本文主要是介绍java 从零开始手写 redis(十)缓存淘汰算法 LFU 最少使用频次,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
java从零手写实现redis(一)如何实现固定大小的缓存?
java从零手写实现redis(三)redis expire 过期原理
java从零手写实现redis(三)内存数据如何重启不丢失?
java从零手写实现redis(四)添加监听器
java从零手写实现redis(五)过期策略的另一种实现思路
java从零手写实现redis(六)AOF 持久化原理详解及实现
java从零手写实现redis(七)LRU 缓存淘汰策略详解
从零开始手写 redis(八)朴素 LRU 淘汰算法性能优化
本节一起来学习下另一个常用的缓存淘汰算法,LFU 最少使用频次算法。
LFU 基础知识
概念
LFU(Least Frequently Used)即最近最不常用.看名字就知道是个基于访问频次的一种算法。
LRU是基于时间的,会将时间上最不常访问的数据给淘汰,在算法表现上是放到列表的顶部;LFU为将频率上最不常访问的数据淘汰.
既然是基于频率的,就需要有存储每个数据访问的次数.
从存储空间上,较LRU会多出一些持有计数的空间.
核心思想
如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小。
实现思路
O(N) 的删除
为了能够淘汰最少使用的数据,个人第一直觉就是直接一个 HashMap<String, Interger>, String 对应 key 信息,Integer 对应次数。
每次访问到就去+1,设置和读取的时间复杂度都是 O(1);不过删除就比较麻烦了,需要全部遍历对比,时间复杂度为 O(n);
O(logn) 的删除
另外还有一种实现思路就是利用小顶堆+hashmap,小顶堆插入、删除操作都能达到O(logn)时间复杂度,因此效率相比第一种实现方法更加高效。比如 TreeMap。
O(1) 的删除
是否能够更进一步优化呢?
其实 O(1) 的算法是有的,参见这篇 paper:
An O(1) algorithm for implementing the LFU cache eviction scheme
简单说下个人的想法:
我们要想实现 O(1) 的操作,肯定离不开 Hash 的操作,我们 O(N) 的删除中就实现了 O(1) 的 put/get。
但是删除性能比较差,因为需要寻找次数最少的比较耗时。
private Map<K, Node> map; // key和数据的映射
private Map<Integer, LinkedHashSet<Node>> freqMap; // 数据频率和对应数据组成的链表class Node {K key;V value;int frequency = 1;
}
我们使用双 Hash 基本上就可以解决这个问题了。
map 中存放 key 和节点之间的映射关系。put/get 肯定都是 O(1) 的。
key 映射的 node 中,有对应的频率 frequency 信息;相同的频率都会通过 freqMap 进行关联,可以快速通过频率获取对应的链表。
删除也变得非常简单了,基本可以确定需要删除的最低频次是1,如果不是最多从 1…n 开始循环,最小 freq 选择链表的第一个元素开始删除即可。
至于链表本身的优先级,那么可以根据 FIFO,或者其他你喜欢的方式。
paper 的核心内容介绍
他山之石,可以攻玉。
我们在实现代码之前,先来读一读这篇 O(1) 的 paper。
介绍
本文的结构如下。
对LFU用例的描述,它可以证明优于其他缓存逐出算法
LFU缓存实现应支持的字典操作。 这些是确定策略运行时复杂度的操作
当前最著名的LFU算法及其运行时复杂度的描述
提出的LFU算法的说明; 每个操作的运行时复杂度为O(1)
LFU的用途
考虑用于HTTP协议的缓存网络代理应用程序。
该代理通常位于Internet与用户或一组用户之间。
它确保所有用户都能够访问Internet,并实现所有可共享资源的共享,以实现最佳的网络利用率和响应速度。
这样的缓存代理应该尝试在可支配的有限数量的存储或内存中最大化其可以缓存的数据量。
通常,在将静态资源(例如图像,CSS样式表和javascript代码)替换为较新版本之前,可以很容易地将它们缓存很长时间。
