本文主要是介绍LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略
导读:2023年09月20日,由上海人工智能实验室等团队发布了InternLM-20B的大模型。它在OpenCompass提出的5个能力维度上(语言、知识、理解、推理、学科)全面领先于同规模开源模型,InternLM-20B 在综合能力上全面领先于13B量级的开源模型,同时在推理评测集上接近甚至超越Llama-65B的性能。并且支持从单GPU到数千GPU(1024个)规模的扩展,千卡规模下训练吞吐超过180TFLOPS,平均单卡每秒处理的 token 数量超过3600。
更高质量和更高知识密度的数据集:相较于InternLM-7B,InternLM-20B使用的预训练数据经过了更高质量的清洗,并补充了高知识密度和用于强化理解和推理能力的训练数据。
基于 2.3T的Tokens+16k上下文+深度整合Flash-Attention+Apex+构建 Hybrid Zero 技术+LMDeploy一键部署:InternLM-20B 在超过 2.3T Tokens 包含高质量英文、中文和代码的数据上进行预训练, 支持16k语境长度,其中 Chat 版本还经过了 SFT 和 RLHF 训练。InternLM 深度整合了 Flash-Attention, Apex 等高性能模型算子,提高了训练效率。通过构建 Hybrid Zero 技术,实现计算和通信的高效重叠,大幅降低了训练过程中的跨节点通信流量。提供LMDeploy一键部署工具,支持产品化部署应用。
目录
相关文章
论文简介
LLMs之InternLM:InternLM-7B模型的简介、安装、使用方法之详细攻略
LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略
代码实战
InternLM-20B的简介
1、模型结果性能
2、训练性能
InternLM-20B的安装
0、下载模型
0.1、下载模型权重
0.2、下载项目代码
1、配置环境
T1、手动安装环境(安装复杂但环境控制高):
T2、基于提供的Docker镜像安装(安装简单但环境控制低):镜像配置及构造、镜像拉取、容器启动
2、数据处理:tokenizer.py文件
2.1、【预训练阶段】的数据集:读取不同输入文件格式(txt/json/jsonl)转为bin文件
2.2、【微调阶段】的数据集
3、预训练
3.1、训练配置,configs/7B_sft.py
数据配置
模型配置
并行配置
3.2、启动训练:train.py
LLMs之InternLM-20B:源码解读(train.py文件)—初始化配置→数据预处理(txt/json/jsonl等需转换为bin/meta文件再入模)→模型训练(批处理加载+内存分析+支持在特定步数进行验证评估+TensorBoard可视化监控+支持分布式训练【多机多卡训练同步更新】)+模型评估(ACC+PPL)+性能监控(日志记录+性能分析+内存监控等)
T1、若在 slurm 上启动分布式运行环境,多节点 16 卡的运行命令如下所示
T2、若在 torch 上启动分布式运行环境,单节点 8 卡的运行命令如下所示
3.3、运行结果
4、模型转换—转换为主流的Transformers 格式使用
InternLM-20B的使用方法
1、利用三种工具实现应用
T1、通过 Transformers 加载
T2、通过 ModelScope 加载
T3、通过前端网页对话
T4、利用 LMDeploy基于InternLM高性能部署
第一步,首先安装 LMDeploy:
第二步,启动服务执行对话
相关文章
论文简介
LLMs之InternLM:InternLM-7B模型的简介、安装、使用方法之详细攻略
LLMs之InternLM:InternLM/InternLM-7B模型的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略
LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
代码实战
更新中……
| 地址 | GitHub地址:GitHub - InternLM/InternLM: InternLM has open-sourced a 7 and 20 billion parameter base models and chat models tailored for practical scenarios and the training system. |
| 时间 | 2023年09月20日 |
| 作者 | 上海人工智能实验室+商汤科技+香港中文大学+复旦大学 |
InternLM-20B的简介
InternLM 是一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖。通过单一的代码库,它支持在拥有数千个 GPU 的大型集群上进行预训练,并在单个 GPU 上进行微调,同时实现了卓越的性能优化。在1024个 GPU 上训练时,InternLM 可以实现近90%的加速效率。基于InternLM训练框架,我们已经发布了两个开源的预训练模型:InternLM-7B 和 InternLM-20B。 InternLM-20B 在超过 2.3T Tokens 包含高质量英文、中文和代码的数据上进行预训练,其中 Chat 版本还经过了 SFT 和 RLHF 训练,使其能够更好、更安全地满足用户的需求。
