本文主要是介绍通过Tensorflow-DirectML 快速启用 AMD及NVIDIA GPU 加速,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
第一章 Tensorflow 机器学习入门之环境搭建及图片训练与识别
文章目录
目录
前言
一、本文目的是什么?
二、使用步骤
1.安装微软 Tensorflow-DirecTML支持
2.Python 环境及Tensorflow-DirecTML安装注意事项
3.目标识别输入数据处理
4.进行数据处理,学习
5.生成PB文件,用于后续的目标识别
6.目标识别
总结
前言
随着人工智能的不断发展,机器学习也越来越重要,很多人都开启了学习路程,本文就介绍了机器学习的基础内容。
不同的GPU与Tensorflow进行整合调用的时候,会有很多的技术细节,最近使用微软的DirectML感觉还可以,非常方便,在windows及WSL Linux下都能很好的使用GPU的运算能力。把这个操作过程记录下,方便自己,也方便初学的同学。
我的系统环境:
Windows11
GPU:AMD Radeon RX6700TX
python:Python 3.6.13 :: Anaconda, Inc.(注意,不应超过3.6版本)
WSL:Ubuntu 20.04.
conda 4.11.0
一、本文目的是什么?
通过Tensorflow搭建训练环境及利用训练结果进行目标检测。本文包括操作流程说明及数据文件和代码。我在windows11及ubuntu20.04上都走通了整个流程,以下介绍以ubuntu操作为主,windows根据情况转换即可。
二、使用步骤
1.安装微软 Tensorflow-DirecTML支持
微软与Nvidia、AMD 和英特尔等供应商合作,以确保在 Windows 10及以上 和 WSL 上提供流畅的体验,以便在支持 DirectX 12 的 GPU 上加速训练。关于GPU的驱动支持,请看微软的说明:TensorFlow with DirectML on WSL | Microsoft Docs
2.Python 环境及Tensorflow-DirecTML安装注意事项
我使用conda 作为python环境管理,非常方便,简单易用,安装成功后,应当创建专用于DirecTML的环境,我是这样的:
conda activate directm
安装DirecTML:pip install tensorflow-directml
注意:如果原先有安装过 tensorflow,一定要卸载,如果又有安装过tensorflow-directml,而且未起作用,也应当一并卸载。
pip uninstall tensorflow
pip uninstall tensorflow-directml
如果不是新创建的conda directml,尽量卸载完所有tensorflow有关的模块,否则。。。。
pip list | grep tensorflow
pip uninstall tensorflow***
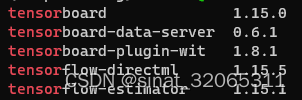
安装成功后,查看下tensorflow相关包,应当是这个样子的,注意:不能再去安装 tensorflow:
pip list | grep tensor
tensorboard 1.15.0
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.1
tensorflow-directml 1.15.5
tensorflow-estimator 1.15.1
3.目标识别输入数据处理
将已经标定的图片及xml文件转换成 .record文件(xml文件可以使用labelImg进行标识产生,不在本文讨论范围。):
首先是 xml转换为csv,代码中涉及路径的,需要根据实际情况修改,python xml_to_csv.py中有一处需要修改:
cd /home/akun-u/dev/deeplearning/raccoon_datasetpython xml_to_csv.py执行上述命令后,会在当前目录生成两个csv文件
Successfully converted files:201 xml to csv(./train_labels.csv).
Successfully converted files:16 xml to csv(./test_labels.csv).
xml_to_csv.py文件内容如下:
import glob
import os
import xml.etree.ElementTree as ETimport pandas as pddef xml_to_csv(path):xml_list = []for xml_file in glob.glob(path + '/*.xml'):tree = ET.parse(xml_file)root = tree.getroot()for member in root.findall('object'):value = (root.find('filename').text,int(root.find('size')[0].text),int(root.find('size')[1].text),member[0].text,int(member[4][0].text),int(member[4][1].text),int(member[4][2].text),int(member[4][3].text))xml_list.append(value)column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']xml_df = pd.DataFrame(xml_list, columns=column_name)return xml_dfdef main():for direcory in ['train','test']:image_path = os.path.join('/home/akun-u/dev/deeplearning/raccoon_dataset/annotations', direcory)print("xmlfile:", image_path)xml_df = xml_to_csv(image_path)csv_path = './{0}_labels.csv'.format(direcory)xml_df.to_csv(csv_path, index=None)print(f'Successfully converted files:{len(xml_df)} xml to csv({csv_path}).')main()接着将csv文件转换为 .record:注意文件路径要填写正确。
