本文主要是介绍oracle之优化一用group by或exists优化distinct,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天mentor给了一个sql语句优化的任务。(环境是sql developer)有一个语句执行很慢,查询出来的结果有17544条记录,但需970秒,速度很慢。语句是这样的:
SELECT DISTINCT 'AMEND_NEW',reporttitle,reportsubtitle,cab_cab_transactions.branchcode,cab_cab_transactions.prtfo_cd,cab_cab_transactions.sstm_scrty_id,cab_cab_transactions.sstm_trx_id,cab_cab_transactions.trde_dttm,cab_cab_transactions.efcte_dttm,cab_cab_transactions.due_stlmnt_dt,cab_cab_transactions.cncl_efcte_dttm,cab_cab_transactions.trde_sstm_id,cab_cab_transactions.trx_type_cd,cab_cab_transactions.trx_type_dscrn,cab_cab_transactions.trx_subtype_cd,cab_cab_transactions.trde_stat_flg,cab_cab_transactions.csh_cr_dr_indcr,cab_cab_transactions.long_shrt_indcr,cab_cab_transactions.lcl_crncy,cab_cab_transactions.stlmt_crncy,cab_cab_transactions.nomin_qty,cab_cab_transactions.price,cab_cab_transactions.lcl_cst,cab_cab_transactions.prtfo_cst,cab_cab_transactions.lcl_book_cst,cab_cab_transactions.prtfo_book_cst,cab_cab_transactions.lcl_sell_prcds,cab_cab_transactions.prtfo_sell_prcds,cab_cab_transactions.lcl_gnls,cab_cab_transactions.prtfo_gnls,cab_cab_transactions.lcl_acrd_intrt,cab_cab_transactions.prtfo_acrd_intrt,cab_cab_transactions.stlmt_crncy_stlmt_amt,cab_cab_transactions.lcl_net_amt,cab_cab_transactions.prtfo_net_amt,cab_cab_transactions.fx_bght_amt,cab_cab_transactions.fx_sold_amt,cab_cab_transactions.prtfo_crncy_stlmt_amt,cab_cab_transactions.prtfo_net_incme,cab_cab_transactions.dvnd_crncy_net_incme,cab_cab_transactions.dvnd_type_cd,cab_cab_transactions.lcl_intrt_pd_rec,cab_cab_transactions.prtfo_intrt_pd_rec,cab_cab_transactions.lcl_dvdnd_pd_rec,cab_cab_transactions.prtfo_dvdnd_pd_rec,cab_cab_transactions.lcl_sundry_inc_pd_rec,cab_cab_transactions.prtfo_sundry_inc_pd_rec,cab_cab_transactions.bnk_csh_cptl_secid,cab_cab_transactions.bnk_csh_inc_secid,cab_cab_transactions.reportdate,cab_cab_transactions.filename,sysdate,'e483448'FROM cab_cfg_trx_type_mapping RIGHT JOIN(cab_cab_tran_adjustmentsINNER JOIN cab_cab_transactions ON(cab_cab_transactions.branchcode = cab_cab_tran_adjustments.branchcode )AND(cab_cab_tran_adjustments.sstm_trx_id = cab_cab_transactions.sstm_trx_id)) ON(cab_cfg_trx_type_mapping.cab_trx_type_cd = cab_cab_transactions.trx_type_cd)AND(nvl(cab_cfg_trx_type_mapping.cab_trx_subtype_cd,' ') = nvl(cab_cab_transactions.trx_subtype_cd,' ')AND (cab_cfg_trx_type_mapping.branchcode=cab_cab_transactions.branchcode))WHERE cab_cab_transactions.prtfo_cd IN(SELECT DISTINCT prtfo_cdFROM cab_cab_valuations_workingWHERE created_by = 'e483448'AND branchcode='ISA')AND cab_cab_tran_adjustments.efcte_dttm > '2011-07-31'AND cab_cab_tran_adjustments.efcte_dttm <= '2011-08-31'AND eff_trde_stat_flg <> 'X'AND cab_cab_transactions.branchcode = 'ISA'AND cab_cab_tran_adjustments.branchcode = 'ISA'AND(cab_cfg_trx_type_mapping.cab_reportgroup = 'CABValuation' OR cab_cfg_trx_type_mapping.cab_reportgroup IS NULL)
