本文主要是介绍【数字人】5、RAD-NeRF | 通过解耦 audio-spatial 编码来实现基于 NeRF 的高效数字人合成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 一、背景
- 二、方法
- 2.1 问题定义
- 2.2 Decomposed audio-spatial encoding module
- 2.3 Pseudo-3D Deformable Module 用于控制 torso
- 2.4 训练细节
- 三、效果
- 3.1 实验设置
- 3.2 对比
论文:Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition
代码:https://github.com/ashawkey/RAD-NeRF
项目:https://me.kiui.moe/radnerf/
贡献:
- 提出了一个分解音频-空间编码模块,以有效地用两个低维特征网格建模固有高维度的音频驱动面部动态。
- 提出了一个轻量级伪 3D 可变形模块,进一步提高在合成与头部运动同步的自然躯干运动时效率。
- 本文框架比以前工作快 500 倍,并且渲染质量更好,并支持各种明确控制说话人像,例如头部姿势、眨眼和背景图像。
一、背景
Audio-driven 的说话人合成任务有很多应用场景,所以近年来的研究也比较多
有很多方法是基于 landmark 和 meshs 来作为面部结构的先验信息,也就是会借助中间表达特征,很依赖中间特征的效果。
NeRF 能够重建逼真的 3D 场景,NeRFace[19] 首次将 3DMM 引入 NeRF 来控制 head,还有一些方法 [22,32,46] 直接使用声音特征来控制 NeRF,不使用中间特征。但这些方法有一个通病就是很慢,例如 AD-NeRF 在 3090 GPU 上合成一个 450x450 大小的图像帧需要耗时 12s,远远低于实时 25FPS 的要求,且训练一个人需要大概一天的时间,限制了其实际使用。
为了提升效率,一个很直观的方法就是借鉴最近 NeRF 提效的解决方法 [9,10,31,37,45,49,62]。总的来说,就是降低 MLP 大小的同时在一个显示的可训练的网格结构中来保存 3D 场景特征。
之前很耗费资源的 MLP 前向传播就被一个线性插值取代了,同样能得到每个 3D 位置点的信息,但这种静态场景的方法不能直接用于动态说话人的合成。
从静态扩展到动态主要的问题:
- 如何使用 grid-based NeRF 来同时高效的表达空间和语音信息?
- audio 特征一般被编码成 64 维向量,然后送入包含 3D 空间坐标的 MLP 中,然而,在基于网格的设置中引入额外的音频维度进行线性插值,将导致指数级的计算复杂性增长
- 当我们试图增加更多维度(比如音频)到NeRF模型时,可能会遇到计算复杂性指数级增长的问题。这是因为每新增一个维度,都会使得我们需要在空间中插值的数据点数量成倍增加。
- 例如,在二维空间中,如果你想在每个方向上有10个插值点,那么你总共需要100个数据点。但如果你想在三维空间做同样的事情,那么你就需要1000个数据点。
- 这就意味着随着我们添加更多的维度(如音频),所需进行插值和处理的数据量将迅速增大。这不仅会显著提高计算要求,并且可能超出现有硬件能力范围内处理。
- 此外,在高纬度空间进行插值也存在其他挑战:例如,“诅咒”的问题。“诅咒”指出,在高纬度空间中, 数据变得稀疏, 这使得利用统计方法或者机器学习方法变得非常困难。
- 有效的模拟躯干部分的运动也比较难,之前的方法或使用一个 3D 辐射场等,昂贵且复杂
本文如何做的:
- 本文提出了一个实时 audio-spatial 解耦的方法,能够对 audio-driven 的说话人合成进行高效训练和实时推理
- 作者利用了 grid-based NeRF 表达方式,将其优秀的静态场景建模能力引入了动态音频驱动的建模中
- 主要的贡献点在于,将高维度的音频驱动说话人的特征分解到了三个低维可学习的特征网格中。即为了建模动态头部,作者将 audio 和 spatial 的特征表达分解到了两个 grid,虽然作者保持静态 3D 空间坐标不变,但音频动态性被编码到了低维坐标。此外,作者还证明了可以被划分成两个单独的更低维度特征网格,而不是在一个更高纬度特征网格内查询音频和空间坐标, 这进一步降低了插值成本. 这种分解后的音频-空间编码使得用于对话头部建模的NeRF变得更加高效。
- 关于躯干部分,作者发现躯干运动涉及的拓扑变化较少,于是提出了一个轻量级的伪 3D 可变形模块来用 2D 特征网格建模躯干。
Grid-based NeRF:
- NeRF(Neural Radiance Fields)是一种用于3D重建的深度学习方法,它通过对三维空间中的点进行颜色和密度建模,从而可以从任何角度渲染出逼真的2D图像。
- Grid-based NeRF 是对传统 NeRF 方法的一种改进。在传统的 NeRF 中,神经网络会为每个 3D 空间中的点分配一个颜色和密度值。然而,这种方法在处理大型场景时可能会遇到内存限制问题。
- Grid-based NeRF 解决了这个问题。它通过将 3D 空间划分成一个网格,并仅在网格顶点上评估神经网络来优化内存使用情况。然后, 通过插值技术得到网格之间任意位置点的颜色和密度值. 这样就可以处理更大规模场景, 同时保持了较高精度.
