本文主要是介绍MLSQL:一分钟让 Kylin 装备 ETL 能力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在上周举办的 Apache Kylin + MLSQL Meetup 中,我们邀请了来自 MLSQL 社区的技术大佬 祝威廉 来进行分享。大家都知道 Kylin 一向以强大的分析能力和丰富的周边生态而备受欢迎,但是 Kylin 自身还欠缺一些 ETL 能力。在本次分享中,祝威廉演示了如何在 Kylin 中快速完成数据处理,用户不用离开 Kylin 即可完成大规模数据分析整个 Pipeline,同时也分享了未来 Kylin 和 MLSQL 之间联动的更多可能性。
// 文末有 PPT 和完整版视频回顾哦
以下是祝威廉在 Kylin Meetup 的演讲实录

本次分享主要分为三部分,首先会宏观地去看一下 Kylin 和 MLSQL 这两者为什么是互补的,其次会进行一个 Demo 的演示,如何在 Kylin 里面通过简单几行代码的修改,就能够支持 MLSQL 的语言,从而完成一些 ETL 的工作。因为 Demo 目前只演示了其中一个场景,我会在第三部分来分享 Kylin 和 MLSQL 之间未来更多的可能性,两者其实是有许多可以联动的地方,大家也可以期待两者联动实现更好的效果。
Kylin 和 MLSQL 为什么是互补的
首先来介绍一下为什么说 Kylin 和 MLSQL 是互补的,如上图所示,目前在整个数据分析领域,主要有三大部分:

-
第一部分是 BI(Business Intelligence);
-
第二部分是数据处理,其中包含了目前正热的流处理,以及传统的批处理等;
-
第三部分是 AI(Artificial Intelligence)。
