本文主要是介绍关于VSM性能优化的思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
blog可能排版更好点
Github
Update 一下
跟室友讨论了一下 才发现有一些我以为很理所应当的点 才是优化的关键 (当然你们看我的code应该也能看出来 只是没点明白)
Optimize Point
- 不要试图去开大数据量的二维数组
- 一旦你初始化一个3k✖️3k的数据 你就会发现即使你只是读一下这个数组就会死慢死慢 还要频繁写入 效率可想而知
- 正确的姿势 应该是开一个一维的数组 然后每次存入一个3k数组的Index
- 这么做是有道理的
- 首先实际数组 相对于动态开起来的
- 然后我们存在一维数组里的 实际上是Index值 这个会快很多
- 而且存进去的数组 是
Immutable-不(可)更改的 不需要update 这个又会快很多 - 于是乎 这就是第一个
bonus Ponit
- 要用
Numpy的矩阵乘法 ?不要手写
- 虽然 我不知道它的内部实现机理 但真的很快
- 快到瞠目结舌 3k✖️6w的矩阵相乘 10s不到
- 这 我3k✖️3k遍历一遍就要1min
- 可以考虑动态对齐词矩阵 降低词向量维数
- 目前我们是按所有文章中词向量维数为所有词向量的长度 大约6w维
- 如果按每个article为粒度 用动态对齐的方式 可以省很多空间
- 我之所以没这么干
- 因为我tf做了smooth操作 所有零项 不能简单的补零 复杂度较高
- 然后动态补零 就不能用
numpy的矩阵乘法 就很伤
- 另外就是通过开线程实现加速操作
剩下的看代码应该就会懂得 (这样应该干货多了吧)
然后吕同学提的预处理的问题 挺好的 词性确实很重要
做了个小统计发现整个词袋里面有5477个词有多重词性的 高等词还有8个词性 so 呢
VSM很简单 但hand write起来 还是会有一些问题的
Preproccess
额 我们拿到的文本 虽然已经分词好了 但 并不是很能用
所以我们需要预处理
对于这种文本的预处理 shell是最好的选择 (不是php 手动滑稽)
shell 或者说bash脚本 性能对于这种文本处理基本上是秒级的
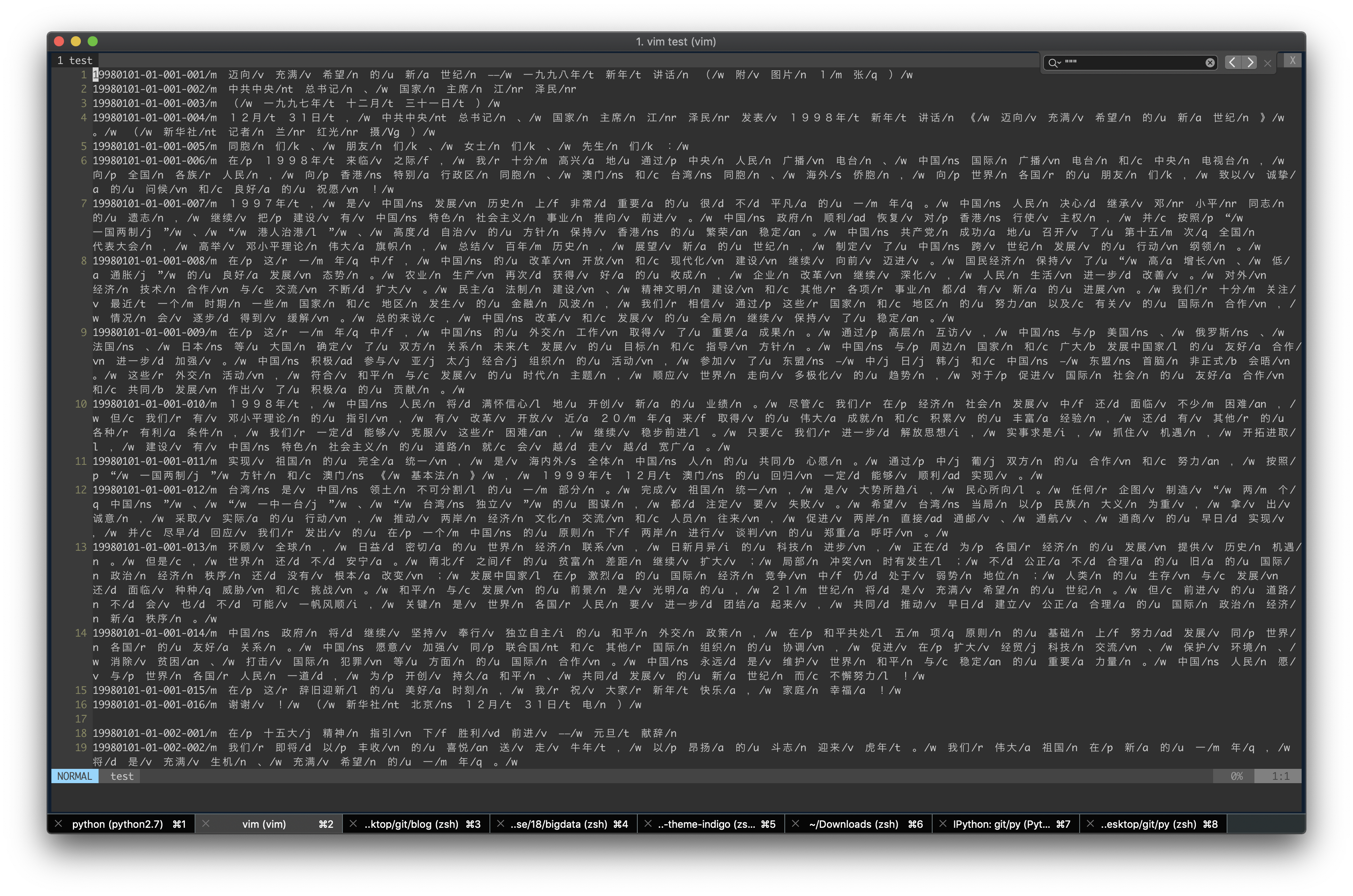
可以看出好像前面15位的 代表ArticleId 属于同一个文章
然后虽然分词过了 但有很多分隔符什么/ n, / c, / vn
本来我是想枚举的 但发现 好像26个字母都有 真的恐怖
然后不只有这些 还有中文标点 什么《》, ()的 也得去掉
然后整理一下就变成了
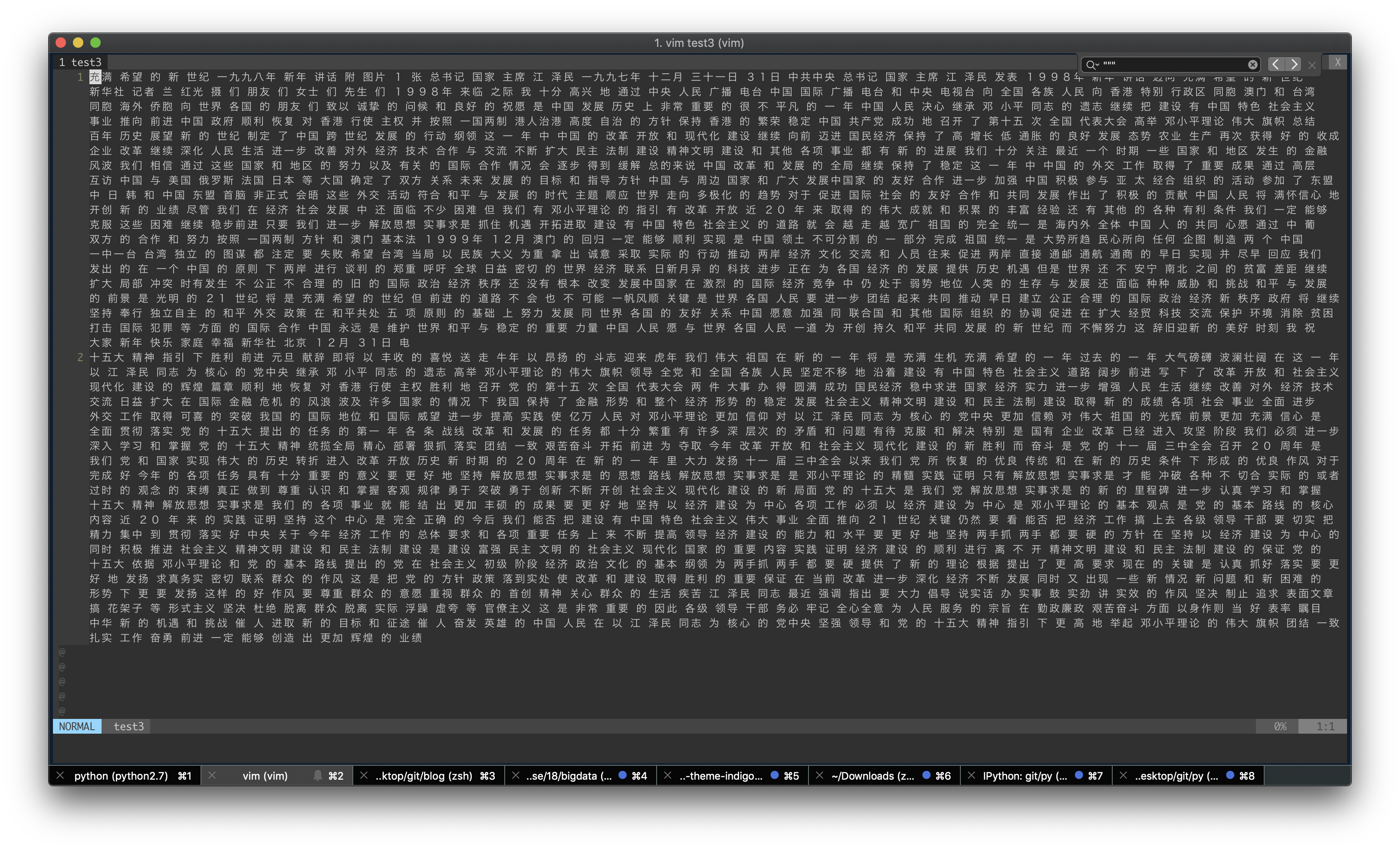
性能方面 虽然没打时间 但基本上秒级
附上code