这些静态资源或程序员所谓的“资产”几乎包含在每个页面中,因此缓存它们是最有益的,因为几乎每个请求都将需要它们。
此外,由于要求网络代理每秒处理数千个请求,因此应将这样做所需的开销保持在最低水平。
为此,它应该仅驱逐那些不经常使用的资源。
因此,应该将经常使用的资源保持在不那么频繁使用的资源上,因为前者已经证明自己在一段时间内是有用的。
当然,有一个说法与之相反,它说将来可能不需要大量使用的资源,但是我们发现在大多数情况下情况并非如此。
例如,频繁使用页面的静态资源始终由该页面的每个用户请求。
因此,当内存不足时,这些缓存代理可以使用LFU缓存替换策略来驱逐其缓存中使用最少的项目。
LRU在这里也可能是适用的策略,但是当请求模式使得所有请求的项目都没有进入缓存并且以循环方式请求这些项目时,LRU将会失败。
ps: 数据的循环请求,会导致 LRU 刚好不适应这个场景。
在使用LRU的情况下,项目将不断进入和离开缓存,而没有用户请求访问缓存。
但是,在相同条件下,LFU算法的性能会更好,大多数缓存项会导致缓存命中。
LFU算法的病理行为并非没有可能。
我们不是在这里提出LFU的案例,而是试图证明如果LFU是适用的策略,那么比以前发布的方法有更好的实现方法。
LFU缓存支持的字典操作
当我们谈到缓存逐出算法时,我们主要需要对缓存数据进行3种不同的操作。
-
在缓存中设置(或插入)项目
-
检索(或查找)缓存中的项目; 同时增加其使用计数(对于LFU)
-
从缓存中逐出(或删除)最少使用(或作为逐出算法的策略)
LFU算法的当前最著名的复杂性
在撰写本文时,针对LFU缓存逐出策略的上述每个操作的最著名的运行时如下:
插入:O(log n)
查找:O(log n)
删除:O(log n)
这些复杂度值直接从二项式堆实现和标准无冲突哈希表中获得。
使用最小堆数据结构和哈希图可以轻松有效地实施LFU缓存策略。
最小堆是基于(项目的)使用计数创建的,并且通过元素的键为哈希表建立索引。
无冲突哈希表上的所有操作的顺序均为O(1),因此LFU缓存的运行时间由最小堆上的操作的运行时间控制。
将元素插入高速缓存时,它将以1的使用计数进入,由于插入最小堆的开销为O(log n),因此将其插入LFU高速缓存需要O(log n)时间。
在查找元素时,可以通过哈希函数找到该元素,该哈希函数将键哈希到实际元素。同时,使用计数(最大堆中的计数)加1,这导致最小堆的重组,并且元素从根移开。
由于元素在任何阶段都可以向下移动至log(n)电平,因此此操作也需要时间O(log n)。
当选择一个元素将其逐出并最终从堆中删除时,它可能导致堆数据结构的重大重组。
使用计数最少的元素位于最小堆的根。
删除最小堆的根包括将根节点替换为堆中的最后一个叶节点,并将该节点起泡到正确的位置。
此操作的运行时复杂度也为O(log n)。
提出的LFU算法
对于可以在LFU缓存上执行的每个字典操作(插入,查找和删除),提出的LFU算法的运行时复杂度为O(1)。
这是通过维护2个链接列表来实现的。一个用于访问频率,另一个用于具有相同访问频率的所有元素。
哈希表用于按键访问元素(为清楚起见,下图中未显示)。
双链表用于将代表一组具有相同访问频率的节点的节点链接在一起(在下图中显示为矩形块)。
我们将此双重链接列表称为频率列表。具有相同访问频率的这组节点实际上是此类节点的双向链接列表(在下图中显示为圆形节点)。
我们将此双向链接列表(在特定频率本地)称为节点列表。
节点列表中的每个节点都有一个指向其父节点的指针。
频率列表(为清楚起见,未在图中显示)。因此,节点x和您将有一个指向节点1的指针,节点z和a将有一个指向节点2的指针,依此类推…
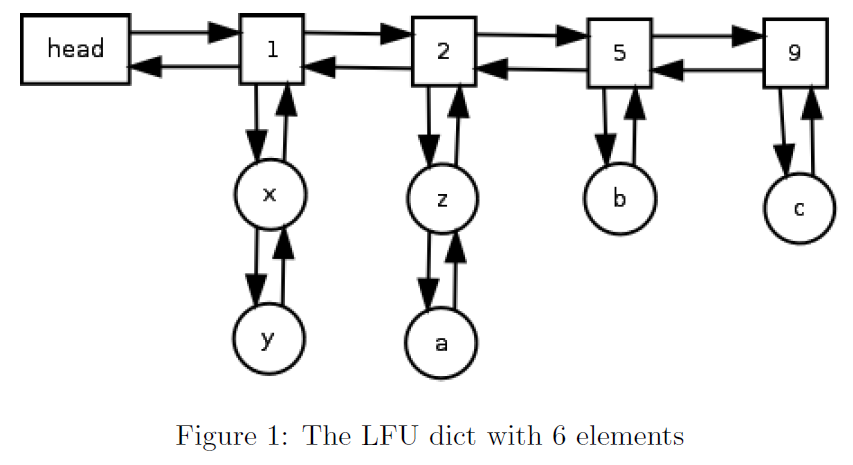
下面的伪代码显示了如何初始化LFU缓存。
用于按键定位元素的哈希表由按键变量表示。
为了简化实现,我们使用SET代替链表来存储具有相同访问频率的元素。
变量项是标准的SET数据结构,其中包含具有相同访问频率的此类元素的键。
它的插入,查找和删除运行时复杂度为O(1)。

伪代码
后面的都是一些伪代码了,我们条国内。
理解其最核心的思想就行了,下面我们上真代码。
感受
这个 O(1) 的算法最核心的地方实际上不多,放在 leetcode 应该算是一个中等难度的题目。
不过很奇怪,这篇论文是在 2010 年提出的,估计以前都以为 O(logn) 是极限了?