Kylin 其实是非常好地覆盖了 BI 这一部分,并且具有非常完美的生态系统,Kylin 对大部分 BI 工具都是支持的,具备一部分的处理功能比如说多维聚合分析 。用户使用 Kylin 去做数据分析,其实就是利用它的数据处理功能。但如果涉及到数据处理中 ETL 相关的功能,Kylin 目前是不太适合去做的,比如一部分流式的数据处理,不过这也正是 MLSQL 可以覆盖的。MLSQL 在 BI 这一部分并不擅长,但是在数据处理和 AI 这两部分是比较强的。如果 Kylin 和 MLSQL 两者进行整合,那么基本就可以完美覆盖大数据分析最主要的三个领域。
Kylin 简介
首先来简单介绍一下 Kylin。Kylin 是一个 OLAP 的系统,支持高并发、亚秒级查询,这两点优势其实是许多工具难以超越的。同时,Kylin 生态完备,支持各种 BI 工具,比如像 Tableau PowerBI 等。
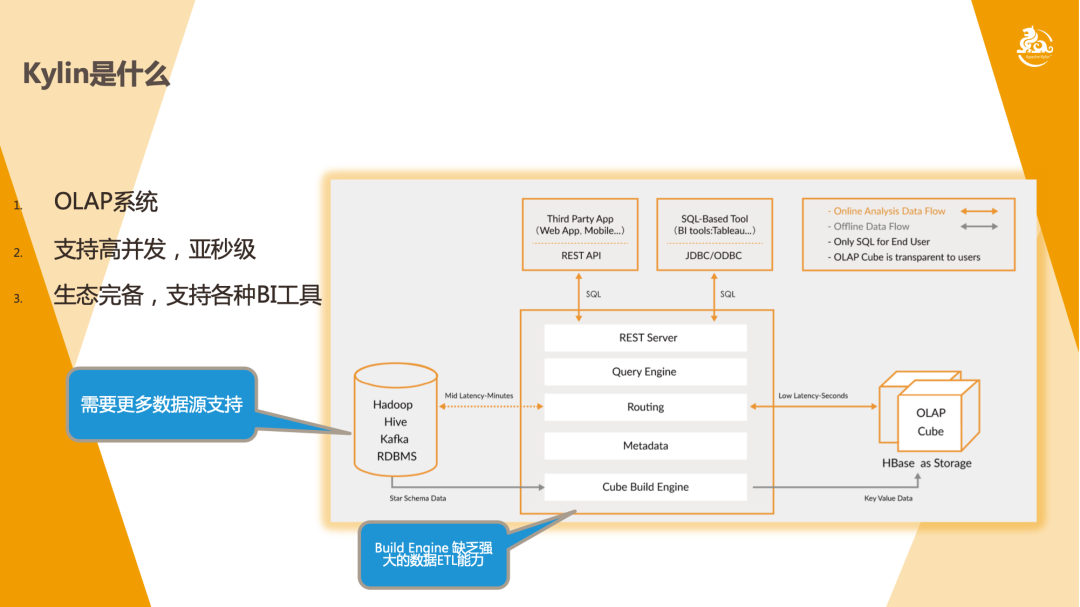
如上面 Kylin 官网架构图所示,Kylin 有一个 Cube Build Engine,也就是用来构建 Cube 的过程。这个过程意味着它必须有数据来源,这个过程可能存在两个问题:
-
一是 Build Engine 其实更加侧重的是在数据建模这一块,数据来源需要进行加工才能适合去做建模,所以它其实是缺乏较强的 ETL 能力;
-
二是 Kylin 的很多数据源是要单独去支持的,MLSQL 本身已经支持非常多的数据源了,如果把两者打通,那就意味着这两部分 Kylin 无需自己支持,直接借助一些工具就能够实现,比如前面提到的 CSV 数据源。
目前有两种方式:
-
方式一:大家可以自建一个 ETL 的基础设施;
-
方式二:如果 Kylin 本身可以支持,用户就不用离开 Kylin 就可以完成这件事情了,对用户而言,就能带来更好的使用体验。
MLSQL 简介
大部分 Kylin 用户可能暂时对 MLSQL 不太了解,我先来进行一个简单介绍。
主要从以下两个方面进行介绍:
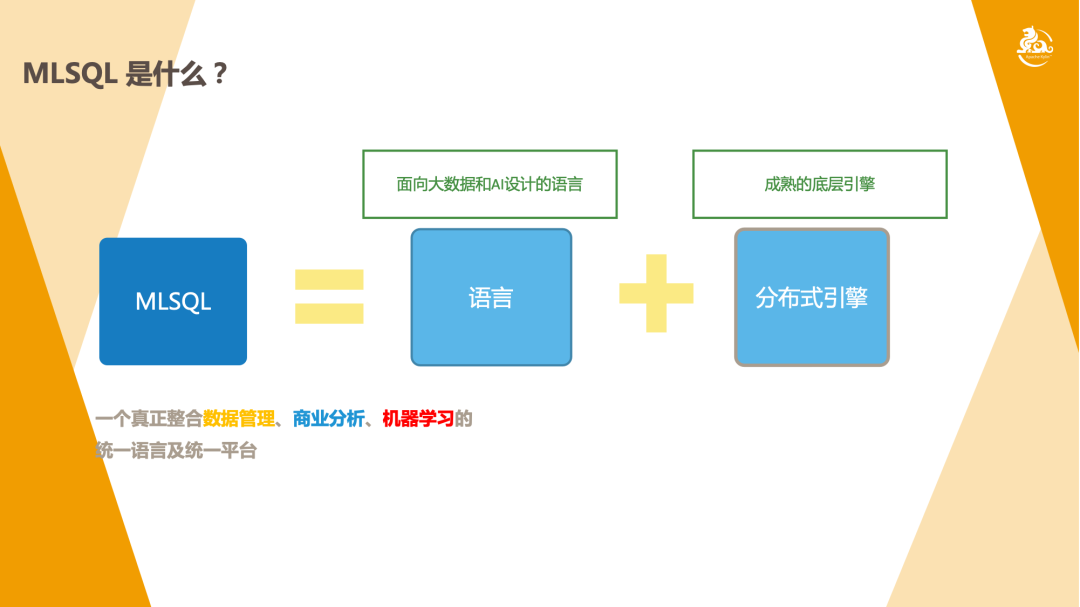
