本文主要是介绍保障训练-20200916,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
4.58 Tomcat_JDK安装
4.59 安装zrlog
4.60 nginx代理tomcat
4.61 第二个java应用
一、Tomcat_JDK安装
Tomcat是Apache软件基金会(Apache Software Foundation)的Jakarta项目中的一个核心项目,由Apache、Sun和其他一些公司及个人共同开发而成。
java程序写的网站用tomcat+jdk来运行,tomcat是一个中间件,真正起作用的,解析java脚本的是jdk
jdk(java development kit)是整个java的核心,它包含了java运行环境和一堆java相关的工具以及java基础库
最主流的jdk为sun公司发布的jdk,除此之外,其实IBM公司也有发布JDK,CentOS上也可以用yum安装openjdk
我们已经学过了LAMP和LNMP架构;针对的开发语言是PHP;可以说PHP是一门开发Web程序非常流行的语言;早期的比较流行的是asp,是在windows平台上运行的一种编程语言;但是因为安全性不高;所以越来越多做网站的人用Php去开发网站,相对来说也是比较安全的
除了PHP外,还有一门语言叫java;java是一门非常庞大的开发语言;不仅仅是可以开发开网站;也可以开发大型的软件、工具、甚至是游戏都可以;tomcat实际上是一个中间件,用来运行Java语言写的网站;那我们Php写的代码,要用php去解析;java就要用tomcat加上JDK一起去解析
其实Tomcat只是一个中间件,真正起作用的就是咱们已经安装的jdk。没有Tomcat还不可以,他的作用就是监听8080;8005;8009端口。假如说,访问站点,需要一个webserver,而Tomcat就可以理解为webserver!
在官网找到二进制包,下载(如果该下载地址失效,请到https://github.com/aminglinux/resource/blob/master/README.md 下载新版本)

解压、并把解压包移到 /usr/local/tomcat下

开启服务与关闭服务

查看java有关端口
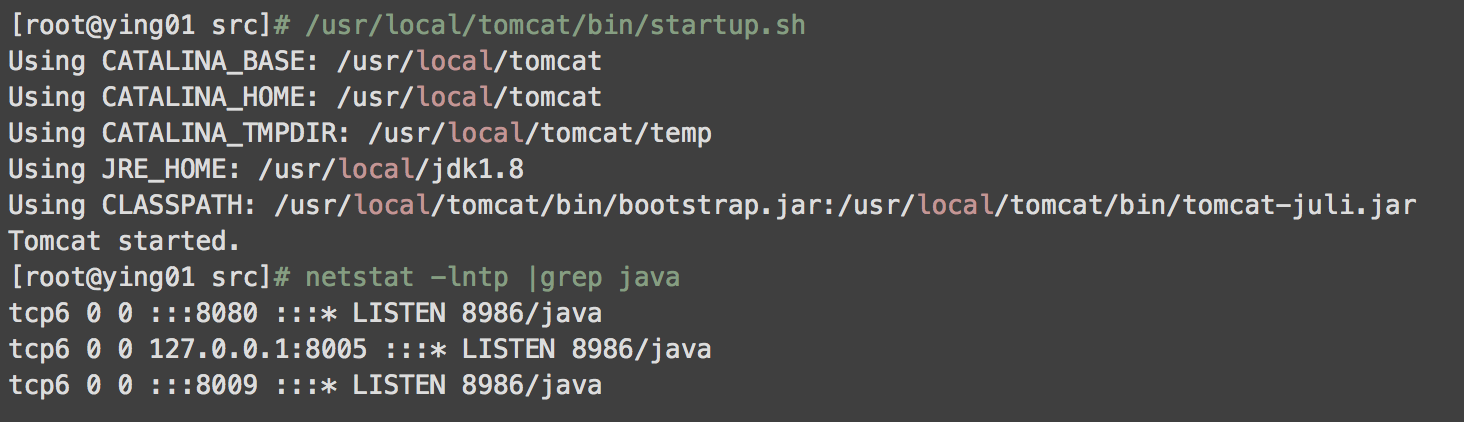
三个端口释义:
8080为提供web服务的端口
8005为管理端口;//显示调用会慢
8009端口为第三方服务调用的端口,比如httpd和Tomcat结合时会用到
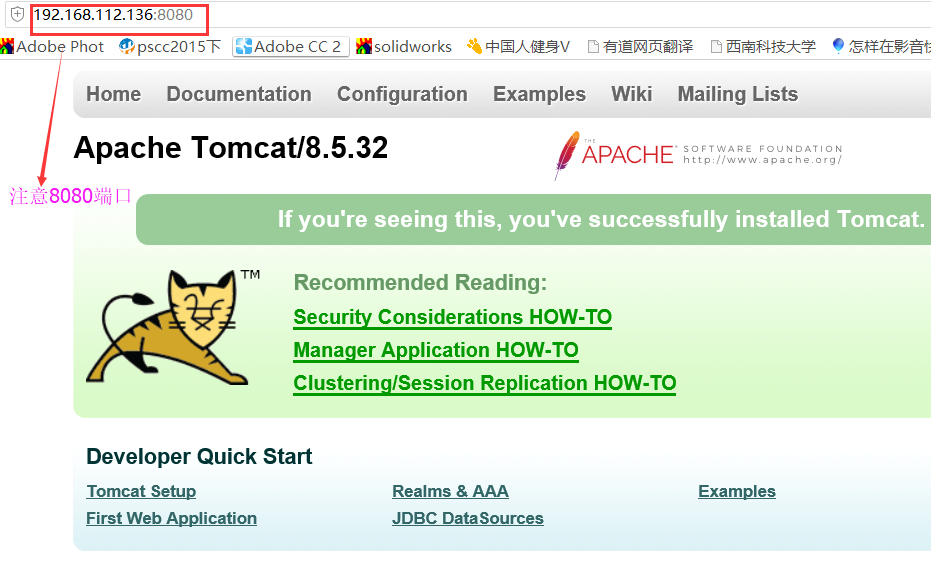
在关闭防火墙后,用浏览器访问其默认主页:192.168.112.136:8080
JDK下载地址https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
先在windows环境下,下载好jdk,传输到linux虚拟机root下
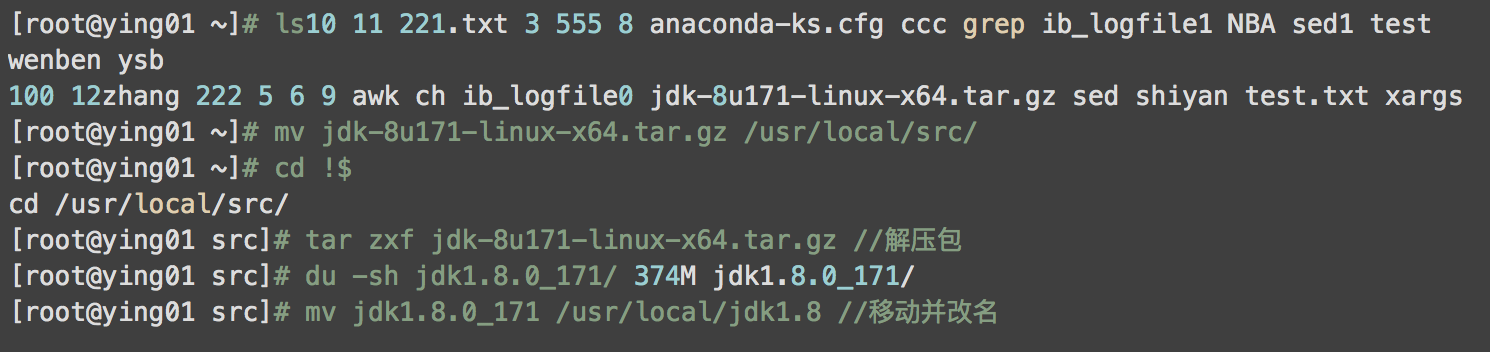
在/etc/profile增加以下代码