java 代码实现
基本属性
public class CacheEvictLfu<K,V> extends AbstractCacheEvict<K,V> {private static final Log log = LogFactory.getLog(CacheEvictLfu.class);/*** key 映射信息* @since 0.0.14*/private final Map<K, FreqNode<K,V>> keyMap;/*** 频率 map* @since 0.0.14*/private final Map<Integer, LinkedHashSet<FreqNode<K,V>>> freqMap;/**** 最小频率* @since 0.0.14*/private int minFreq;public CacheEvictLfu() {this.keyMap = new HashMap<>();this.freqMap = new HashMap<>();this.minFreq = 1;}}
节点定义
- FreqNode.java
public class FreqNode<K,V> {/*** 键* @since 0.0.14*/private K key;/*** 值* @since 0.0.14*/private V value = null;/*** 频率* @since 0.0.14*/private int frequency = 1;public FreqNode(K key) {this.key = key;}//fluent getter & setter// toString() equals() hashCode()
}
移除元素
/*** 移除元素** 1. 从 freqMap 中移除* 2. 从 keyMap 中移除* 3. 更新 minFreq 信息** @param key 元素* @since 0.0.14*/
@Override
public void removeKey(final K key) {FreqNode<K,V> freqNode = this.keyMap.remove(key);//1. 根据 key 获取频率int freq = freqNode.frequency();LinkedHashSet<FreqNode<K,V>> set = this.freqMap.get(freq);//2. 移除频率中对应的节点set.remove(freqNode);log.debug("freq={} 移除元素节点:{}", freq, freqNode);//3. 更新 minFreqif(CollectionUtil.isEmpty(set) && minFreq == freq) {minFreq--;log.debug("minFreq 降低为:{}", minFreq);}
}
更新元素
/*** 更新元素,更新 minFreq 信息* @param key 元素* @since 0.0.14*/
@Override
public void updateKey(final K key) {FreqNode<K,V> freqNode = keyMap.get(key);//1. 已经存在if(ObjectUtil.isNotNull(freqNode)) {//1.1 移除原始的节点信息int frequency = freqNode.frequency();LinkedHashSet<FreqNode<K,V>> oldSet = freqMap.get(frequency);oldSet.remove(freqNode);//1.2 更新最小数据频率if (minFreq == frequency && oldSet.isEmpty()) {minFreq++;log.debug("minFreq 增加为:{}", minFreq);}//1.3 更新频率信息frequency++;freqNode.frequency(frequency);//1.4 放入新的集合this.addToFreqMap(frequency, freqNode);} else {//2. 不存在//2.1 构建新的元素FreqNode<K,V> newNode = new FreqNode<>(key);//2.2 固定放入到频率为1的列表中this.addToFreqMap(1, newNode);//2.3 更新 minFreq 信息this.minFreq = 1;//2.4 添加到 keyMapthis.keyMap.put(key, newNode);}
}/*** 加入到频率 MAP* @param frequency 频率* @param freqNode 节点*/
private void addToFreqMap(final int frequency, FreqNode<K,V> freqNode) {LinkedHashSet<FreqNode<K,V>> set = freqMap.get(frequency);if (set == null) {set = new LinkedHashSet<>();}set.add(freqNode);freqMap.put(frequency, set);log.debug("freq={} 添加元素节点:{}", frequency, freqNode);
}
数据淘汰
@Override