InternLM 20B 在模型结构上选择了深结构,InternLM-20B 的层数设定为60层,超过常规7B和13B模型所使用的32层或者40层。在参数受限的情况下,提高层数有利于提高模型的综合能力。此外,相较于InternLM-7B,InternLM-20B使用的预训练数据经过了更高质量的清洗,并补充了高知识密度和用于强化理解和推理能力的训练数据。因此,它在理解能力、推理能力、数学能力、编程能力等考验语言模型技术水平的方面都得到了显著提升。总体而言,InternLM-20B具有以下的特点:
>> 优异的综合性能
>> 很强的工具调用功能
>> 支持16k语境长度(通过推理时外推)
>> 更好的价值对齐
1、模型结果性能
在OpenCompass提出的5个能力维度上,InternLM-20B都取得很好的效果(粗体为13B-33B这个量级范围内,各项最佳成绩)。总体而言,InternLM-20B 在综合能力上全面领先于13B量级的开源模型,同时在推理评测集上接近甚至超越Llama-65B的性能。
- 评估结果来自 OpenCompass 20230920。
- 由于 OpenCompass 的版本迭代,评估数据可能存在数值上的差异,所以请参考 OpenCompass 的最新评估结果。
| 能力维度 | Llama-13B | Llama2-13B | Baichuan2-13B | InternLM-20B | Llama-33B | Llama-65B | Llama2-70B |
|---|---|---|---|---|---|---|---|
| 语言 | 42.5 | 47 | 47.5 | 55 | 44.6 | 47.1 | 51.6 |
| 知识 | 58.2 | 58.3 | 48.9 | 60.1 | 64 | 66 | 67.7 |
| 理解 | 45.5 | 50.9 | 58.1 | 67.3 | 50.6 | 54.2 | 60.8 |
| 推理 | 42.7 | 43.6 | 44.2 | 54.9 | 46.4 | 49.8 | 55 |
| 学科 | 37.3 | 45.2 | 51.8 | 62.5 | 47.4 | 49.7 | 57.3 |
| 总平均 | 43.8 | 47.3 | 49.4 | 59.2 | 48.9 | 51.9 | 57.4 |
下表在一些有重要影响力的典型数据集上比较了主流开源模型的表现
| 评测集 | Llama-13B | Llama2-13B | Baichuan2-13B | InternLM-20B | Llama-33B | Llama-65B | Llama2-70B | |
|---|---|---|---|---|---|---|---|---|
| 学科 | MMLU | 47.73 | 54.99 | 59.55 | 62.05 | 58.73 | 63.71 | 69.75 |
| C-Eval (val) | 31.83 | 41.4 | 59.01 | 58.8 | 37.47 | 40.36 | 50.13 | |
| AGI-Eval | 22.03 | 30.93 | 37.37 | 44.58 | 33.53 | 33.92 | 40.02 | |
| 知识 | BoolQ | 78.75 | 82.42 | 67 | 87.46 | 84.43 | 86.61 | 87.74 |
| TriviaQA | 52.47 | 59.36 | 46.61 | 57.26 | 66.24 | 69.79 | 70.71 | |
| NaturalQuestions | 20.17 | 24.85 | 16.32 | 25.15 | 30.89 | 33.41 | 34.16 | |
| 理解 | CMRC | 9.26 | 31.59 | 29.85 | 68.78 | 14.17 | 34.73 | 43.74 |
| CSL | 55 | 58.75 | 63.12 | 65.62 | 57.5 | 59.38 | 60 | |
| RACE (middle) | 53.41 | 63.02 | 68.94 | 86.35 | 64.55 | 72.35 | 81.55 | |
| RACE (high) | 47.63 | 58.86 | 67.18 | 83.28 | 62.61 | 68.01 | 79.93 | |
| XSum | 20.37 | 23.37 | 25.23 | 35.54 | 20.55 | 19.91 | 25.38 | |
| 推理 | WinoGrande | 64.64 | 64.01 | 67.32 | 69.38 | 66.85 | 69.38 | 69.77 |
| BBH | 37.93 | 45.62 | 48.98 | 52.51 | 49.98 | 58.38 | 64.91 | |