问题在distinct上面,它会导致对全表扫描,而且会导致排序,然后删除重复的记录,所以速度很慢,因此需要优化distinct。查了不少资料,并逐一尝试,最后发现了一个非常可观的优化结果,用group by。语句如下:
SELECT 'AMEND_NEW',reporttitle,reportsubtitle,cab_cab_transactions.branchcode,cab_cab_transactions.prtfo_cd,cab_cab_transactions.sstm_scrty_id,cab_cab_transactions.sstm_trx_id,cab_cab_transactions.trde_dttm,cab_cab_transactions.efcte_dttm,cab_cab_transactions.due_stlmnt_dt,cab_cab_transactions.cncl_efcte_dttm,cab_cab_transactions.trde_sstm_id,cab_cab_transactions.trx_type_cd,cab_cab_transactions.trx_type_dscrn,cab_cab_transactions.trx_subtype_cd,cab_cab_transactions.trde_stat_flg,cab_cab_transactions.csh_cr_dr_indcr,cab_cab_transactions.long_shrt_indcr,cab_cab_transactions.lcl_crncy,cab_cab_transactions.stlmt_crncy,cab_cab_transactions.nomin_qty,cab_cab_transactions.price,cab_cab_transactions.lcl_cst,cab_cab_transactions.prtfo_cst,cab_cab_transactions.lcl_book_cst,cab_cab_transactions.prtfo_book_cst,cab_cab_transactions.lcl_sell_prcds,cab_cab_transactions.prtfo_sell_prcds,cab_cab_transactions.lcl_gnls,cab_cab_transactions.prtfo_gnls,cab_cab_transactions.lcl_acrd_intrt,cab_cab_transactions.prtfo_acrd_intrt,cab_cab_transactions.stlmt_crncy_stlmt_amt,cab_cab_transactions.lcl_net_amt,cab_cab_transactions.prtfo_net_amt,cab_cab_transactions.fx_bght_amt,cab_cab_transactions.fx_sold_amt,cab_cab_transactions.prtfo_crncy_stlmt_amt,cab_cab_transactions.prtfo_net_incme,cab_cab_transactions.dvnd_crncy_net_incme,cab_cab_transactions.dvnd_type_cd,cab_cab_transactions.lcl_intrt_pd_rec,cab_cab_transactions.prtfo_intrt_pd_rec,cab_cab_transactions.lcl_dvdnd_pd_rec,cab_cab_transactions.prtfo_dvdnd_pd_rec,cab_cab_transactions.lcl_sundry_inc_pd_rec,cab_cab_transactions.prtfo_sundry_inc_pd_rec,cab_cab_transactions.bnk_csh_cptl_secid,cab_cab_transactions.bnk_csh_inc_secid,cab_cab_transactions.reportdate,cab_cab_transactions.filename,sysdate,'e483448'FROM cab_cfg_trx_type_mapping RIGHT JOIN(cab_cab_tran_adjustmentsINNER JOIN cab_cab_transactions ON(cab_cab_transactions.branchcode = cab_cab_tran_adjustments.branchcode )AND(cab_cab_tran_adjustments.sstm_trx_id = cab_cab_transactions.sstm_trx_id)) ON(cab_cfg_trx_type_mapping.cab_trx_type_cd = cab_cab_transactions.trx_type_cd)AND(nvl(cab_cfg_trx_type_mapping.cab_trx_subtype_cd,' ') = nvl(cab_cab_transactions.trx_subtype_cd,' ')AND (cab_cfg_trx_type_mapping.branchcode=cab_cab_transactions.branchcode))WHERE cab_cab_transactions.prtfo_cd IN(SELECT DISTINCT prtfo_cdFROM cab_cab_valuations_workingWHERE created_by = 'e483448'AND branchcode='ISA')AND cab_cab_tran_adjustments.efcte_dttm > '2011-07-31'AND cab_cab_tran_adjustments.efcte_dttm <= '2011-08-31'AND eff_trde_stat_flg <> 'X'AND cab_cab_transactions.branchcode = 'ISA'AND cab_cab_tran_adjustments.branchcode = 'ISA'AND(cab_cfg_trx_type_mapping.cab_reportgroup = 'CABValuation' OR cab_cfg_trx_type_mapping.cab_reportgroup IS NULL)GROUP BY reporttitle,reportsubtitle,cab_cab_transactions.branchcode,cab_cab_transactions.prtfo_cd,cab_cab_transactions.sstm_scrty_id,cab_cab_transactions.sstm_trx_id,cab_cab_transactions.trde_dttm,cab_cab_transactions.efcte_dttm,cab_cab_transactions.due_stlmnt_dt,cab_cab_transactions.cncl_efcte_dttm,cab_cab_transactions.trde_sstm_id,cab_cab_transactions.trx_type_cd,cab_cab_transactions.trx_type_dscrn,cab_cab_transactions.trx_subtype_cd,cab_cab_transactions.trde_stat_flg,cab_cab_transactions.csh_cr_dr_indcr,cab_cab_transactions.long_shrt_indcr,cab_cab_transactions.lcl_crncy,cab_cab_transactions.stlmt_crncy,cab_cab_transactions.nomin_qty,cab_cab_transactions.price,cab_cab_transactions.lcl_cst,cab_cab_transactions.prtfo_cst,cab_cab_transactions.lcl_book_cst,cab_cab_transactions.prtfo_book_cst,cab_cab_transactions.lcl_sell_prcds,cab_cab_transactions.prtfo_sell_prcds,cab_cab_transactions.lcl_gnls,cab_cab_transactions.prtfo_gnls,cab_cab_transactions.lcl_acrd_intrt,cab_cab_transactions.prtfo_acrd_intrt,cab_cab_transactions.stlmt_crncy_stlmt_amt,cab_cab_transactions.lcl_net_amt,cab_cab_transactions.prtfo_net_amt,cab_cab_transactions.fx_bght_amt,cab_cab_transactions.fx_sold_amt,cab_cab_transactions.prtfo_crncy_stlmt_amt,cab_cab_transactions.prtfo_net_incme,cab_cab_transactions.dvnd_crncy_net_incme,cab_cab_transactions.dvnd_type_cd,cab_cab_transactions.lcl_intrt_pd_rec,cab_cab_transactions.prtfo_intrt_pd_rec,cab_cab_transactions.lcl_dvdnd_pd_rec,cab_cab_transactions.prtfo_dvdnd_pd_rec,cab_cab_transactions.lcl_sundry_inc_pd_rec,cab_cab_transactions.prtfo_sundry_inc_pd_rec,cab_cab_transactions.bnk_csh_cptl_secid,cab_cab_transactions.bnk_csh_inc_secid,cab_cab_transactions.reportdate,cab_cab_transactions.filename
最后执行时间只有15.1秒,快了60多倍,不得不说这优化效果还是很可观的。不过查了很多资料,仍然没有发现合理地解释:为什么distinct 和group by的效率会有这么大差别。查的很多资料,讲的基本都是两者相差不大,实现也差不多。有待解决。
关于distinct 和group by的去重逻辑浅析
在数据库操作中,我们常常遇到需要将数据去重计数的工作。例如:
表A,列col
ACABCDAB结果就是一共出现4个不同的字母A、B、C、D
即结果为4
大体上我们可以选择count(distinct col)的方法和group+count的方法。
分别为:
select count(distinct col) from A;select count(1) from (select 1 from A group by col) alias;
两中方法实现有什么不同呢?
