本文主要是介绍pytorch学习——正则化技术——丢弃法(dropout),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概念介绍
在多层感知机(MLP)中,丢弃法(Dropout)是一种常用的正则化技术,旨在防止过拟合。(效果一般比前面的权重衰退好)
在丢弃法中,随机选择一部分神经元并将其输出清零,被清零的神经元在该轮训练中不会被激活。这样,其他神经元就需要学习代替这些神经元的功能,从而促进了神经元之间的独立性和鲁棒性。
1.1思想原理
丢弃法的基本思想是,在每一次训练中,随机选择一些神经元不参与训练,从而减少神经元之间的相互依赖关系,使得模型对于训练数据的过拟合程度降低。这样在测试时,所有神经元都参与,可以取得更好的泛化性能。
丢弃法可以被应用到多层感知机的任意层中,包括输入层和输出层。在实际应用中,通常会在每一层都添加丢弃法,以充分发挥其正则化作用。
丢弃法特性:在层之间加入噪声,而不是在数据输入时加入。

对Xi中的元素,以p概率变成0,1-p概率变大,最后期望值不变。
1.2应用场景
通常将丢弃法作用在隐藏全连接层的输出上。
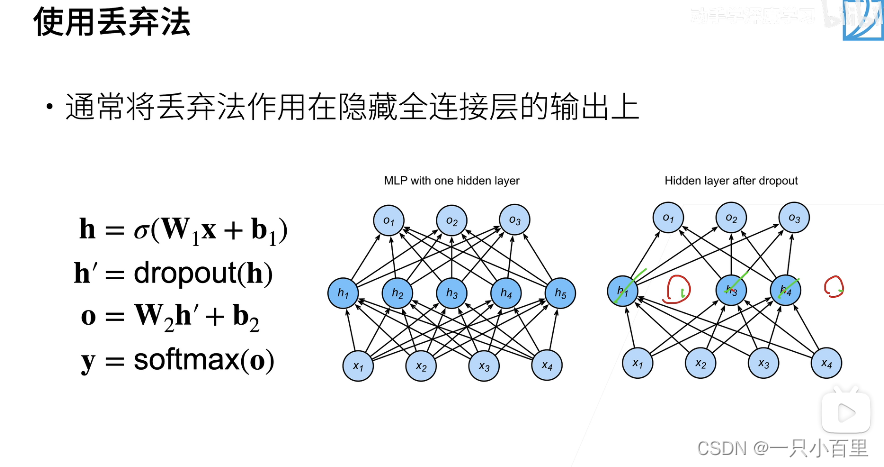
如图所示,丢弃法可将一些中间结点丢弃,对剩余节点进行一定的增强。

注:dropout是正则项,仅在训练中使用,不用于预测。

二、示例演示
2.1实现dropout_layer 函数
该函数以dropout的概率丢弃张量输入X中的元素, 如上所述重新缩放剩余部分:将剩余部分除以1.0-dropout。
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)2.2测试dropout_layer函数
X=torch.arange(16,dtype=torch.float32).reshape((2,8))
print(X)
#暂退概率是0,0.5,1
print(dropout_layer(X,0.))
print(dropout_layer(X,0.5))
print(dropout_layer(X,1.))
#结果
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 0., 4., 6., 0., 0., 0., 14.],[16., 0., 20., 22., 24., 0., 28., 0.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0.]])2.3定义模型
引入Fashion-MNIST数据集。 我们定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元。将暂退法应用于每个隐藏层的输出(在激活函数之后), 并且可以为每一层分别设置暂退概率: 常见的技巧是在靠近输入层的地方设置较低的暂退概率。 下面的模型将第一个和第二个隐藏层的暂退概率分别设置为0.2和0.5, 并且暂退法只在训练期间有效。
num_inputs,num_outputs,num_hiddens1,num_hiddens2=784,10,256,256
#定义两个隐藏层,每个隐藏层有256个单元
dropout1, dropout2 = 0.2, 0.5 # 为每个隐藏层设置一个 dropout 概率class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):# 应用第一个全连接层和 ReLU 激活函数H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 如果处于训练模式,对第一个隐藏层应用 dropout 操作if self.training == True:H1 = dropout_layer(H1, dropout1)# 应用第二个全连接层和 ReLU 激活函数H2 = self.relu(self.lin2(H1))# 如果处于训练模式,对第二个隐藏层应用 dropout 操作if self.training == True:H2 = dropout_layer(H2, dropout2)# 应用第三个全连接层,得到输出张量out = self.lin3(H2)return out# 创建一个神经网络模型实例
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)2.4训练和测试
# 设置训练的轮数、学习率和批次大小
num_epochs, lr, batch_size = 10, 0.5, 256# 定义损失函数为交叉熵损失,并设置reduction='none'以便获得单个样本的损失值
loss = nn.CrossEntropyLoss(reduction='none')# 加载Fashion-MNIST数据集,并设置批次大小
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)# 定义优化器为随机梯度下降(SGD),并设置学习率
trainer = torch.optim.SGD(net.parameters(), lr=lr)# 使用d2l.train_ch3函数进行模型训练,其中包括训练数据迭代器、测试数据迭代器、损失函数、训练轮数和优化器等参数
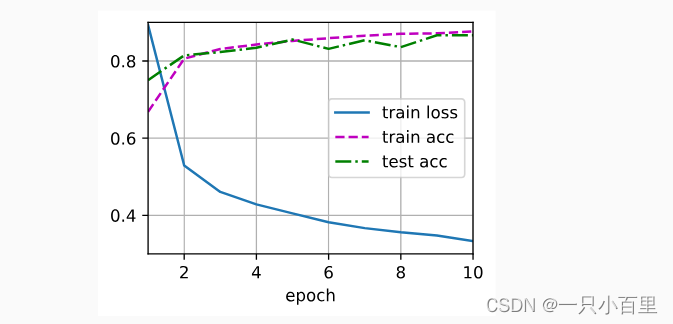
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)2.5结果
三 、简洁实现
from torch import nn
import torch
from d2l import torch as d2l
dropout1, dropout2 = 0.2, 0.5 # 为每个隐藏层设置一个 dropout 概率
num_epochs, lr, batch_size = 10, 0.5, 256
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)这篇关于pytorch学习——正则化技术——丢弃法(dropout)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