总结一下主要区别:
- 内存使用:Grid-based NeRF优化了内存使用情况,使其能够处理更大规模场景。
- 计算效率:由于只需在网格顶点上评估神经网络,并利用插值技术获取其他位置信息, Grid-based NeRF提高了计算效率。
- 精确性:尽管采用了简化方式,在许多应用中, Grid-based NeRF还是能够保持较高精确性。
二、方法
2.1 问题定义
1、NeRF
NeRF 是使用 5D coordinates 来表达 3D 场景,也就是一个函数 F : x,d → σ , c F: \text{x,d} \to \sigma,\text{c} F:x,d→σ,c,假设一个 ray 从 o 出发,沿着方向 d 行进,则在沿着射线顺序采样的点 x i = o + t i d \text{x}_i=\text{o}+t_i \text{d} xi=o+tid 处来查询 F F F 来计算密度和颜色。
颜色:

2、Dynamic NeRF:
动态场景相比静态场景而言,会增加一些额外的条件,如当前时间 t。
之前的方法主要有两种解决方式:
- 1:使用 deformation-base 方法来在每个位置学习一个 deformation 和 time step,然后加到位置上去。但该类方法不适用于局部运动建模,如唇部运动。但可以用来建模肩膀。
- 2:使用 Modulation-based 方法,直接将时间 t 引入 NeRF,和位置、方向一起训练。这类方法可以用了建模头部。

3、Audio-driven Neural Radiance Talking Portrait
合成说话人的一般通用格式如下,一般使用 3-5 分钟有连续音频和固定机位拍摄的特定场景的视频
对每帧图片进行预处理:
- 对 head、neck、torso、background 进行语义分割
- 抽取 2D facial landmarks,包括眼部和唇部
- 使用 face-tracking 来估计 head pose 参数
对声音处理:
- 使用 Automatic Speech Recognition (ASR) model 来提取声音特征
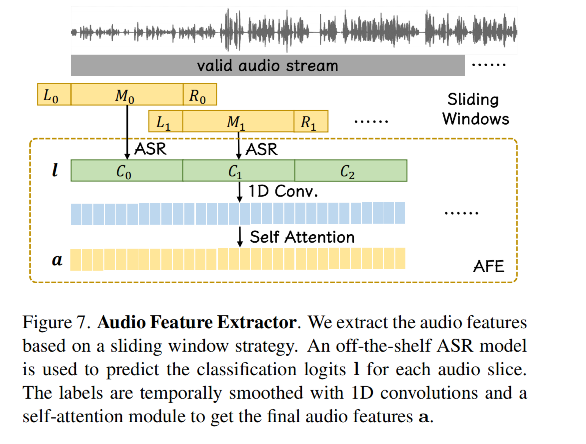
4、Grid-based NeRF
近期的 Grid-based NeRF 就是使用 3D feature grid encoder 将将静态场景的 3D 空间信息进行编码。
3D feature grid encoder:
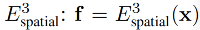
这种处理能加速训练和推理,为实时处理 3D 场景带来了可能
