_text)size.appendChild(title)title = doc.createElement('height')title_text = doc.createTextNode(str(img_size[0]))title.appendChild(title_text)size.appendChild(title)title = doc.createElement('depth')title_text = doc.createTextNode(str(img_size[2]))title.appendChild(title_text)size.appendChild(title)for split_line in split_lines:line=split_line.strip().split()if line[0] in class_ind:object = doc.createElement('object')annotation.appendChild(object)title = doc.createElement('name')title_text = doc.createTextNode(line[0])title.appendChild(title_text)object.appendChild(title)title = doc.createElement('difficult')title_text = doc.createTextNode('0')title.appendChild(title_text)object.appendChild(title)bndbox = doc.createElement('bndbox')object.appendChild(bndbox)title = doc.createElement('xmin')title_text = doc.createTextNode(str(int(float(line[4]))))title.appendChild(title_text)bndbox.appendChild(title)title = doc.createElement('ymin')title_text = doc.createTextNode(str(int(float(line[5]))))title.appendChild(title_text)bndbox.appendChild(title)title = doc.createElement('xmax')title_text = doc.createTextNode(str(int(float(line[6]))))title.appendChild(title_text)bndbox.appendChild(title)title = doc.createElement('ymax')title_text = doc.createTextNode(str(int(float(line[7]))))title.appendChild(title_text)bndbox.appendChild(title)# 将DOM对象doc写入文件f = open('E:/111/rpntrain-data/VOC2007/Annotations/' + name + '.xml', 'w')f.write(doc.toprettyxml(indent = ''))f.close()if __name__ == '__main__':class_ind=('van', 'tram', 'car', 'pedestrian', 'truck')# 修改为了5类# cur_dir=os.getcwd()# 这个路径是label的上一层,不加反斜杠labels_dir = os.path.join("E:/111/rpntrain-data/data_object_label_2/training", 'label_2')# os.walk方法,主要用来遍历一个目录内各个子目录和子文件for parent, dirnames, filenames in os.walk(labels_dir): # 分别得到根目录,子目录和根目录下文件# 对于根目录下的文件,先取得路径得到前面的文件序号,再生成新的xmlfor file_name in filenames:full_path=os.path.join(parent, file_name) # 获取文件全路径#print full_pathf=open(full_path)# 读取所有行split_lines = f.readlines()name= file_name[:-4] # 后四位是扩展名.txt,只取前面的文件名#print nameimg_name = name + '.jpg'# 将要训练的图片路径添加入img_path中img_path = os.path.join('E:/111/rpntrain-data/VOC2007/JPEGImage/trianing', img_name)#print img_pathimg_size=cv2.imread(img_path).shape# 文件序号,每一行,图片大小,目标类别generate_xml(name,split_lines,img_size,class_ind)
print('all txts has converted into xmls')4. 生成训练验证集和测试集列表
创建python文件generate_train_test_txt.py
#-*-coding:utf-8-*-
# 生成训练验证集和测试集列表import pdb
import glob
import os
import random
import math# 这个函数是传入要比较的标签类别和查询原图是否有这个标签
def get_sample_value(txt_name, category_name):# kitti数据集的label位置label_path = 'E:/111/rpntrain-data/data_object_label_2/training/label_2/'# 建立路径,用于记录哪个训练/测试用的数据集搭配哪个种类的文件名txt_path = label_path + txt_name+'.txt'try:with open(txt_path) as r_tdf:# 如果当前的这个种类在label里有则返回1,用于上层记录是否归属该类别if category_name in r_tdf.read():return ' 1'else:return '-1'except IOError as ioerr:print('File error:'+str(ioerr))# glob文件搜索,找到符合这个路径的路径