第一方面, MLSQL 是一个面向大数据和 AI 设计的语言。正常情况下,使用大数据,用户可以用 Scala 或者 JAVA 语言;使用 AI 的用户可能会用 Python 语言;其实数据处理大家真正用的最多的应该是 SQL。那为什么还需要像 MLSQL 这样的语言呢?简单来说,如果用户去用 Scala 写代码,其实是需要深入掌握和应用这门语言的,另外包括 Python 也是存在一定的使用门槛的。SQL 很简单,但是如果想实现 AI 或是更强的 ETL 功能,SQL 就会存在能力欠缺的问题。在这样的情况下,MLSQL 其实就变成很有必要的一种语言了。
第二方面,前面也提到 MLSQL 是一种语言,任何一种语言都一定要有一个实现,就像我们之前提到的 JAVA语言,就有 JVM 虚拟机的实现。其实 MLSQL 底层也有一个实现这门语言的引擎,本质上底层是基于 Spark 做的引擎。MLSQL 的目标其实是要做一个真正整合数据管理、商业分析和机器学习的统一的语言和平台。
接下来介绍 MLSQL 的一些语法,让大家简单熟悉一下。
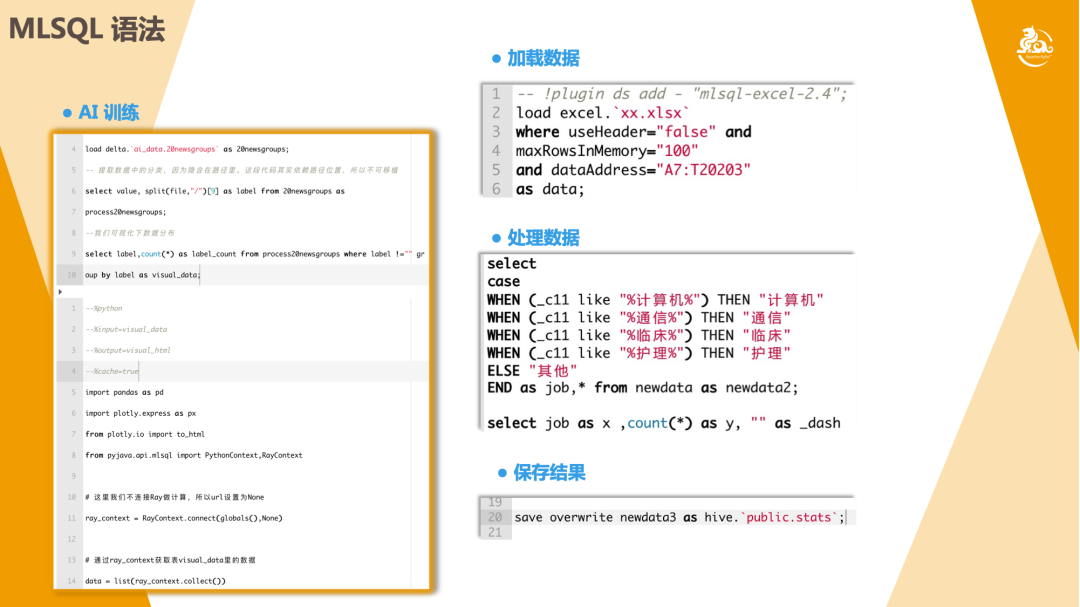
首先,在加载数据的部分,在 SQL 里必须要有 Catalog 才可以实现,默认数据源可能是 Hive。如果用户想加载其他数据,用 SQL 会比较麻烦。在这一部分,MLSQL 进行了一些拓展,比如使用 MLSQL 的 Load 语句,用户就可以加载任意数据源。
其次是可以用 SQL 去做标准的数据处理,同时处理完的结果可以进行保存。如上图所示,左侧是 AI 训练,MLSQL 其实是把 Python 和 SQL 进行了融合,用户可以用 Python 去直接使用 SQL 的表, Python 处理后的结果也可以作为表继续在 SQL 里使用。这里只是一些简单介绍,更多内容大家可以关注 MLSQL 的官方文档。
