本文主要是介绍丢弃法Dropout(Pytorch),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://courses.d2l.ai/zh-v2/
文章目录
- 丢弃法
- 动机
- 无偏差的加入噪音
- 使用丢弃法
- 推理中的丢弃法
- 总结
- 从零开始实现
- 定义模型参数
- 定义模型
- 训练和测试
- 简洁实现
- 模型测试
- 总结
- QA
丢弃法
动机
- 一个好的模型需要对输入数据的扰动鲁棒
- 使用有噪音的数据等价于 Tikhonov 正则
- 丢弃法:在层之间加入噪音
无偏差的加入噪音
- 对 x 加入噪音得到 x’,我们希望
E [ x ′ ] = x E[x']=x E[x′]=x - 丢弃法对每个元素进行如下扰动
x i ′ = { 0 w i t h p r o b a b l i t y p w i 1 − p o t h e r w i s e x_i'= \begin{cases} 0&with\;probablity\;p\\ {w_i \over 1-p}&otherwise \end{cases} xi′={01−pwiwithprobablitypotherwise
E [ x i ′ ] = p ⋅ 0 + ( 1 − p ) x i 1 − p = x i E[x_i']=p·0+(1-p){x_i \over 1-p}=x_i E[xi′]=p⋅0+(1−p)1−pxi=xi
使用丢弃法
- 通常将丢弃法作用在隐藏全连接层的输出上
h = σ ( W 1 x + b 1 ) h ′ = d r o p o u t ( h ) o = W 2 h ′ + b 2 y = s o f t m a x ( o ) h=\sigma (W_1x+b_1)\\ h'=dropout(h)\\ o=W_2h'+b_2\\ y=softmax(o) h=σ(W1x+b1)h′=dropout(h)o=W2h′+b2y=softmax(o)
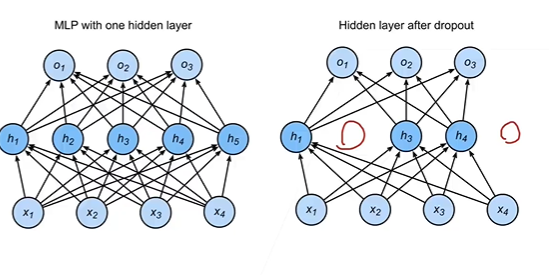
加入一个概率函数,杀死一些连接
推理中的丢弃法
- 正则项只在训练中使用:他们影响模型参数的更新
- 在推理过程中,丢弃法直接返回输入
h = d r o p o u t ( h ) h=dropout(h) h=dropout(h)- 这样也能保证确定性的输出
总结
- 丢弃法将一些输出项随机置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数
丢弃率P一般取 0.5、0.9、0.1
从零开始实现
要实现单层的暂退法函数, 我们从均匀分布中抽取样本,样本数与这层神经网络的维度一致。 然后我们保留那些对应样本大于的节点,把剩下的丢弃。
在下面的代码中,我们实现dropout_layer函数, 该函数以dropout的概率丢弃张量输入X中的元素, 如上所述重新缩放剩余部分:将剩余部分除以1.0-dropout。
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float() # 前面是bool,float转为浮点型的0.或1.return mask * X / (1.0 - dropout)
- 做乘法远比选一个数据来得快
- rand 产生0-1之间的均匀分布
- randn 产生均值为0,方差为1的高斯分布
我们可以通过下面几个例子来测试dropout_layer函数。 我们将输入X通过暂退法操作,暂退概率分别为0、0.5和1。
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 0., 0., 0., 8., 10., 0., 14.],
[16., 18., 0., 22., 0., 0., 28., 30.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
定义模型参数
定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
定义模型
我们可以将暂退法应用于每个隐藏层的输出(在激活函数之后), 并且可以为每一层分别设置暂退概率: 常见的技巧是在靠近输入层的地方设置较低的暂退概率。 下面的模型将第一个和第二个隐藏层的暂退概率分别设置为0.2和0.5, 并且暂退法只在训练期间有效。
dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
实例化 Net 类之后,自动调用 forward
训练和测试
这类似于前面描述的多层感知机训练和测试。
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
简洁实现
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层, 将暂退概率作为唯一的参数传递给它的构造函数。 在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。 在测试时,Dropout层仅传递数据。
net = nn.Sequential(nn.Flatten(), # 将输入拉平,拉成二维nn.Linear(784, 256), nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);
模型测试
接下来,我们对模型进行训练和测试。
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
总结
-
暂退法在前向传播过程中,计算每一内部层的同时丢弃一些神经元。
-
暂退法可以避免过拟合,它通常与控制权重向量的维数和大小结合使用的。
-
暂退法将活性值替换为具有期望值的随机变量。
-
暂退法仅在训练期间使用。
QA
-
dropout随机置0对求梯度和方向传播的影响是什么?
dropout置0,梯度也会变成0,对应的权重也不会更新
可以理解为每次从里面随机拿出来一个小网络进行更新 -
在使用BN的时候,有必要使用dropout嘛?
BN是给卷积层用的,dropout是给全连接层用的 -
dropout 函数返回值的表达式 return mask * X / (1.0 - dropout) 没被丢弃的输入部分的值会因为表达式分母(1-P)的存在而改变,而训练数据的标签还是原来的值。
要么把输出变成0,不然要除以(1-P)。保证期望(均值)不改变,但标签不改变。dropout唯一改变的是隐藏层的输出。
可以改标签,也是一种正则化。
这篇关于丢弃法Dropout(Pytorch)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







