本文主要是介绍【解决方案】成功解决将XGBoost中plot_importance绘图时出现的f0、f1、f2、f3、f4、f5等改为对应特征的字段名,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.问题描述
使用XGBoost中的plot_importance绘制特征重要性图时,纵坐标并不是特征名,而是f0、f1、f2、f3、f4、f5…fn等一系列符号。
2.问题结果
成功解决将XGBoost中plot_importance绘图时出现的f0、f1、f2、f3、f4、f5等改为对应特征的字段名。
3.解决方案
3.1 项目描述
使用XGBoost模型训练sklearn中的乳腺癌数据(二分类,这篇文章中,介绍过此数据集:【ML】机器学习数据集:sklearn中分类数据集介绍),对训练后的模型中的特征重要性进行排序,即可视化模型中的特征重要性。
3.2 项目初始代码
# -*- coding: utf-8 -*-
"""
Created on Thu Sep 29 13:47:06 2022@author: augustqi
"""# 导入需要的包
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score, accuracy_score, auc, recall_score, precision_score, f1_score
from sklearn.metrics import roc_curve, precision_recall_curve, average_precision_score
from xgboost import XGBClassifier
from xgboost import plot_importance# 加载数据集,这里直接使用datasets包里面的乳腺癌分类数据(二分类)
cancer = datasets.load_breast_cancer()X = cancer.data
y = cancer.target# 输出数据集的形状,该数据集里面有569个样本,每个样本有30个特征(569, 30)
print(X.shape)
# 输出标签的个数为 569
print(y.shape)# 使用train_test_split()函数对训练集和测试集进行划分,第一个参数是数据集特征,第二个参数是标签,第三个为测试集占总样本的百分比
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 6)# 使用XGBoost进行训练
model = XGBClassifier()
model.fit(x_train,y_train)# 绘制重要性曲线, max_num_feature参数设置输出前30重要的特征,【数据集中共有30个特征】
fig, ax = plt.subplots(figsize=(10,8))
plot_importance(model, max_num_features=30, ax=ax)
plt.savefig("demo_plot_importance.png", dpi=600)
plt.show()# 类别值