http://docs.mlsql.tech/mlsql-console/
如何不离开 Kylin 就能完成 ETL
以上简单介绍了 Kylin 和 MLSQL,要想整合两者,首先必须满足以下几个标准:
首先,整合成本必须要低。最差的情况下,是可能需要去修改一丢丢代码的,实际上,我和Kylin社区的Committer张智超也去进行了一些实践。在极致的情况下,只需要修改两行代码就可以完成整合。当然,这个过程中可能会新增一些文件,但是修改的部分可能只有几行代码。
其次,MLSQL 希望优先补全 Kylin 的 ETL 能力,可以实现在 Kylin 里面就可以直接进行 ETL。
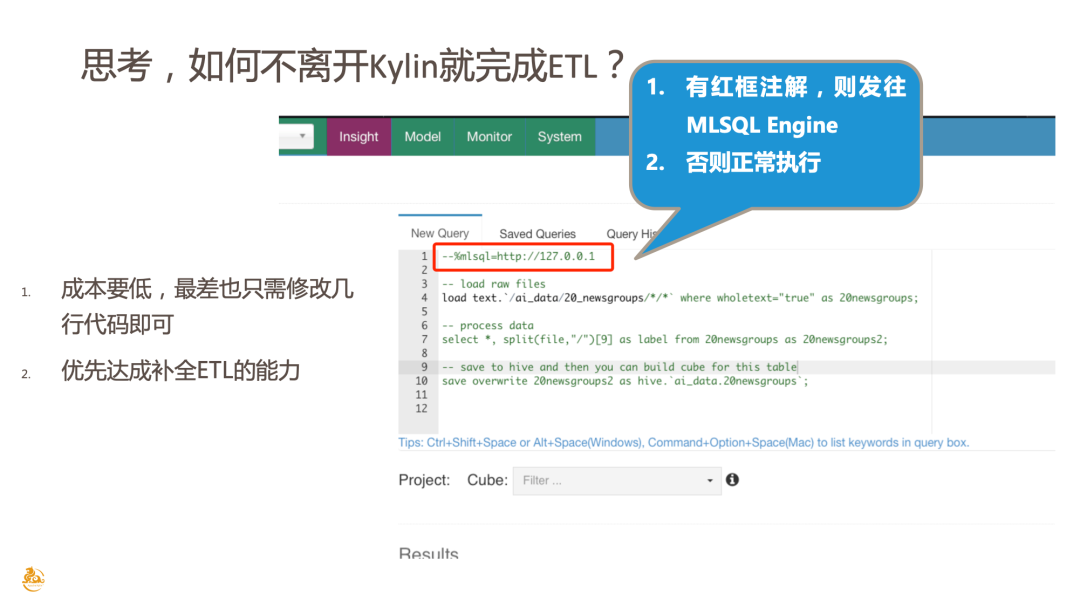
考虑到以上两点,大家可以看到上图里做了一个简单注解是 --%mlsql,后面可以跟一个 MLSQL 引擎地址,有了这个注解,即可把整个框中的脚本内容发到 MLSQL 引擎里面去执行。如果没有这个注解,就会按照 Kylin 的执行逻辑去执行。有了初步思路,我们去做了一个演示 Demo,大家可以一起来看看演示效果。
Demo 演示
Demo 中的这个界面大家应该非常熟悉,这是 Kylin 的运行页面。今天分享的 Demo 就是演示用户如何在 Kylin 的产品里,将一个 CSV 文件导入到 Hive 以供 Kylin 进行建模,整个过程仅修改几行代码就能把 ETL 的处理完成。
除了上面展示的 Demo 以外,面向未来,MLSQL 在 Kylin 里可以和 Kylin API 进行对接,或者使用任务调度器 Airflow 等,就可以把写好的脚本保存并运转起来,其实就相当于已经完成了一个 ETL 的工具集了。用户无需自行搭建 ETL 平台,就能在 Kylin 页面完成整个流程。实现以后,用户可以直接对接 Kylin 数据,既可以使用 Kylin 进行加速,比如实现亚秒级响应速度,同时也可以写一个较为复杂的数据处理的流程,去查看数据的情况等。