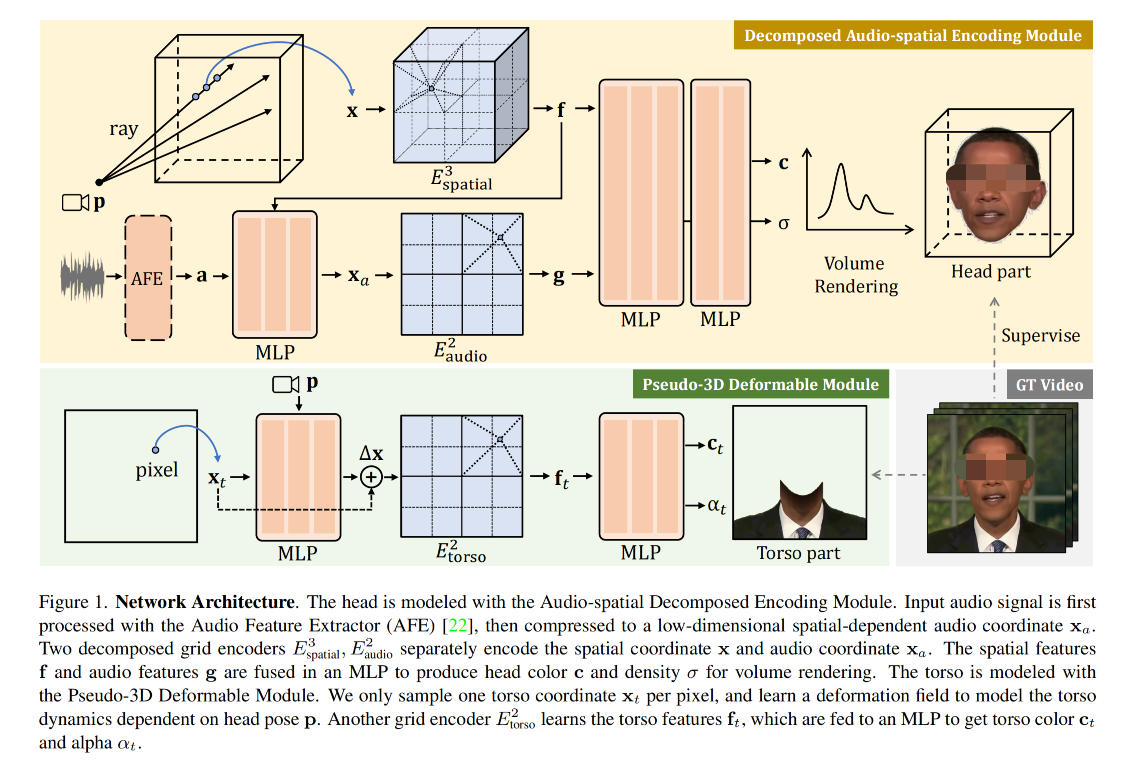
2.2 Decomposed audio-spatial encoding module
1、Audio-spatial Decomposition
之前的隐式 NeRF 方法 [22,32] 通常将 audio 信号会直接编码到高维特征,然后和空间高维特征 concat
但是这样对于 grid-based NeRF 来说,很昂贵,所以本文作者提出了解耦的方式
-
首先,将高维语音特征压缩到低维语音坐标 x a ∈ R D \text{x}_a \in R^D xa∈RD,且 D ∈ [ 1 , 2 , 3 ] D \in [1,2,3] D∈[1,2,3],很小。实现方式是使用 x a = MLP(a, f) \text{x}_a = \text{MLP(a, f)} xa=MLP(a, f)
-
然后,将 audio-spatial grid encoder 解耦成 两个 grid encoder 来分别对 audio 和 spatial 进行编码,然后 concat 起来即可:
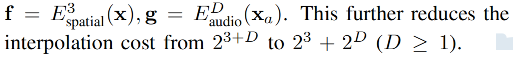
2、控制眨眼
眨眼对真实的数字人合成也很重要
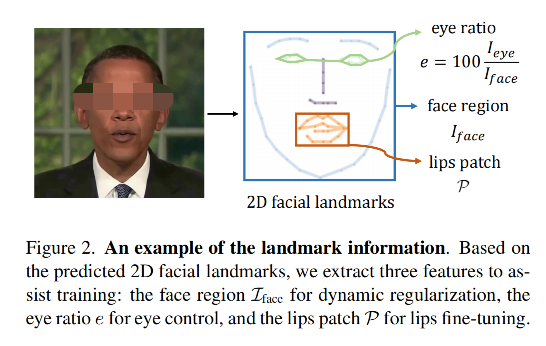
但是由于眨眼和声音没有很大的关系,很多之前的方法都忽略了眨眼,本文提出了一个方法来控制眨眼,如图 2。
- 首先,计算 eye area 在整个面部的占比,然后使用这个占比(通常为 0% ~ 0.5%)作为一维 eye feature e e e
- 然后,使用 eye feature 作为 NeRF 的 condition,来加入 NeRF 的训练
3、整体 head 表达
当得到了下面几个特征时,就可以使用一个 small MLP 来预测 density 和 color 了:
- spatial feature f f f
- audio feature g g g
- eye feature e e e
- latent appearance embedding i i i
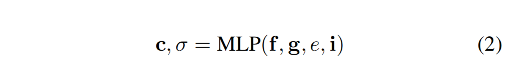
然后就可以使用公式 1 的方式来进行体渲染来得到每个位置的颜色,并合成 head

2.3 Pseudo-3D Deformable Module 用于控制 torso

2.4 训练细节
1、最大占用网络的修剪