# @Author: gunjianpan
# @Date: 2018-11-11 19:11:19
# @Last Modified by: gunjianpan
# @Last Modified time: 2018-11-11 20:26:47cp data.txt test
# Set Tag Where File End
echo '1' >> test# According article to jonit string
# @1: Remove blank lines
# @2: split by ‘/x’ or ‘/xx’
# then, jonit string until into another article(recognition by $1)
# @return: Plain text which one plain one artile
sed - n '/./p' test | awk '{split($0,a,"/. |/.. ");b="";for(i=3;i<length(a);i++){b=b" "a[i];}if(!last||last==substr($1,0,15)){total=total""b;}else{print substr(total,2);total=b;}last=substr($1,0,15)}' >> test2# Remove Chinese punctuation
# @1: replace punctuation Chinese or English to blank
# @2: replace mutil-blank to one-blank
sed 's/[;:,。()?!《》【】{}“”、——;:,.()?!_]/ /g' test2 | sed 's/[ ][ ]*/ /g' >> test3
VSM
VSM分三步
- 词长度对齐
- TF - IDF(考虑平滑, similarity 方式)
- one by one calaulate
思路很简单
我一开始觉得 TF - IDF计算需要针对每个(article1, article2)进行计算
因为需要对齐 而且最关键要平滑
如果有个词article1没有,article2也没有 如何计算tf的时候因为进行平滑处理 就会占一定比例 这对于那些高词频的 word就不太友好
于是我第一版 就 一个个遍历过去 3100✖️3100 (见VSM.vsmCalculate())
看起来 没啥 乘起来就是500w
初始化数组就要1min
于是开了两级多线程
- 每行为一个线程
- 每行里面每组similarity计算为一个线程
但效果很差 因为那么多个线程争夺写一个3100✖️3100的numpy.Array 出现了写阻塞现象
通过Activity Monitor观察 实际上线程数只有5.6左右
把numpy.Array换成list 发现效率高了一点 还是不行
于是 想能不能不同时争夺写一个list 直接每一行维护一个list 直接写文件
