本文主要是介绍SIGIR 2022 | 从Prompt的角度考量强化学习推荐系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

©编辑 | 李晨亮
来源 | 社媒派SMP


引言
Next item 推荐系统是现代在线网络服务的核心组件之一,根植于应用程序中,例如音乐、视频和电子商务网站,帮助用户(user)导航和查找新内容。一般来说,系统被建模为序列预测任务,通常在递归神经网络或其他生成序列模型之上实现。其目的在于回答问题:在知晓用户过去的交互情况下,用户感兴趣的下一个物品 (item) 是什么。
强化学习是训练 Agent 在给定观察到的环境状态的情况下采取相应行动,以最大化预定义的奖励。现有的基于价值的 RL 算法通常涉及策略评估和策略改进,分别如图 1a 和图 1b 所示。因为强化学习自然符合推荐系统的优化目标:最大化一个交互会话的总体收益,RL 中灵活的奖励设置可以灵活地定制推荐目标。因此,在推荐中使用 RL 已成为一个新兴话题。
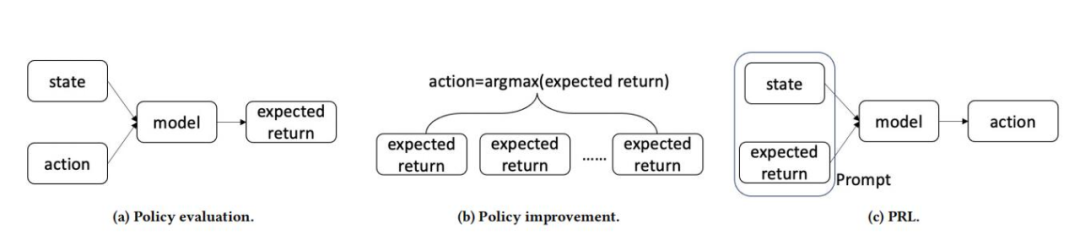
▲ 图1. 策略评估算法、策略改进算法和PRL范式
然而,发展基于强化学习的推荐方法并非易事。具体来说,当前 RL 的学习范式通过与环境交互然后观察奖励来训练主体(Agent)。这个过程需要 Agent 本身进行大量的交互。传统 RL 的关键是通过大量在线探索试错来训练推荐引擎,但在推荐系统中,我们无法进行大量在线试错,糟糕的推荐结果会影响用户体验。因此,需要通过在不同推荐策略下收集的历史隐性反馈进行推荐引擎的离线训练。然而,历史数据不是由 Agent 本身产生的,而是来自不同甚至未知的行为策略。策略评估的期望估计很容易受到分布差异的影响,即所谓的离线训练挑战。
针对离线训练的场景,我们提出了一种新的学习范式,基于提示的强化学习 (Prompt-Based Reinforcement Learning, PRL)。传统的 RL 算法试图将“状态-行为”输入对映射到预期的奖励,而 PRL 直接从“状态-奖励”输入中推断行为,如图 1c 所示。
简而言之,通过简单的监督学习,根据先前的交互和观察到的奖励价值训练 Agent 来预测推荐的物品。在部署时,历史(训练)数据充当知识库,“状态-奖励”对充当提示。因而 Agent 将用来解决问题:在给定的先前交互与提示的价值奖励条件下,应该推荐哪种物品?我们在四种推荐模型上实例化 PRL,并在两个电子商务数据集上进行实验,实验结果表明了我们方法的有效性。
我们工作的贡献总结如下:
1. 对于基于强化学习的 Next item 推荐系统的离线训练,我们提出了 PRL。我们建议使用“状态-奖励”对作为提示,通过查询历史隐式反馈数据知识库来推断行为。
2. 我们提出使用一个有监督的自注意力模块来学习和存储“状态-奖励”对的输入和行为的输出之间的信号。
3. 我们在四种推荐模型上实例化 PRL,并在两个真实世界的电子商务数据集上进行了实验。实验结果表明,推荐性能有了普遍的提高。

基于提示的强化学习
在本节中,我们将详细介绍使用 PRL 的 Next item 推荐的训练和推理过程。
在训练阶段,使用生成序列模型将用户之前的交互编码为隐藏状态,将历史数据组织在 {state, cumulative reward}–>{observed action}({状态,累积奖励}–>{行为}) 模板中,然后使用监督自注意力模块来学习和存储这些信号。PRL 训练过程包括三个部分:提示生成、提示编码和有监督的注意力学习,如图 2 所示。
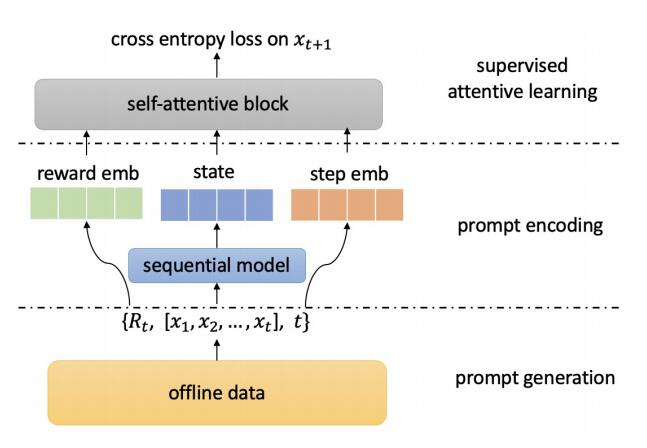
▲ 图2. PRL的训练框架
提示生成旨在将离线训练数据制定为知识模板,即在先前 user-item 交互序列为 的条件下,如果我们想要获得累积奖励 ,则应该采取行动 。提示编码旨在利用深度神经网络将生成的提示映射成为 hidden state 表示。监督自注意力学习模块则用来学习和存储经过编码的 prompt 潜在表示和观察到的行为之间的映射信号。图 3 中的算法给出了 PRL 的 prompt 生成过程。