y_pred = model.predict(x_test)# 输出ACC的值
acc = accuracy_score(y_test, y_pred)
print("acc:", acc)
# 输出recall值
re = recall_score(y_test, y_pred)
print("recall:", re)
# 输出precision
pre = precision_score(y_test, y_pred)
print("precision:", pre)
# 输出f1 score
f1 = f1_score(y_test, y_pred)
print("f1 score:", f1)# 概率得分
y_score = model.predict_proba(x_test)[:,1]# 直接计算auc的值
auc_1 = roc_auc_score(y_test, y_score)
print("auc_1:", auc_1)# 绘制ROC曲线
fpr, tpr, thresholds_roc = roc_curve(y_test, y_score)
# 间接计算auc的值
auc_2 = auc(fpr, tpr)
print("auc_2:", auc_2)# 间接计算auc的值的好处,就是可以知道fpr和tpr,绘制曲线
plt.plot(fpr,tpr,'r--', label='auc=%0.4f'%auc_2)
plt.title("ROC Curve")
plt.legend()
plt.savefig("demo_roc.png",dpi=600)
plt.show()# 绘制PR曲线
precision, recall, thresholds_pr = precision_recall_curve(y_test, y_score)
aupr = auc(recall, precision)
print("aupr:", aupr)
plt.plot(recall, precision, 'g--', label='aupr=%0.4f'%aupr)
plt.title("PR Curve")
plt.legend()
plt.savefig("demo_pr.png",dpi=600)
plt.show()
测试集上的一些统计指标:
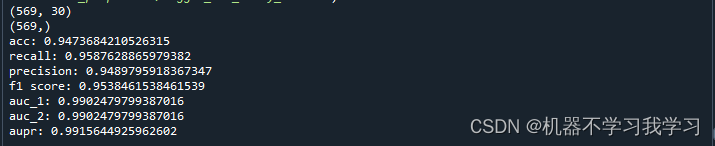
ROC曲线:
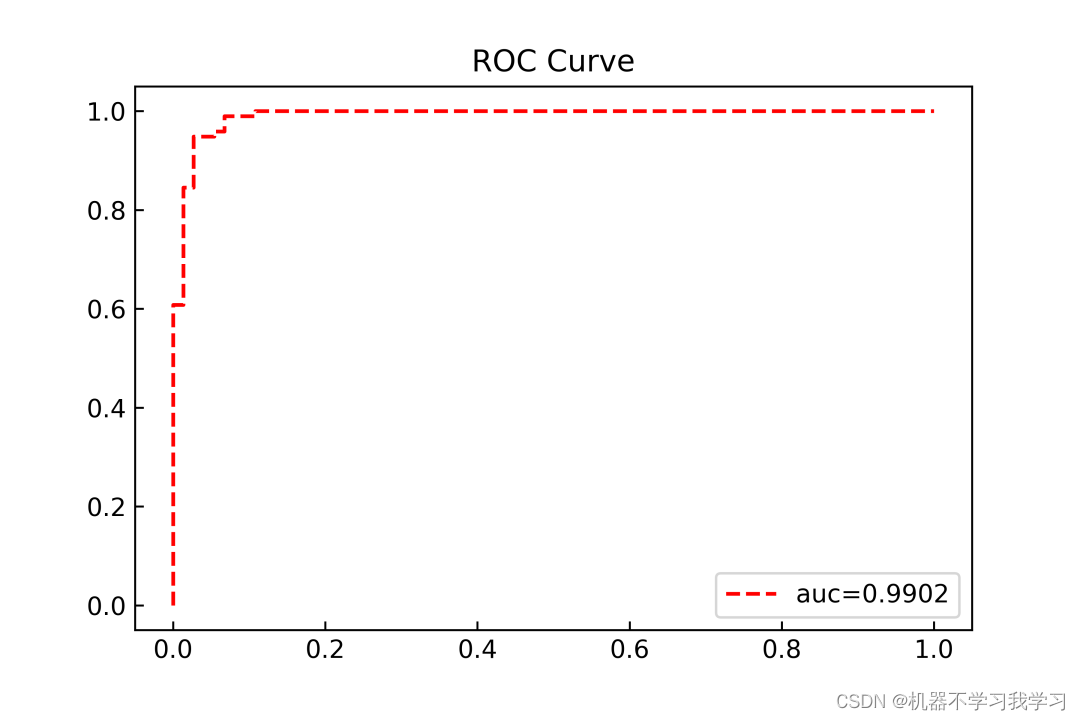
PR曲线:
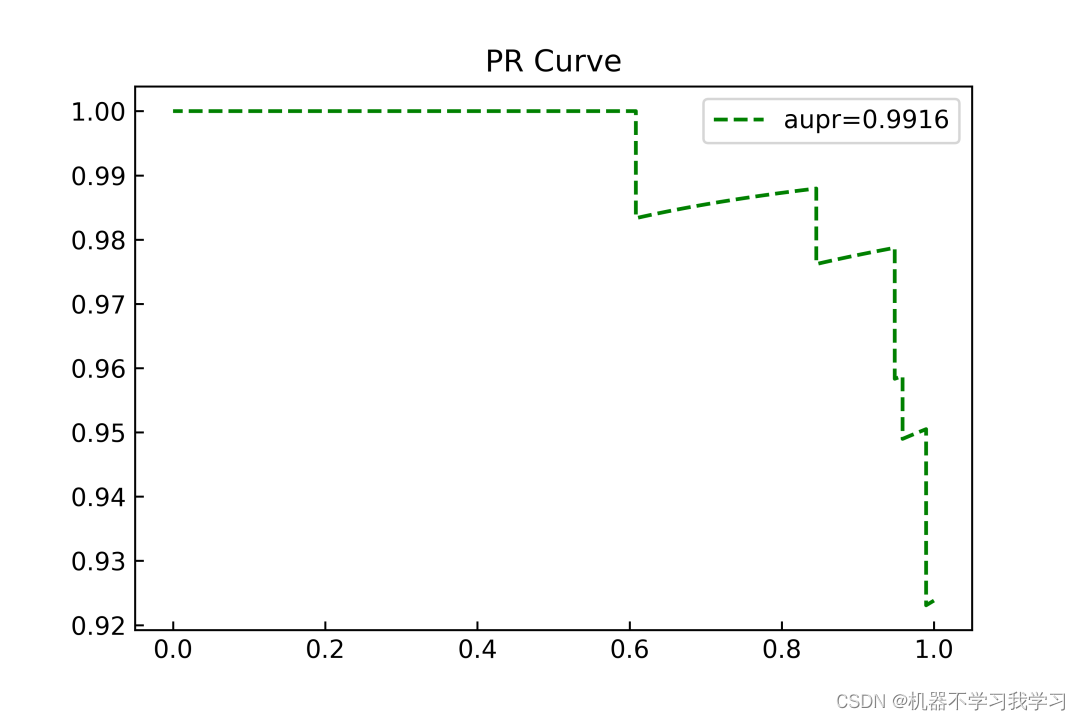
特征重要性图:
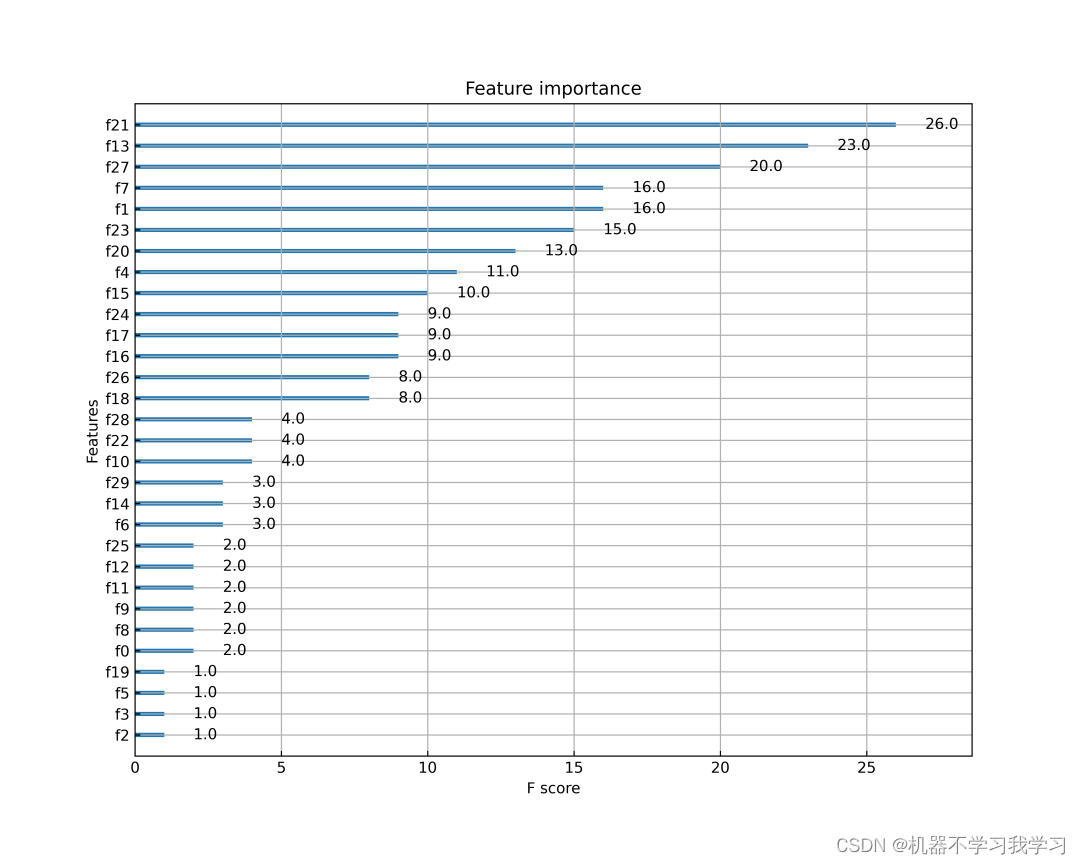
我们主要看特征重要性图(其他图和统计指标,是我附带送给各位的,不是本文的重点,嘿嘿),输入到XGBoost模型训练的数据共有30维,即30个特征,哪这30个特征分别对模型的影响是多少呢?请往下看。
随着科学技术的发展,机器学习这个黑盒子也在被慢慢打开,XGBoost中提供了一个plot_importance函数用于绘制特征的重要性。从特征重要性图可以看到f0、f1、f2、f3…f29,这些符号对应数据集中的30个特征,但是我们如何将纵坐标的这些符号换成对应的特征名呢?从而可以更直观看到特征的重要性。
