本文主要是介绍Product1M: Towards Weakly Supervised Instance-Level Product Retrieval via Cross-ModalPretraining论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2021年ICCV《ICCV2021 Product1M_Towards_Weakly_Supervised_Instance-Level_Product_Retrieval_via_Cross-Modal_Pretraining》
代码地址: https://github.com/zhanxlin/Product1M.
主要研究在弱监督的多模态数据场景下,电商领域的产品检索,论文贡献主要在二:
- 实例级检索的最大的多模态化妆品数据集,Product1M。包含超过100万个图像-标题对,由两种类型的样本组成,即单产品和多产品样本。每个单产品样本都属于一个细化的类别,类别间的差异很细微。多产品样本具有很大的多样性,导致复杂的组合和模糊的对应关系,很好地模仿了现实世界的场景。
- 提出了cross-modal contrAstive Product Transformer for instancelevel prodUct REtrieval,CAPTURE,它擅长于以自我监督的方式捕捉多模态输入之间的隐含协同作用。
1 背景
首先对比了两种检索模式,图像级检索和多模态实例级检索。
图像层面的检索倾向于返回琐碎的结果,因为它不区分不同的实例,而多模态实例层面的检索则更有利于在多模态数据中搜索各种实例产品。如下图。

在过去的二十年里,一方面,网上商品的类别越来越多样化,其中很大一部分是以产品组合的形式展示的,不同产品的多个实例存在于一个图像中。
另一方面,在线客户或商家可能希望检索组合中的单个产品进行价格比较或在线商品推荐。
此外,随着多媒体产生的异质数据的不断加速积累,算法如何处理大规模和弱注释的数据]来进行多模式检索仍然是一个问题。
因此,本文讨论了,如何在给定弱监督多模态数据的情境下,进行实例级细粒度的产品检索。
2 模型设计
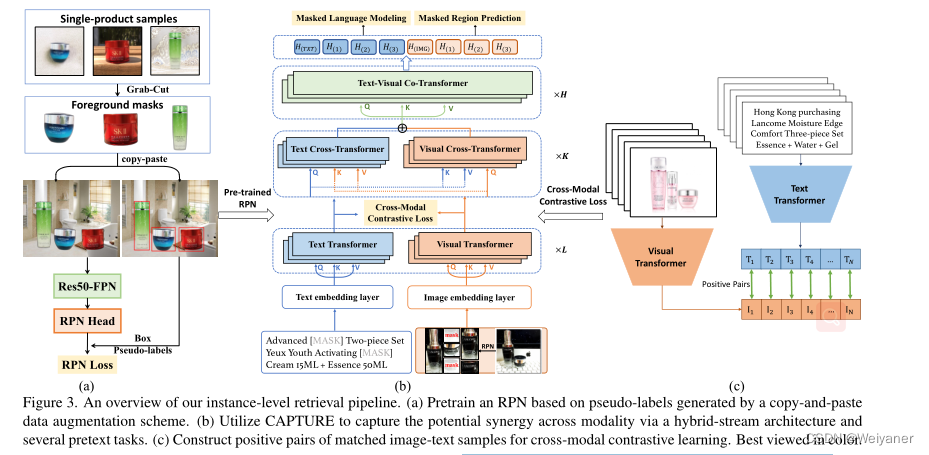
1 Region Proposal Network (RPN)
仅仅基于图像层面的特征进行检索会导致检索结果被图像中的主要产品所淹没。
因此,在多产品图像中区分不同的产品并提取有用的特征是至关重要的。因此,我们利用一个简单而有效的数据增强方案来训练一个仅基于单产品图像的区域建议网络(RPN)如图3(a)所示。我们首先使用GrabCut[28]来获得单品图像的前景掩码。利用来自Places365[51]的真实世界背景图像,对这些前景遮盖和背景图像进行复制和粘贴增强,以生成合成的图像。通过这种方式,我们能够训练一个性能良好的多产品检测器。鉴于检测到的RPN区域,我们利用RoIAlign来获得实例的特征,然后将其输入CAPTURE,以进一步进行跨模式学习。
2 CAPTURE的架构
与普遍存在的单流或双流transformer架构不同,我们提出的CAPTURE将这两种架构结合成一个统一的架构,通过堆叠三种类型的层来进行语义对齐和多模态输入的联合学习。见图3(b)。
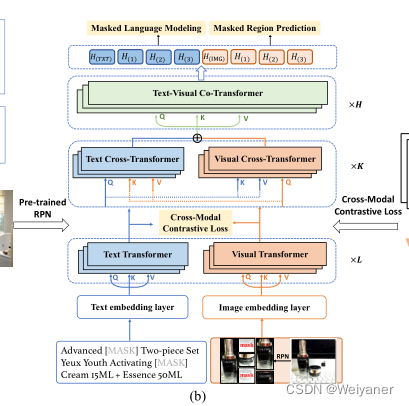
具体来说,文本/视觉转换器将文本或图像的嵌入作为输入,负责模态内的特征学习。
文本/视觉交叉transformer块旨在通过在多头注意力机制中交换键值对来捕捉和模拟文本和图像之间的模式间关系。之后,文本和图像的特征被串联起来,并作为查询、键和值输入到联合transformer中,用于多模态特征的联合学习。
3 多模态掩码学习任务
通过利用几个掩码任务来实现CAPTURE的自我监督学习。对于多模态对的特征学习,我们根据BERT[9]和VisualBERT[25],采用了两个多模态掩码建模任务,即掩码的语言建模任务(MLM)和掩码的区域预测任务(MRP)。
具体来说,对于MLM和MRP,大约15%的文本和建议输入被mask掉,其余输入被用来重建被mask的信息。对于MRP,模型直接回归被mask的特征,这是由预训练的RPN和MSELoss提取的特征进行监督。
对于模态间的关系建模,通常情况下,模型被要求预测文本是否是图像的相应描述,这被表述为一个二元分类任务。为了产生负样本,图像或标题被随机替换。
4 模态间的对比损失函数
除了模态内的损失,采用了模态间的对比学习损失来表达图像和文本之间的一致性。这种形式的对比损失函数鼓励来自不同模态的正向对的编码特征相似,而对负对的编码特征进行区分。
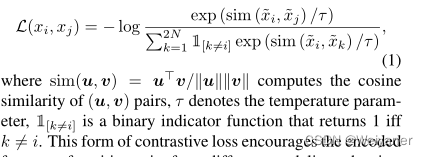
5 Capture的推理过程
对于单产品和多产品样本,通过预训练的RPN提取的关键性特征被用作CAPTURE的输入。在推理过程中,协同转化器层分别输出HIM G和HT XT作为视觉和语言输入的总体表示。这两个向量相乘,得出一个实例的联合表达。
这篇关于Product1M: Towards Weakly Supervised Instance-Level Product Retrieval via Cross-ModalPretraining论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