在提高 NeRF效率的过程中,常见的一种技术是维护一个占用网格来修剪射线采样空间。这在静态场景下非常直接,因为占用网格也是静态的,我们可以使用一个三维网格来存储它。但对于动态场景,占用值还取决于动态条件,这就需要额外的维度。然而,更高维度的占用网格更难以存储和管理,并且会导致模型大小和训练时间大幅增加。
作者发现,在处理说话头部模型时(即人物头部根据音频进行相应动作的模型),由音频变化引起的占有率变化通常很小并且可以忽略不计。因此,他们提出了一种新方法:不是为每个音频条件都单独设置一个占有率网格,而是设定一个最大占有率网格来覆盖所有可能出现的音频条件。
具体实施过程中,在训练阶段从数据集中随机抽取各种音频条件,并记录下最大值作为最大占有率。这样做只需要使用三维网格就能存储所有可能出现情况下的最大值,并且能够成功地修剪不同音频条件下射线采样空间。
2、Loss 函数
颜色 loss 为 MSE loss:

使用 cross entropy loss 来优化 pixel transparency(像素透明度 α \alpha α)为 0 或 1,权重为 0.001
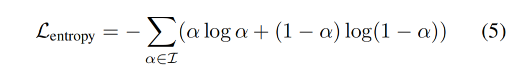
对于 audio 特征,理想情况下其应该只对面部区域起作用,在非面部区域的值应该为 0,所以作者使用 L1 正则化来约束,优化的目标是让其在非面部区域的值为 0(如 hair 和 ear),即不会闪烁,面部区域是使用 2D 关键点来定位的。
权重为 0.1
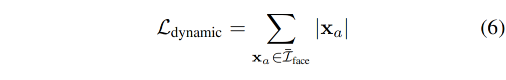
3、fine-tuning lips
高质量的唇部运动对于说话人的合成很重要,作者发现,只使用 pixel-wise MSE loss 很难对唇部进行很好的建模
所以,作者提出使用 patch-wise structural loss(如 LIPIS loss[63]),也就是基于面部关键点,在 lips 区域选择 patch,对唇部进行进一步 finetune,finetune 的整体 loss 如下。
权重为 0.01
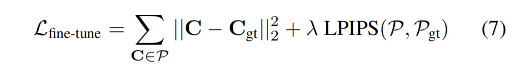
三、效果
3.1 实验设置
- head 训练 20000 step,finetune lip 5000 step,每个 step 有 256x256 rays
- 每个 ray 采样 16 个点
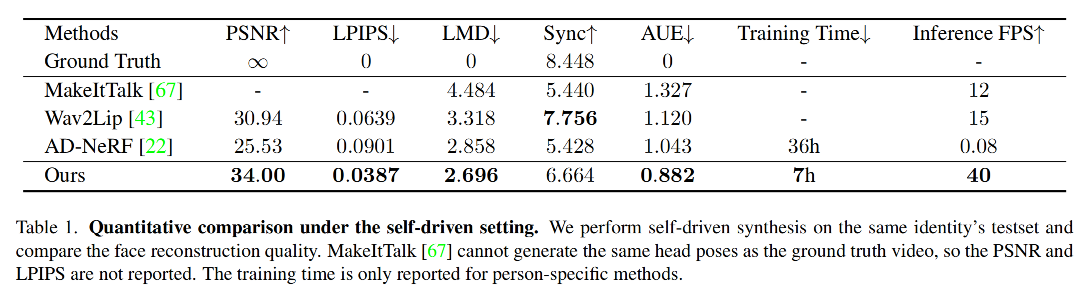
3.2 对比




这篇关于【数字人】5、RAD-NeRF | 通过解耦 audio-spatial 编码来实现基于 NeRF 的高效数字人合成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