我们只需在初始的项目代码中加入:
feature_names = cancer.feature_names
feature_names = list(feature_names)model.get_booster().feature_names = feature_names
然后绘制具有特征名的特征重要性图:
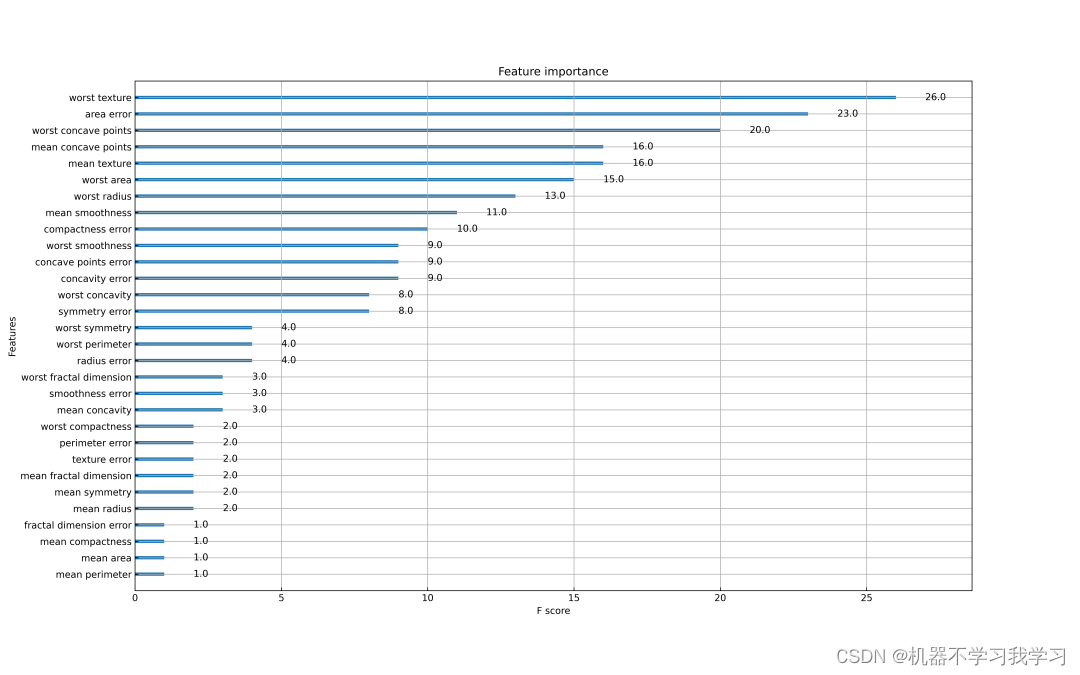
大功告成,f0、f1、f2、f3…f29成功和数据集中的特征名对应起来了,可以看到worst texture(f21)特征对模型的影响最大。
3.3 项目最终代码
# -*- coding: utf-8 -*-
"""
Created on Thu Sep 29 13:47:06 2022@author: augustqi
"""# 导入需要的包
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score, accuracy_score, auc, recall_score, precision_score, f1_score
from sklearn.metrics import roc_curve, precision_recall_curve, average_precision_score
from xgboost import XGBClassifier
from xgboost import plot_importance# 加载数据集,这里直接使用datasets包里面的乳腺癌分类数据(二分类)
cancer = datasets.load_breast_cancer()X = cancer.data
y = cancer.target
feature_names = cancer.feature_names
feature_names = list(feature_names)# 输出数据集的形状,该数据集里面有569个样本,每个样本有30个特征(569, 30)
print(X.shape)
# 输出标签的个数为 569
print(y.shape)# 使用train_test_split()函数对训练集和测试集进行划分,第一个参数是数据集特征,第二个参数是标签,第三个为测试集占总样本的百分比
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 6)# 使用XGBoost进行训练
model = XGBClassifier()
model.fit(x_train,y_train)model.get_booster().feature_names = feature_names# 绘制重要性曲线, max_num_feature参数设置输出前30重要的特征,【数据集中共有30个特征】
fig, ax = plt.subplots(figsize=(16,10))
plot_importance(model, max_num_features=30, ax=ax)
plt.savefig("demo_plot_importance.png", dpi=600)
plt.show()# 类别值