▲ 图3. PRL的训练模版生成过程
在推理阶段,给定当前状态,我们向模型提供我们想要获得的预期累积奖励,模型可以通过查询历史知识库直接推断行为。在训练过程中,累积奖励可以从离线数据中计算出来,而对于模型推理,我们需要提供推理奖励(prompt reward),以便 Agent 可以根据奖励来调整行为,实现探索。

实验
我们用四种基于深度学习的序列推荐模型来实例化 PRL,在两个电商数据集,Challenge15 和 RetailRocket4,进行了实验。实验旨在回答以下三个研究问题,以验证 PRL 学习范式的有效性:
1. 当在不同的序列推荐模型上实例化时,PRL 的表现如何?
2. 包括自注意力模块和加权损失函数在内,监督注意力学习的效果是什么?
3. 在推理阶段,prompt reward 设置如何影响 PRL 的表现?
针对问题一,我们通过与基线模型进行比较,在两个数据集上实验结果如表 1 和表 2 所示。无论在 Challenge15 数据集还是在 RetailRocket4 数据集上,PRL 在几乎所有情况下都取得了最好的性能,证明了 PRL 持续且显著地提高了基于 RL 的推荐任务的离线学习性能,并可应用于各种序列推荐模型。
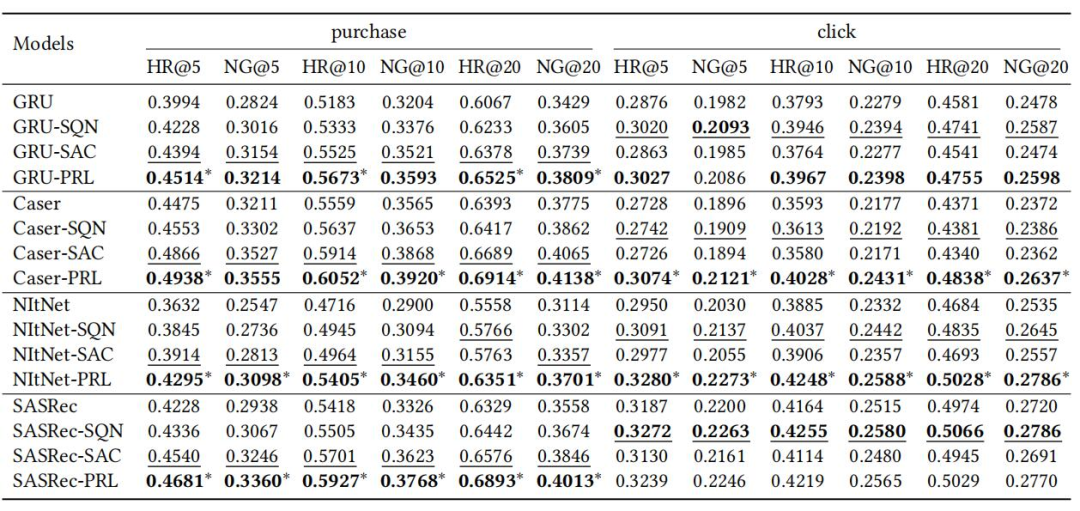
▲ 表1 PRL和其他模型在Challenge15数据集推荐性能比较
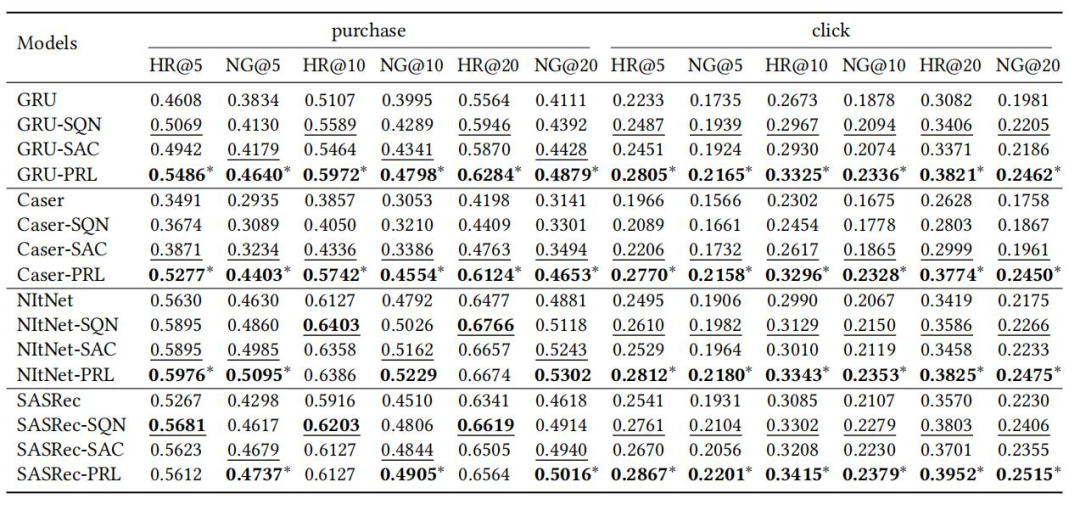
▲ 表2. PRL和其他模型在RetailRocket4数据集推荐性能比较
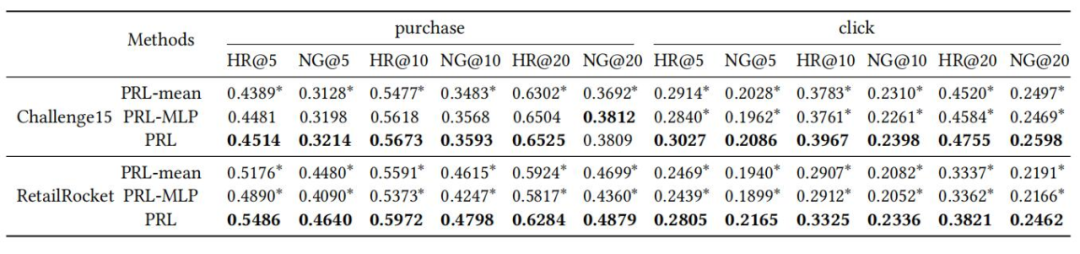
▲ 表3. 自注意力模块的效果