Kylin 与 MLSQL 更多联动方式
以上分享的这个 Demo 解决的核心问题是 ETL 能力,其实理论上,用户也是可以直接在刚刚的界面上做一些 AI 相关的操作。当用户拿到数据或通过 Kylin 得到一些分析结果,这个时候想去做一些算法相关的工作,就可以用到上面这种最简单的联动方式。其实 Kylin 和 MLSQL 联动的方式存在多种,这里简单介绍以下两种:
-
第一种是前置联动,如果这是一个 Pipeline 的话,那么 MLSQL 应该是在 Kylin 的前半部分, Kylin 是面向用户的或者说面向报表的,MLSQL 就可以帮助 Kylin 完成 ETL 的部分。
-
第二种是后置联动, MLSQL 本身是支持多数据源的,这也就意味着 MLSQL 可以连接 Kylin 的结果,再和 HDFS 或 HIVE 的结果再进行 Join 以及其他计算。
今天我们所讲的主要是前置联动,也分为两种:浅联动和深联动。
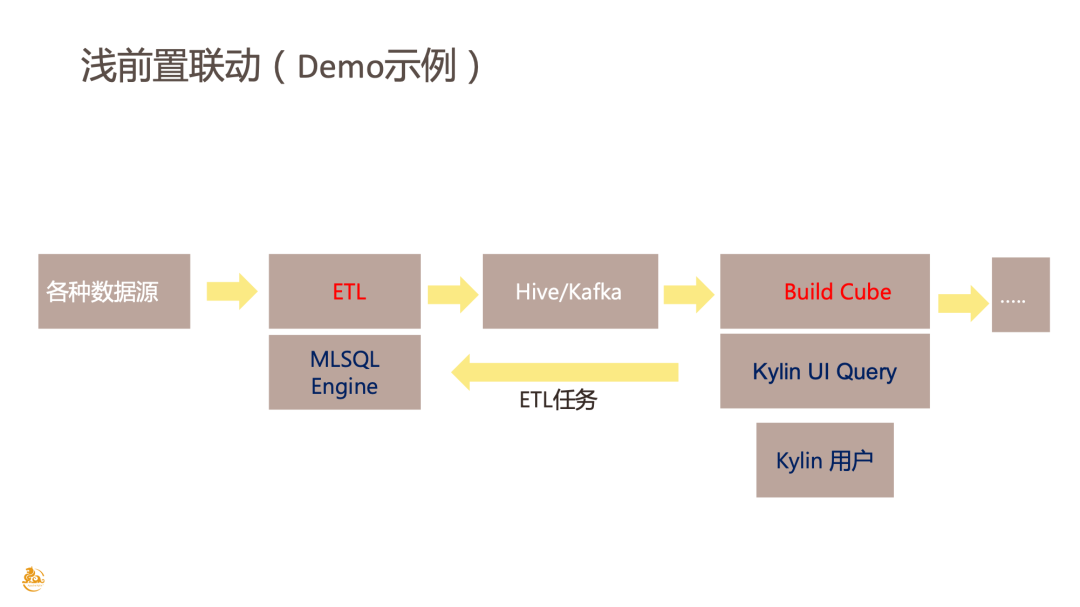
本次 Demo 演示的就是浅前置联动,也就是正常情况下进行的 Pipeline,从各种数据源,经过 ETL 处理到 HIVE 或者 Kafka,之后由 Kylin 进行 Cube 的构建,再面向用户进行查询或者面向报表以及其他复杂的操作。这整个 ETL 的过程其实是可以通过 MLSQL Engine 去完成的,当然用户也可以直接使用一个比较好的控制台去 MLSQL Engine 里去执行任务,或者使用其他的引擎等。在本次 Demo 示例里面, Kylin 用户可以在 Kylin UI Query 里面直接下发 ETL 任务到引擎层,去帮助 Cube 事先准备好数据,这就是浅联动,因为它的影响面比较小。
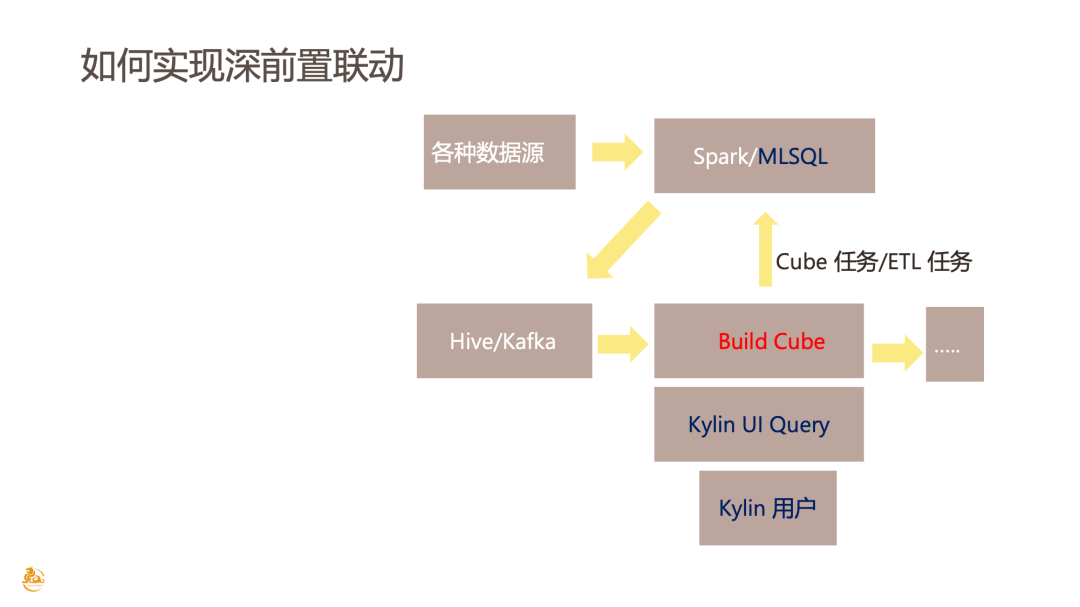