y_pred = model.predict(x_test)# 输出ACC的值
acc = accuracy_score(y_test, y_pred)
print("acc:", acc)
# 输出recall值
re = recall_score(y_test, y_pred)
print("recall:", re)
# 输出precision
pre = precision_score(y_test, y_pred)
print("precision:", pre)
# 输出f1 score
f1 = f1_score(y_test, y_pred)
print("f1 score:", f1)# 概率得分
y_score = model.predict_proba(x_test)[:,1]# 直接计算auc的值
auc_1 = roc_auc_score(y_test, y_score)
print("auc_1:", auc_1)# 绘制ROC曲线
fpr, tpr, thresholds_roc = roc_curve(y_test, y_score)
# 间接计算auc的值
auc_2 = auc(fpr, tpr)
print("auc_2:", auc_2)# 间接计算auc的值的好处,就是可以知道fpr和tpr,绘制曲线
plt.plot(fpr,tpr,'r--', label='auc=%0.4f'%auc_2)
plt.title("ROC Curve")
plt.legend()
plt.savefig("demo_roc.png",dpi=600)
plt.show()# 绘制PR曲线
precision, recall, thresholds_pr = precision_recall_curve(y_test, y_score)
aupr = auc(recall, precision)
print("aupr:", aupr)
plt.plot(recall, precision, 'g--', label='aupr=%0.4f'%aupr)
plt.title("PR Curve")
plt.legend()
plt.savefig("demo_pr.png",dpi=600)
plt.show()
本篇博文,首发在AIexplore微信公众号,内容总体相同,均为原创,特此申明。
参考资料
[1] https://www.cnblogs.com/hellojiaojiao/p/10755878.html
[2] https://zhuanlan.zhihu.com/p/361214293
[3] https://www.lmlphp.com/user/16834/article/item/504015/
[4] https://stackoverflow.com/questions/46943314/xgboost-plot-importance-doesnt-show-feature-names
这篇关于【解决方案】成功解决将XGBoost中plot_importance绘图时出现的f0、f1、f2、f3、f4、f5等改为对应特征的字段名的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