针对重新加权模式(re-weighting)的效果研究,我们与没有任何重新加权(即PRL-w/o)的 PRL 的结果和通过累积奖励(即 PRL-cumu)重新加权的 PRL 的结果进行对比,结果如表 4 所示,证明了 PRL 的 re-weighting 成功地帮助模型推荐更多有更高的 prompt reward 的购买产品。
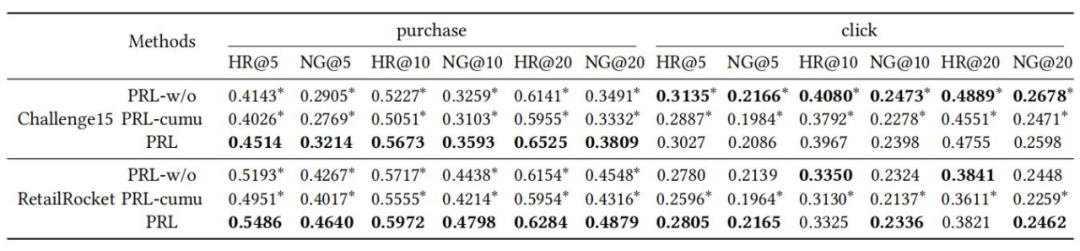
▲ 表4. 加权损失的影响
针对问题三,我们进行实验,通过研究推理奖励期望 μ 与推理奖励偏差 ϵ 的影响,以了解推理奖励设置如何影响模型的性能。结果分别如图 4 和图 5 所示:
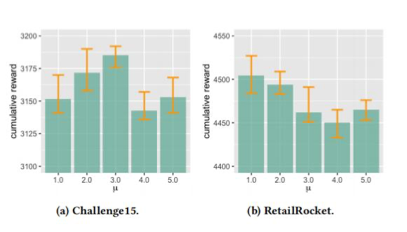
▲ 图4. 推理奖励期望μ的效果
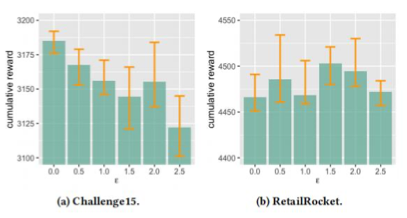
▲ 图5. 推理奖励偏差ϵ的效果

总结
我们提出了 prompt-based 强化学习的方法,用于基于强化学习的 Next item 推荐引擎的离线训练。从理论上分析了利用 RL 进行推荐时的离线训练挑战,我们建议将历史离线数据作为知识库,将推荐任务制定为问题:如果在状态观察下期望获得 prompt reward,应该采取什么行动。我们使用四个序列推荐模型实例化了 PRL,并在两个真实世界的数据集上进行实验,证明了所提方法的有效性。

送福利啦!
独家定制炼丹中/Fine-Tuning
超超超超超大鼠标垫
限量 200 份
扫码回复「鼠标垫」
立即免费参与领取
👇👇👇

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·

这篇关于SIGIR 2022 | 从Prompt的角度考量强化学习推荐系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