第二种是深前置联动。相较浅联动,深联动可以把 Pipeline 稍微调整一下,不仅可以下发 ETL 的任务到 MLSQL,甚至可以把 Cube 的构建任务也下发到 MLSQL。目前 Kylin 4.0 其实已经支持 Spark 引擎,所以把 Cube 任务给下沉到 MLSQL 实现起来也比较简单。
此处小剧透,有赞的郑生俊老师会分享在 Kylin 3.0 把 Cube 的任务内置到 Spark 引擎,并且用 K8s 去跑,已经被验证是可行的。这其实是一个比较深的联动,相当于把 Kylin 的 Cube 任务都下沉到 MLSQL 引擎层了。这也是更适合引擎层面去实现的,未来 MLSQL 既可以作为一个常驻的任务,也可以在 Kylin 去启动执行一个任务后,再把资源放掉。
以上就是对深联动和浅联动的简单介绍。关于后置联动,未来会有相关技术博客和演示分享。从 MLSQL 社区的角度来讲,首先 MLSQL 社区接下来会尝试引入 Cube 的构建功能,也就是前面提及的与 Kylin 的深层次联动;其次,未来 MLSQL 会提供一个更友好的方式以供 Kylin 衔接;当然,我们也有可能给 Kylin 社区去贡献类似嵌入 ETL 能力的插件体系,不仅可以使用 MLSQL,Spark,还可以使用更多其他 ETL 工具,从而实现让用户可以在 Kylin 里就完成整个过程。
嘉宾简介
祝海林(祝威廉),新一代开源数据与 AI 处理语言 MLSQL 作者,现为 Kyligence 技术合伙人 & 资深架构师,拥有 10+ 年研发经验,近 6 年专注于数据管理、商业分析、机器学习的统一平台的设计和开发。长期活跃在 Spark、Ray、Kylin 等多个开源社区,有多年的开源社区运营经验。
视频回顾
关注公众号回复「MLSQL」 获得本次会议的全部 PPT.

这篇关于MLSQL:一分钟让 Kylin 装备 ETL 能力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