加载服务后,查看下载版本是否正确

二、安装zrlog
zrlog是一款开源的JAVA应用,博客系统
官网:https://www.zrlog.com
下载:
wget ‘http://dl.zrlog.com/release/zrlog-2.1.3-b5f0d63-release.war?attname=ROOT.war&ref=index’
mv zrlog-2.1.3-b5f0d63-release.war?attname=ROOT.war&ref=index zrlog-2.1.3.war
安装:
mv zrlog-2.1.3.war /usr/local/tomcat/webapps/
cd !$(/usr/local/tomcat/webapps/)
mv ROOT ROOT.bak
mv zrlog-2.1.3 ROOT
浏览器访问:
添加防火墙规则:firewall-cmd --add-port=8080/tcp --permanent
firewall-cmd --reload
http://ip:8080/ 开始安装
数据库操作:
mysql -uroot -paming-linux -e “create database zrlog”
mysql -uroot -paming-linux -e “grant all on zrlog.* to ‘zrlog’@‘127.0.0.1’ identified by ‘zrlog-pass’”
三、nginx代理tomcat
为什么要为Tomcat配置反向代理?
1.如果同一台机器有nginx又有Tomcat,则会产生端口冲突
2.需要把8080端口改成80端口
3.nginx对于静态的请求速度上要优先于Tomcat,Tomcat不擅长做高并发的静态文件请求处理
如何配置?
location /
{
proxy_pass http://ip;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
四、第二个java应用
方法一、
配置文件:
/usr/local/tomcat/conf/server.xml
重启:
/usr/local/tomcat/bin/shutdown.sh #先关闭
/usr/local/tomcat/bin/startup.sh #再开启
启动时,8005端口起来非常慢,这是因为Tomcat在启动时会调用系统的一个随机字符设备
方法二、
拷贝一个Tomcat目录,修改server.xml里面的三个端口(其中8009可以删掉,8080改成8081,8005改成8006)
小常识:
通过Java.security.SecureRandom生成随机数来实现,随机数算法使用的是“SHA1PRNG”,这个算法的提供者在底层依赖到操作系统提供的随机数据,在Linux上,与之相关的是/dev/random和/dev/urandom
/dev/random设备会返回小于熵池噪声总数的随机字节。/dev/random可生成高随机性的公钥或一次性密码本。若熵池空了,对/dev/random的读操作将会被阻塞,直到搜集到足够的环境噪声为止,而/dev/urandom则是一个非阻塞的发生器。它是/dev/random的一个副本,它会重复使用熵池中的数据以产生伪随机数据。这表示对/dev/urandom的读取操作不会产生阻塞,但其输出的熵可能小于/dev/random。
总之,8005端口启动慢就是因为JVM调用了系统的/dev/random设备生成随机数,而/dev/random生成随机数时被block了,自然就会导致8005端口启动慢,解决办法是不使用/dev/random,而是使用/dev/urandom,具体操作步骤:
vim $JAVA_HOME/jre/lib/security/java.security
//将securerandom.source=file:/dev/random改为securerandom.source=file:/dev/urandom
$JAVA_HOME在哪里?
如果是openjdk(yum安装的),在/usr/lib/jvm
如果是下载的二进制的包,就jdk的主目录(如/usr/local/jdk_1.8)
这篇关于保障训练-20200916的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







