本文主要是介绍2--丢弃法(Dropout),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2.1 丢弃法
在训练过程中,在计算后续层之前向网络的每一层注入噪声。 因为当训练一个有多层的深层网络时,注入噪声只会在输入-输出映射上增强平滑性,该思想称为丢弃法。
丢弃法在前向传播过程中,计算每一内部层的同时注入噪声,这已经成为训练神经网络的常用技术。 这种方法之所以被称为丢弃法,因为从表面上看是在训练过程中丢弃(drop out)一些神经元。 在整个训练过程的每一次迭代中,标准丢弃法包括在计算下一层之前将当前层中的一些节点置零。
在标准丢弃法正则化中,通过按保留(未丢弃)的节点的分数进行规范化来消除每一层的偏差。 换言之,每个中间活性值h以暂退概率p由随机变量h′替换,如下所示(并且其期望值保持不变,即E[h′]=h):

注意:通常,在测试时不用暂退法。 给定一个训练好的模型和一个新的样本,我们不会丢弃任何节点,因此不需要标准化。
2.2 代码实现
!pip install git+https://github.com/d2l-ai/d2l-zh@release # installing d2l
!pip install matplotlib==3.0.0import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X,dropout):assert 0 <= dropout <= 1if dropout == 1:return torch.zeros_like(X)if dropout == 0:return Xmask = (torch.rand(X.shape)>dropout).float()#当随机生成的数字大于dropout是 返回1 反之返回0return mask * X / (1.0- dropout)dropout1, dropout2 = 0.2, 0.5
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)from re import L
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(),lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
运行结果:
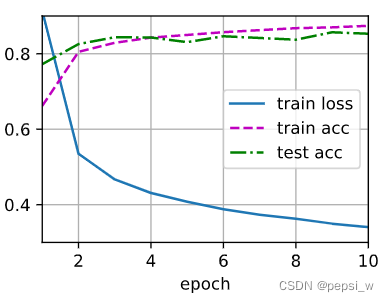
将dropout设置为0 即使用正常的完整的网络进行训练,此时有过拟合的可能,可以看出还是使用dropout的效果好一点:

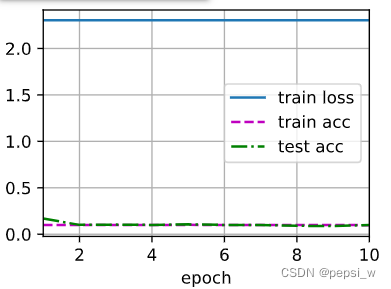
当两层的dropout概率为1时,即全丢弃的时候。
这篇关于2--丢弃法(Dropout)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