发现效率提高很多 基本上1s能处理500个数据
那500w需要3h+
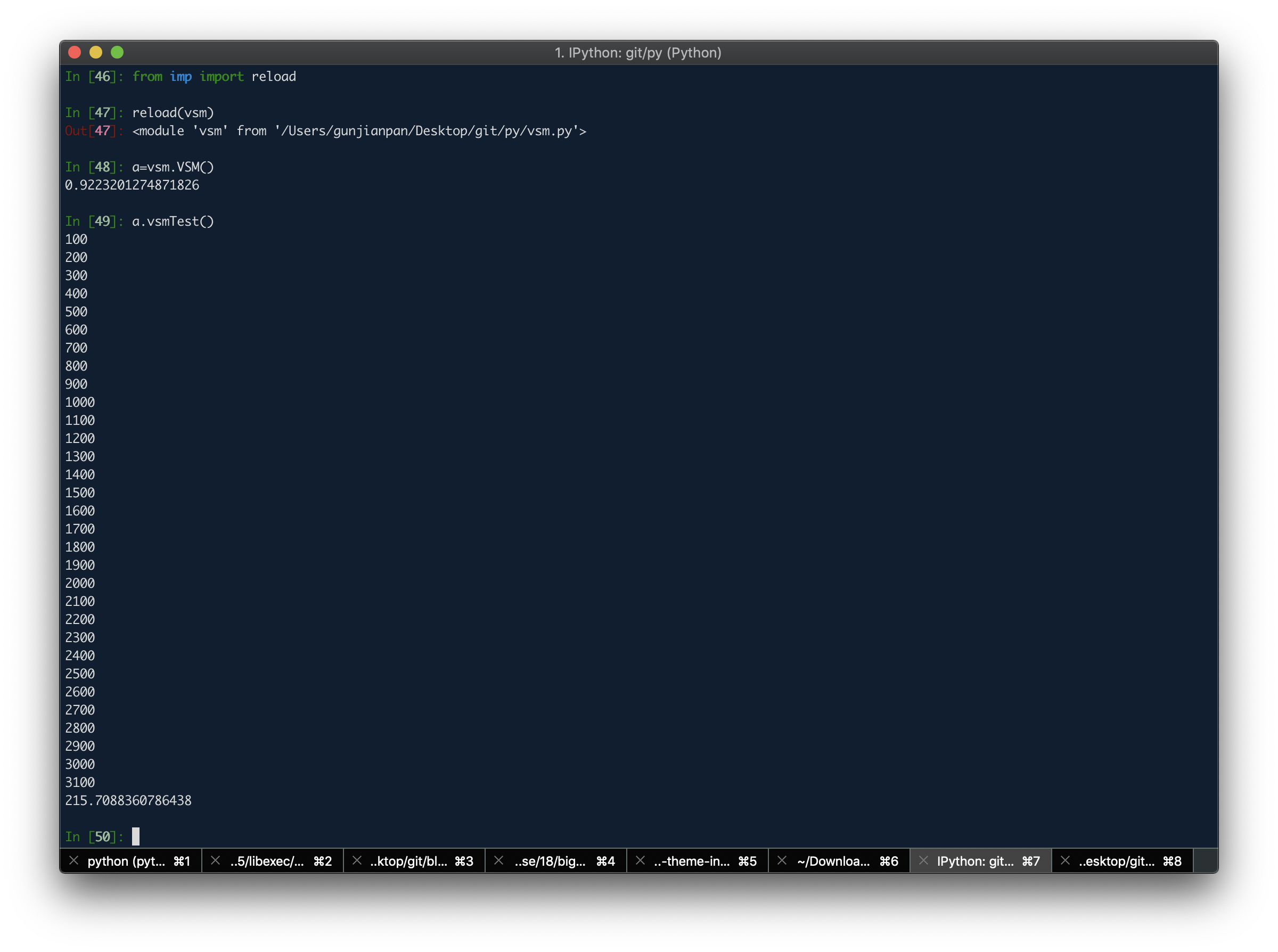
于是牺牲一下精确度 先按词袋里所有词 对齐词向量(见VSM.vsmTest())
如何先生成3100篇文章的词向量组(tf - idf之后)
再做一次 A.dot(A.T)就可以得到结果
实际效果总耗时215s 约3min 效果较好
然后一次误输出 发现内存中的中间状态数组已经到了4.3G
额 内存小的同学可能就比较尴尬了
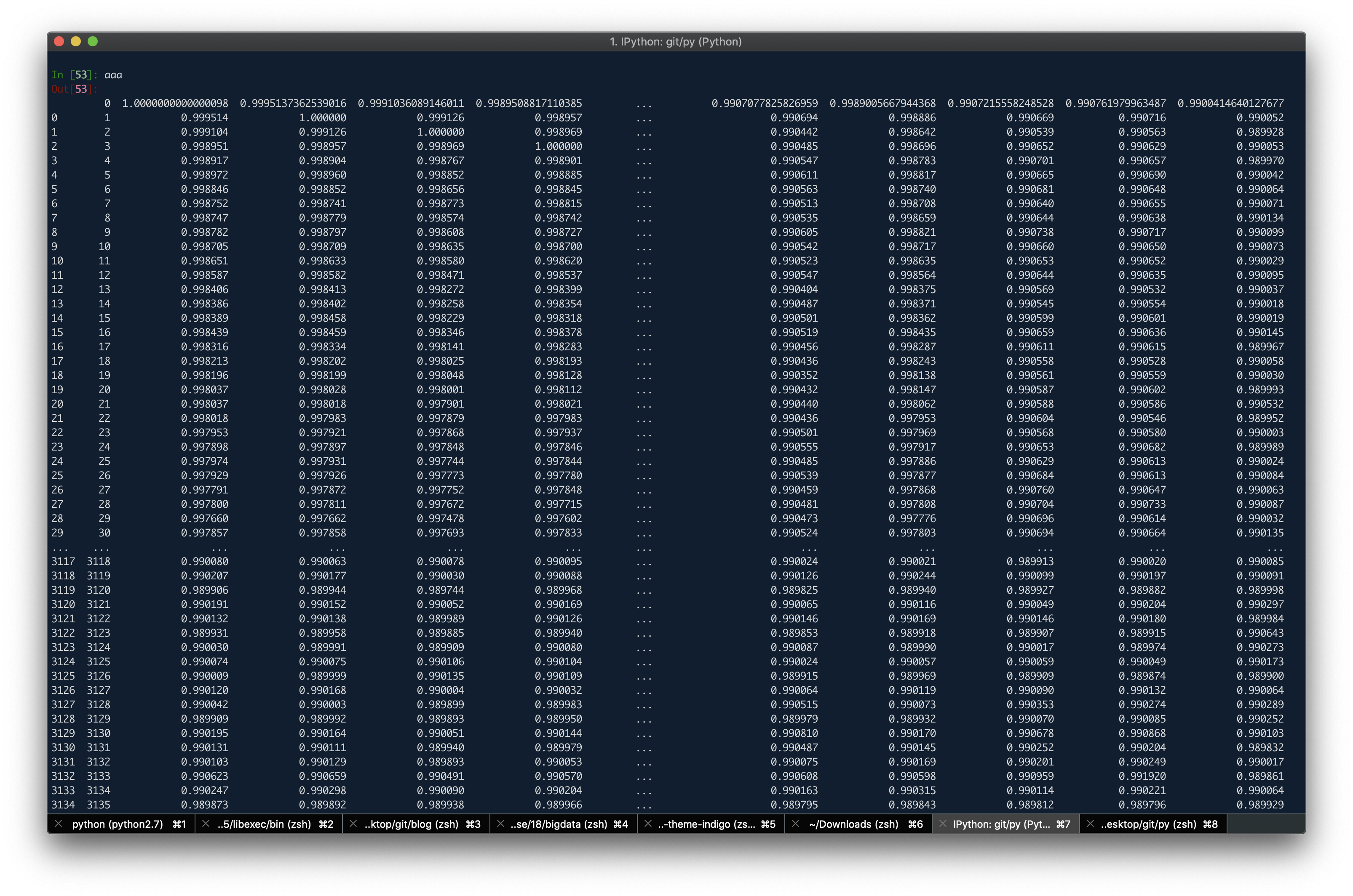
关于隐语义等考完试再来弄
之前写过一篇关于时序分析相关内容RNN家族的blog
# -*- coding: utf-8 -*-
# @Author: gunjianpan
# @Date: 2018-11-11 20:27:41
# @Last Modified by: gunjianpan
# @Last Modified time: 2018-11-13 01:07:16import math
import numpy as np
import pandas as pd
import threading
import timeclass VSM():"""handle write vsm ?"""def __init__(self):self.articleMaps = []self.articleNum = 0self.process = 0self.resultArray = []self.wordMaps = {}self.preData()def preData(self):"""data prepare"""begin_time()file_d = open('test3', 'r')articles = file_d.readlines()threadings = []self.articleNum = len(articles)self.articleMaps = [None for i in range(self.articleNum)]self.resultArray = [None for i in range(self.articleNum)]for index in range(self.articleNum):work = threading.Thread(target=self.preDataBasic, args=(articles[index].strip('\n').rstrip(), index,))threadings.append(work)for work in threadings:work.start()for work in threadings:work.join()end_time()def