protected ICacheEntry<K, V> doEvict(ICacheEvictContext<K, V> context) {ICacheEntry<K, V> result = null;final ICache<K,V> cache = context.cache();// 超过限制,移除频次最低的元素if(cache.size() >= context.size()) {FreqNode<K,V> evictNode = this.getMinFreqNode();K evictKey = evictNode.key();V evictValue = cache.remove(evictKey);log.debug("淘汰最小频率信息, key: {}, value: {}, freq: {}",evictKey, evictValue, evictNode.frequency());result = new CacheEntry<>(evictKey, evictValue);}return result;
}/*** 获取最小频率的节点** @return 结果* @since 0.0.14*/
private FreqNode<K, V> getMinFreqNode() {LinkedHashSet<FreqNode<K,V>> set = freqMap.get(minFreq);if(CollectionUtil.isNotEmpty(set)) {return set.iterator().next();}throw new CacheRuntimeException("未发现最小频率的 Key");
}
测试
代码
ICache<String, String> cache = CacheBs.<String,String>newInstance().size(3).evict(CacheEvicts.<String, String>lfu()).build();
cache.put("A", "hello");
cache.put("B", "world");
cache.put("C", "FIFO");
// 访问一次A
cache.get("A");
cache.put("D", "LRU");Assert.assertEquals(3, cache.size());
System.out.println(cache.keySet());
日志
[DEBUG] [2020-10-03 21:23:43.722] [main] [c.g.h.c.c.s.e.CacheEvictLfu.addToFreqMap] - freq=1 添加元素节点:FreqNode{key=A, value=null, frequency=1}
[DEBUG] [2020-10-03 21:23:43.723] [main] [c.g.h.c.c.s.e.CacheEvictLfu.addToFreqMap] - freq=1 添加元素节点:FreqNode{key=B, value=null, frequency=1}
[DEBUG] [2020-10-03 21:23:43.725] [main] [c.g.h.c.c.s.e.CacheEvictLfu.addToFreqMap] - freq=1 添加元素节点:FreqNode{key=C, value=null, frequency=1}
[DEBUG] [2020-10-03 21:23:43.727] [main] [c.g.h.c.c.s.e.CacheEvictLfu.addToFreqMap] - freq=2 添加元素节点:FreqNode{key=A, value=null, frequency=2}
[DEBUG] [2020-10-03 21:23:43.728] [main] [c.g.h.c.c.s.e.CacheEvictLfu.doEvict] - 淘汰最小频率信息, key: B, value: world, freq: 1
[DEBUG] [2020-10-03 21:23:43.731] [main] [c.g.h.c.c.s.l.r.CacheRemoveListener.listen] - Remove key: B, value: world, type: evict
[DEBUG] [2020-10-03 21:23:43.732] [main] [c.g.h.c.c.s.e.CacheEvictLfu.addToFreqMap] - freq=1 添加元素节点:FreqNode{key=D, value=null, frequency=1}
[D, A, C]
LFU vs LRU
区别
LFU是基于访问频次的模式,而LRU是基于访问时间的模式。
优势
在数据访问符合正态分布时,相比于LRU算法,LFU算法的缓存命中率会高一些。
劣势
-
LFU的复杂度要比LRU更高一些。
-
需要维护数据的访问频次,每次访问都需要更新。
-
早期的数据相比于后期的数据更容易被缓存下来,导致后期的数据很难被缓存。
-
新加入缓存的数据很容易被剔除,像是缓存的末端发生“抖动”。
小结
不过实际实践中,LFU 的应用场景实际并没有那么广泛。
因为真实的数据都是有倾斜的,热点数据才是常态,所以 LRU 的性能一般情况下优于 LFU。
开源地址:https://github.com/houbb/cache
觉得本文对你有帮助的话,欢迎点赞评论收藏关注一波,你的鼓励,是我最大的动力~
目前我们实现了性能比较优异的 LRU 和 LFU 算法,但是操作系统实际采用的却不是这两种算法,我们下一节将一起学习下操作系统青睐的 clock 淘汰算法。
不知道你有哪些收获呢?或者有其他更多的想法,欢迎留言区和我一起讨论,期待与你的思考相遇。

这篇关于java 从零开始手写 redis(十)缓存淘汰算法 LFU 最少使用频次的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






