本文主要是介绍PRIM(Patient Rule Induction Method)规则发现算法在风控中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在风控策略迭代过程中,我们通常需要从高维变量中搜索组合得到规则集(RuleSet),但是单纯依靠画格子、CART决策树等常规手段具有很高的挑战。此时,我们需要一种更为智能、更自动化的方法,从大量变量(高维空间)里找到最优规则集,这就是规则发现。
本文主要介绍一种规则发现算法,即病人规则归纳方法(Patient Rule Induction Method -PRIM),并紧密结合信贷风控业务知识,详细介绍理论和实践应用。
Part 1. 规则发现的概念
很多机器学习二分类问题抽象为 f(y|x) ,根据输入特征空间 X,预测个体发生目标事件的概率 P(y=1|X) 。然而,很多时候我们的目的不在于训练一个全局模型,而更为关注 y 值浓度很高(或很低)的某个局部空间。
现有 N个样本 {xi,y}^N ,我们希望从 M 维变量空间寻找一个子空间,使得这个子空间的目标变量浓度尽可能高。这个问题被称为子群识别(Subgroup Identification)。
为更容易理解子群识别的概念,我们以削苹果 为例。如图1所示,我们在苹果这个三维空间里横竖切几刀,找出了目标区域(芯),予以剔除(Peeling)。
而随着规则可解释性越来越受到大家关注,我们迫切需要找寻一些搜索过程透明、易于理解的智能算法来帮助我们进行规则发现。

为便于后文理解,我们定义如下概念:
#支持度(support):子群样本量相对于总体样本量的比例,反映规则命中率(hit rate)。
#正样本浓度:子群里正样本量相对于子群样本量的比例,反映坏人浓度(bad rate)。
#提升度(lift):子群正样本浓度相对于总体正样本浓度的提升,反映规则的提升杠杆。通常越大越好。
Part 2. 单维变量空间规则发现:巧用分位数
在贷前授信风险策略中,一般都会设置内部准入规则、反欺诈规则、外部准入规则、定额定价等环节。从更为抽象的角度,我们可将风控规则分为两种:
1、硬规则(hard rule):严拒规则,一般阈值固定下来后不再改变。典型的规则,包括严重多头借贷、高危设备行为等。
2、软规则(soft rule):信用模型分可归类于此。为控制通过率稳定,我们一般可调整模型分数的阈值cutoff。
那么,我们如何快速发现一些硬规则呢?假设变量具有一定的排序性,那么通常在两端的人群是目标群体。暂不考虑某些变量呈现两端风险低,而中间取值段风险高的情况,我们将实际场景简化为两种情况:
1、取值越小,坏人浓度越高
2、取值越大,坏人浓度越高
如图2所示, seg1 和 seg2 是潜在的目标子群体,分别对应分位数 x1-α 和 xα 。目标群体的规模可通过分位数 α 进行控制。
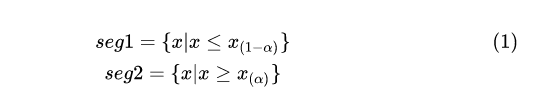
我们将目标子群体圈定出来,并评估坏人浓度,以及相对于总体的提升度(Lift)等指标。

我们可以暴力枚举出所有的变量规则,并结合业务含义筛选出满足要求的规则。对于排黑硬规规则的制定,这是一种颇为有效的方法。
rule_discover(input_df=df, var='score', target='is_bad')

在图3中,我们同样需要兼顾hit_rate和hit_bad_rate的关系,当hit_size过小时,计算hit_bad_rate容易发生波动,从而导致结果不可靠。
实现图3统计结果的Python代码如下所示:
def rule_evaluate(selected_df, total_df, target):"""规则评估"""# 命中规则的子群体指标统计hit_size = selected_df.shape[0] hit_bad_size = selected_df[target].sum()hit_bad_rate = selected_df[target].mean()# 总体指标统计total_size = total_df.shape[0] total_bad_size = total_df[target].这篇关于PRIM(Patient Rule Induction Method)规则发现算法在风控中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