preDataBasic(self, article, articleId):"""prepare data basic in Threading@param article: article string@param articleId: article id"""words = article.split(' ')wordMap = {}for word in words:if word in wordMap:wordMap[word] = wordMap[word] + 1else:wordMap[word] = 1for word in wordMap:if word in self.wordMaps:self.wordMaps[word] = self.wordMaps[word] + 1else:self.wordMaps[word] = 1self.articleMaps[articleId] = wordMapdef tfidfTest(self, wordMap):"""calculate tdidf valuetd use Augmented Frequency 0.5 + 0.5 * fre/maxFre"""wordlist = [wordMap[i] for i in [*wordMap]]maxFrequency = max(wordlist)tf = np.array([0.5 + 0.5 * index / maxFrequency for index in wordlist])idf = np.array([math.log(self.articleNum / self.wordMaps[word])for word in [*wordMap]])tfidf = tf * idfreturn tfidfdef tfidf(self, wordMap):"""calculate tdidf valuetd use Augmented Frequency 0.5 + 0.5 * fre/maxFre"""wordlist = [wordMap[i] for i in [*wordMap]]maxFrequency = max(wordlist)tf = np.array([0.5 + 0.5 * index / maxFrequency for index in wordlist])idf = np.array([math.log(self.articleNum / (1 + self.wordMaps[word]))for word in [*wordMap]])tfidf = tf * idfreturn tfidf / np.linalg.norm(tfidf, ord=2)def preSimilarity(self, wordMap, index):"""align map and then calculate one