cd /home/akun-u/dev/deeplearning/raccoon_datasetpython generate_tfrecord.py --csv_input=test_labels.csv --output_path=data/dataset/test.record --image_dir=imagespython generate_tfrecord.py --csv_input=train_labels.csv --output_path=data/dataset/train.record --image_dir=imagesgenerate_tfrecord.py文件内容如下:
"""
Usage:# From tensorflow/models/# Create train data:python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=train.record# Create test data:python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record#yhk add
python generate_tfrecord.py \--csv_input=data/test_labels.csv \--output_path=data/dataset/test.record \--image_dir=images/
python generate_tfrecord.py \--csv_input=data/train_labels.csv \--output_path=data/dataset/train.record \--image_dir=images/"""
from __future__ import absolute_import, division, print_functionimport io
import os
from collections import OrderedDict, namedtupleimport pandas as pd
import tensorflow as tf2tf= tf2.compat.v1 #yhk addfrom object_detection.utils import dataset_util
from PIL import Imageflags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
flags.DEFINE_string('image_dir', '', 'Path to images')
FLAGS = flags.FLAGS# TO-DO replace this with label map
def class_text_to_int(row_label):if row_label == 'raccoon':return 1else:return 2def split(df, group):data = namedtuple('data', ['filename', 'object'])gb = df.groupby(group)return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]def create_tf_example(group, path):with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:encoded_jpg = fid.read()encoded_jpg_io = io.BytesIO(encoded_jpg)image = Image.open(encoded_jpg_io)width, height = image.sizefilename = group.filename.encode('utf8')image_format = b'jpg'xmins = []xmaxs = []ymins = []ymaxs = []classes_text = []classes = []for index, row in group.object.iterrows():xmins.append(row['xmin'] / width)xmaxs.append(row['xmax'] / width)ymins.append(row['ymin'] / height)ymaxs.append(row['ymax'] / height)classes_text.append(row['class'].encode('utf8'))classes.append(class_text_to_int(row['class']))tf_example = tf.train.Example(features=tf.train.Features(feature={'image/height': dataset_util.int64_feature(height),'image/width': dataset_util.int64_feature(width),'image/filename': dataset_util.bytes_feature(filename),'image/source_id': dataset_util.bytes_feature(filename),'image/encoded': dataset_util.bytes_feature(encoded_jpg),'image/format': dataset_util.bytes_feature(image_format),'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),'image/object/class/text': dataset_util.bytes_list_feature(classes_text),'image/object/class/label': dataset_util.int64_list_feature(classes),}))return tf_exampledef main(_):writer = tf.python_io.TFRecordWriter(FLAGS.output_path)path = os.path.join(FLAGS.image_dir)examples = pd.read_csv(FLAGS.csv_input)grouped = split(examples, 'filename')for group in grouped:tf_example = create_tf_example(group, path)writer.write(tf_example.SerializeToString())writer.close()output_path = os.path.join(os.getcwd(), FLAGS.output_path)print('Successfully created the TFRecords: {}'.format(output_path))if __name__ == '__main__':tf.app.run()
4.进行数据处理,学习
在接着执行以下语句之前,请:
1.修改 /deeplearning/pipeline.config 文件中的路径(有5处)
2.根据实际情况调整 /deeplearning/conf/clickv2_label_map.pbtxt
接下来执行:python object_detection/model_main.py
注意:执行python object_detection/model_main.py时,尽量一行写完整个语句,我原先使用了 \ 连接多行语句,一直调试失败,浪费了不少时间。
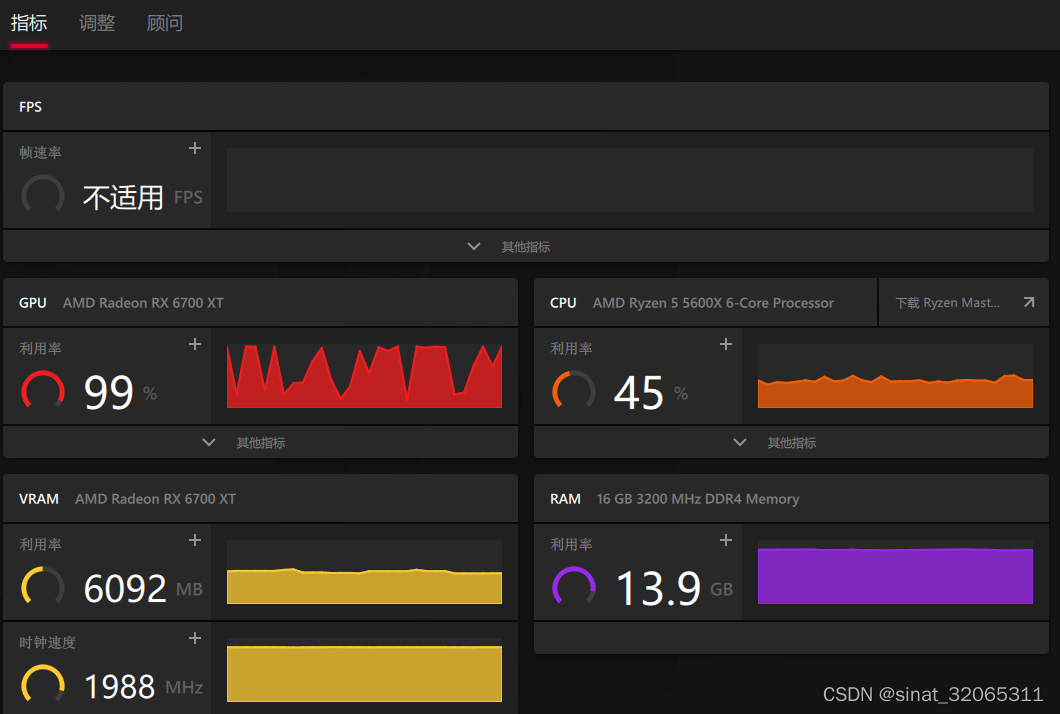
语句执行过程中,有出现 “DirectML: creating device on adapter 0 (AMD Radeon RX 6700 XT”,字样
RX 6700 XT是我的显卡型号,请注意看,该字样能够确定是否有使用GPU,这个执行过程会花费很长时间,我的显卡在--num_train_steps=50000 --num_eval_steps=2000的情况下,执行了约3小时。
cd /home/akun-u/dev/deeplearning/models/researchpython object_detection/model_main.py --pipeline_config_path=/home/akun-u/dev/deeplearning/conf/ssd_mobilenet_v2_coco_2018_03_29/pipeline.config --model_dir=/home/akun-u/dev/deeplearning/models --num_train_steps=50000 --num_eval_steps=2000 --alsologtostderr该命令会在 models目录下生成多个model.ckpt开头的文件。
执行情况如图:

5.生成PB文件,用于后续的目标识别
cd /home/akun-u/dev/deeplearning/models/research/object_detectionpython export_inference_graph.py --input_type=image_tensor --pipeline_config_path=/home/akun-u/dev/deeplearning/conf/ssd_mobilenet_v2_coco_2018_03_29/pipeline.config --trained_checkpoint_prefix=/home/akun-u/dev/deeplearning/models/model.ckpt-50000 --output_directory=/home/akun-u/dev/deeplearning/train_pb6.目标识别
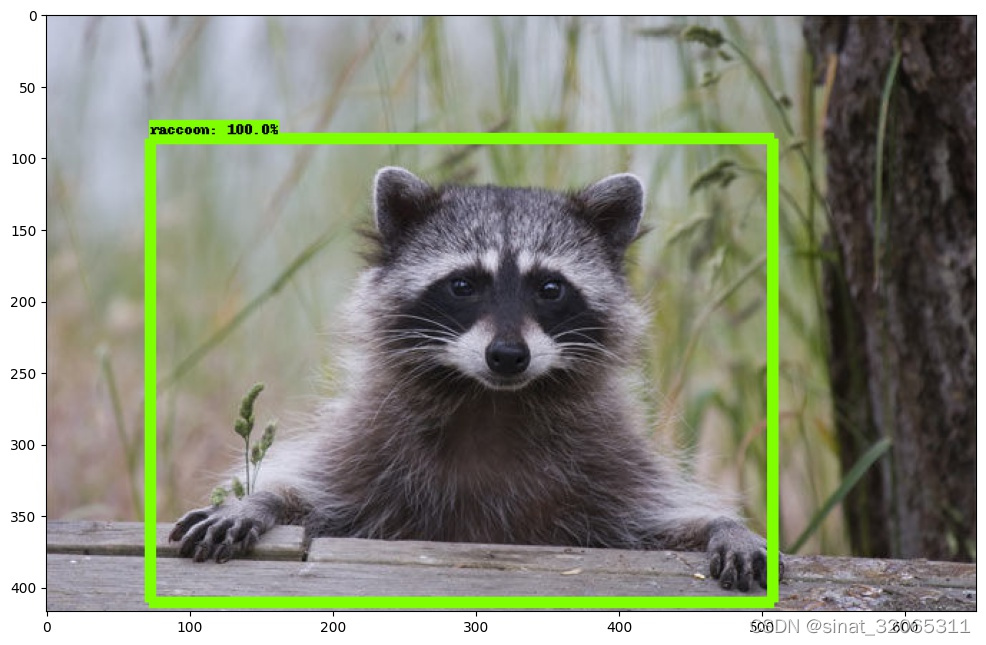
注意:修改识别后文件保存路径(img_recongnize.py中:1处)
cd /home/akun-u/dev/deeplearningpython img_recongnize.py运行后会在指定目录下生成多个jpg文件,打开可看到可识别目标被框选,如下图:
总结
以上就是今天要讲的内容,本文仅仅简单介绍了tensorflow-directmp的基本使用,自己过了好多坑,终于爬出,留个文本。。。
我的代码:https://download.csdn.net/download/sinat_32065311/85275745
代码来源:
GitHub - microsoft/tensorflow-directml: Fork of TensorFlow accelerated by DirectML
https://github.com/tensorflow/models
https://github.com/datitran/raccoon_dataset
Tensorflow Object detection 教程
这篇关于通过Tensorflow-DirectML 快速启用 AMD及NVIDIA GPU 加速的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