其实上述两中方法分别是在运算和存储上的权衡。
distinct需要将col列中的全部内容都存储在一个内存中,可以理解为一个hash结构,key为col的值,最后计算hash结构中有多少个key即可得到结果。
很明显,需要将所有不同的值都存起来。内存消耗可能较大。
而group by的方式是先将col排序。而数据库中的group一般使用sort的方法,即数据库会先对col进行排序。而排序的基本理论是,时间复杂为nlogn,空间为1.,然后只要单纯的计数就可以了。优点是空间复杂度小,缺点是要进行一次排序,执行时间会较长。
两中方法各有优劣,在使用的时候,我们需要根据实际情况进行取舍。
具体情况可参考如下法则
| 数据分布 | 去重方式 | 原因 |
|---|---|---|
| 离散 | group | distinct空间占用较大,在时间复杂度允许的情况下,group 可以发挥空间复杂度优势 |
| 集中 | distinct | distinct空间占用较小,可以发挥时间复杂度优势 |
两个极端:
1.数据列的所有数据都一样,即去重计数的结果为1时,用distinct最佳
2.如果数据列唯一,没有相同数值,用group 最好
当然,在group by时,某些数据库产品会根据数据列的情况智能地选择是使用排序去重还是hash去重,例如postgresql。当然,我们可以根据实际情况对执行计划进行人工的干预,而这不是这里要讨论的话题了。
使用EXISTS替换DISTINCT
当查询中包含的表之间有一对多的关系时,避免在SELECT子句中使用DISTICT,可以使用EXISTS替换。
--查询emp表中目前所有员工都在哪些部门工作(包括部门编号和部门名称)
--使用DISTINCT(低效)
SELECT DISTINCT d.deptno, d.dname FROM dept d, emp e WHERE d.deptno = e.deptno;
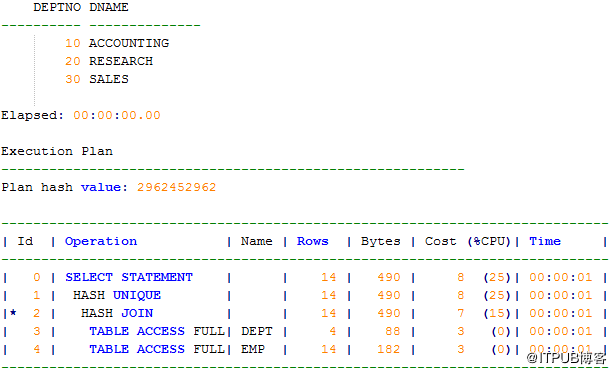
--使用EXISTS(高效)select d.deptno, d.dname from dept d
where exists (select 1 from emp e where e.deptno = d.deptno);
使用exists+使用exists代替in+使用exists代替distinct
使用exists代替in
exists只检查行的存在性,in检查实际的值,所以exists的性能比in好
验证
select * from emp
where deptno in(select deptno from dept where loc='NEW YORK');select * from emp e
where exists(select 1 from dept d where d.deptno=e.deptno and loc='NEW YORK');

使用exists代替distinct
exists只检查行的存在性,distinct用于禁止重复行的显示,而且distinct在禁止重复行的显示前需要排序检索的行,所以exists的性能比distinct好
验证
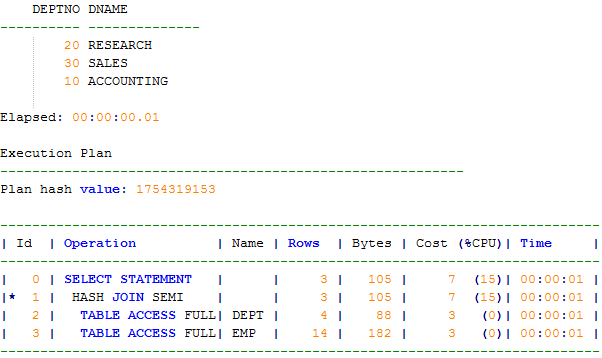
select distinct e.deptno,d.dname from emp e,dept d
where e.deptno=d.deptno;select d.deptno,d.dname from dept d
where exists(select 1 from emp e where e.deptno=d.deptno);

这篇关于oracle之优化一用group by或exists优化distinct的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