tfidf"""tempMap = {index: wordMap[index] if index in wordMap else 0 for index in self.wordMaps}preMap = {**wordMap, **tempMap}self.resultArray[index] = self.tfidf(preMap)self.process += 1if not self.process % 100:print(self.process)def vsmTest(self):"""once to calaulate vsm"""begin_time()threadings = []for index in range(self.articleNum):work = threading.Thread(target=self.preSimilarity, args=(self.articleMaps[index], index,))threadings.append(work)for work in threadings:work.start()for work in threadings:work.join()tempMatrix = np.array(self.resultArray)result = tempMatrix.dot(tempMatrix.T)df = pd.DataFrame(result)df.to_csv("vsm1.csv", header=False)end_time()def preSimilarityTest(self, wordMap1, wordMap2):"""align map and then calculate one tfidf"""tempMap1 = {index: wordMap1[index] if index in wordMap1 else 0 for index in wordMap2}preMap1 = {**wordMap1, **tempMap1}return self.tfidfTest(preMap1)def similarity(self, wordMap1, wordMap2, types):"""calculate similarity by cos distance@Param types: distance calculate type=0 Cos Distance=1 Chebyshev Distance=2 Manhattan Distance=3 Euclidean Distance"""tfidf1 = self.preSimilarityTest(wordMap1, wordMap2)tfidf2 = self.preSimilarityTest(wordMap2, wordMap1)if not types:return