# 也有博客有这个写法:txt_list_path = glob.glob('./Labels/*.txt')
txt_list_path = glob.glob('E:/111/rpntrain-data/data_object_label_2/training/label_2/*.txt')
# 用于下文记录txt的所有文件名
txt_list = []for item in txt_list_path:# 分离路径名和文件名temp1,temp2 = os.path.splitext(os.path.basename(item))# 将文件名加入到这个数组里txt_list.append(temp1)
# 对文件名进行排序
txt_list.sort()
# 控制台里显示所有的文件名
print(txt_list, end = '\n\n')# 有博客建议train:val:test=8:1:1,先尝试用一下
# 思路是将trainval分得9份,8份给train,1份给val。
# val用于训练时候验证集,也就是训练结束时得到的准确率。和测试集不一样# random.sample多用于截取列表的指定长度的随机数,但是不会改变列表本身的排序
# math.floor是得到小于或者等于参数的最大整数
num_trainval = random.sample(txt_list, math.floor(len(txt_list)*9/10.0)) # 可修改百分比
num_trainval.sort()
print(num_trainval, end = '\n\n')num_train = random.sample(num_trainval,math.floor(len(num_trainval)*8/9.0)) # 可修改百分比
num_train.sort()
print(num_train, end = '\n\n')# 这里用set().difference()得到和刚才得到trian数据集不一样的部分,也就是9份里的剩下1份
num_val = list(set(num_trainval).difference(set(num_train)))
num_val.sort()
print(num_val, end = '\n\n')num_test = list(set(txt_list).difference(set(num_trainval)))
num_test.sort()
print(num_test, end = '\n\n')# pdb.set_trace()# 自己创建VOC里imagesets的Main_path文件夹路径
Main_path = 'E:/111/rpntrain-data/VOC2007/ImageSets/Main/'
# 数据集种类,用于区分训练和测试用
train_test_name = ['trainval','train','val','test']
# 数据集里的各个类别
category_name = ['van', 'tram', 'car', 'pedestrian', 'truck']#修改类别# 循环写trainvl train val test
for item_train_test_name in train_test_name:list_name = 'num_'# 这个num_加上数据集种类,可以得到上文8:1:1里的各个数据集名称list_name += item_train_test_name# 创建数据集种类的文件,记录这个种类都有哪些照片train_test_txt_name = Main_path + item_train_test_name + '.txt'try:# 写单个文件with open(train_test_txt_name, 'w') as w_tdf:# 一行一行写,eval是读取这个list的内容,也就是数据集种类里的照片名# 最终能得到四类:trainval.txt之类的四个for item in eval(list_name):w_tdf.write(item+'\n')# 循环写Car Pedestrian Cyclistfor item_category_name in category_name:# 得到:路径+car+_+trainval+.txt的文件部分,# 也就是数据类别在当前数据集的分类数据判断,如00001 1为含有该类00002 -1为不含该类category_txt_name = Main_path + item_category_name + '_' + item_train_test_name + '.txt'with open(category_txt_name, 'w') as w_tdf:# 一行一行写,记录照片标号和该照片是否属于该类别for item in eval(list_name):w_tdf.write(item+' '+ get_sample_value(item, item_category_name)+'\n')except IOError as ioerr:print('File error:'+str(ioerr))
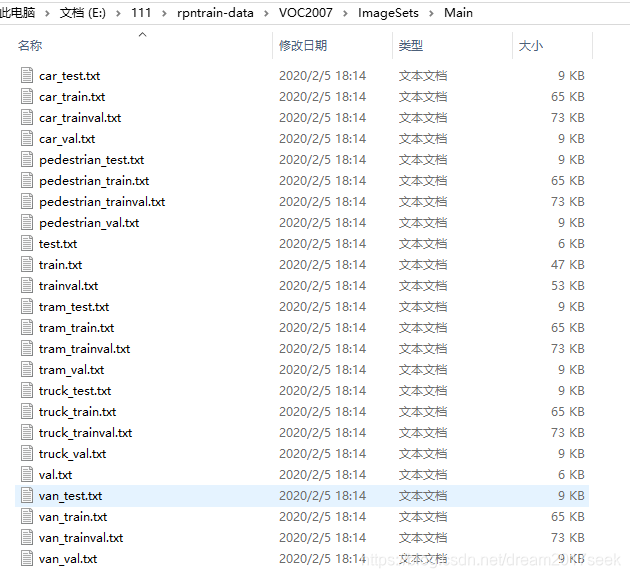
生成的txt文件如下:
至此训练车联网需要的数据集就准备好了。因为还不能回学校,所以进行训练的过程只能等以后了。
参考链接
https://blog.csdn.net/xw_2_xh/article/details/86617595
https://blog.csdn.net/flztiii/article/details/73881954
https://blog.csdn.net/u014256231/article/details/79801665
这篇关于kitti数据集转换成voc数据集格式(rpn训练三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