np.dot(tfidf1, tfidf2) / (np.linalg.norm(tfidf1, ord=2) * np.linalg.norm(tfidf2, ord=2))elif types == 1:return np.abs(tfidf1 - tfidf2).max()elif types == 2:return np.sum(np.abs(tfidf1 - tfidf2))elif types == 3:return np.linalg.norm(tfidf1 - tfidf2)else:return np.shape(np.nonzero(tfidf1 - tfidf2)[0])[0]def vsmCalculate(self):"""calculate vsm"""#: todo write blockbegin_time()threadings = []for index1 in range(self.articleNum):work = threading.Thread(target=self.vsmThread, args=(index1,))threadings.append(work)for work in threadings:work.start()for work in threadings:work.join()end_time()def vsmThread(self, index1):"""vsm threading"""nowarticle = self.articleMaps[index1]tempResult = []for index2 in range(index1, self.articleNum):tempResult.append(self.vsmPre(nowarticle, self.articleMaps[index2]))df = pd.DataFrame({index1: tempResult})df.to_csv('vsm.csv', mode='a', header=False)def vsmPre(self, wordMap1, wordMap2):"""load data to resultprevent read block"""self.process += 1if not self.process % 100:print(self.process)return self.similarity(wordMap1, wordMap2, 0)start = 0def begin_time():global startstart = time.time()def end_time():print(time.time() - start)
祝大家考试顺利?
这篇关于关于VSM性能优化的思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