| GSM8K | 20.32 | 29.57 | 52.62 | 52.62 | 42.3 | 54.44 | 63.31 | |
| PIQA | 79.71 | 79.76 | 78.07 | 80.25 | 81.34 | 82.15 | 82.54 | |
| 编程 | HumanEval | 14.02 | 18.9 | 17.07 | 25.61 | 17.68 | 18.9 | 26.22 |
| MBPP | 20.6 | 26.8 | 30.8 | 35.6 | 28.4 | 33.6 | 39.6 |
2、训练性能
InternLM 深度整合了 Flash-Attention, Apex 等高性能模型算子,提高了训练效率。通过构建 Hybrid Zero 技术,实现计算和通信的高效重叠,大幅降低了训练过程中的跨节点通信流量。InternLM 支持 7B 模型从 8 卡扩展到 1024 卡,千卡规模下加速效率可高达 90%,训练吞吐超过 180TFLOPS,平均单卡每秒处理的 token 数量超过3600。下表为 InternLM 在不同配置下的扩展性测试数据:
| GPU Number | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|---|---|---|---|
| TGS | 4078 | 3939 | 3919 | 3944 | 3928 | 3920 | 3835 | 3625 |
| TFLOPS | 193 | 191 | 188 | 188 | 187 | 185 | 186 | 184 |
TGS 代表平均每GPU每秒可以处理的 Token 数量。更多的性能测试数据可参考训练性能文档进一步了解。
InternLM-20B的安装
0、下载模型
0.1、下载模型权重
模型在三个平台上发布:Transformers、ModelScope 和 OpenXLab
| Model | Transformers | ModelScope | OpenXLab | 发布日期 |
|---|---|---|---|---|
| InternLM Chat 20B | 🤗internlm/internlm-chat-20b | 编辑 Shanghai_AI_Laboratory/internlm-chat-20b | 编辑 | 2023-09-20 |
| InternLM 20B | 🤗internlm/internlm-20b | 编辑 Shanghai_AI_Laboratory/internlm-20b | 编辑 | 2023-09-20 |
| InternLM Chat 7B v1.1 | 🤗internlm/internlm-chat-7b-v1.1 | 编辑 Shanghai_AI_Laboratory/internlm-chat-7b-v1_1 | 编辑 | 2023-08-22 |
| InternLM 7B | 🤗internlm/internlm-7b | 编辑 Shanghai_AI_Laboratory/internlm-7b | 编辑 | 2023-07-06 |
| InternLM Chat 7B | 🤗internlm/internlm-chat-7b | 编辑 Shanghai_AI_Laboratory/internlm-chat-7b | 编辑 | 2023-07-06 |
| InternLM Chat 7B 8k | 🤗internlm/internlm-chat-7b-8k | 编辑 Shanghai_AI_Laboratory/internlm-chat-7b-8k | 编辑 | 2023-07-06 |
0.2、下载项目代码
项目系统代码文件结构
├── configs # 配置模块,管理模型和训练相关参数
│ └── 7B_sft.py # 7B_sft.py 是系统 demo 的配置文件样例
├── internlm # 系统代码的主目录
│ ├── apis # 接口模块,包含一些关于推理等的接口函数
│ ├── core # 核心模块,管理用于训练和推理的 parallel context 和训练调度引擎
│ │ ├── communication # 通信模块,负责流水线并行调度中的p2p通信
│ │ ├── context # context 模块,主要负责初始化并行进程组,并管理 parallel context
│ │ │ ├── parallel_context.py
│ │ │ └── process_group_initializer.py
│ │ ├── scheduler # 调度模块,管理并行训练的调度器,包括非流水线并行调度器和流水线并行调度器
│ │ │ ├── no_pipeline_scheduler.py
│ │ │ └── pipeline_scheduler.py
│ │ ├── engine.py # 负责管理模型的训练和评估过程
│ │ └── trainer.py # 负责管理训练引擎和调度器
│ ├── data # 数据模块,负责管理数据集生成和处理
│ ├── initialize # 初始化模块,负责管理分布式环境启动和训练器初始化
│ ├── model # 模型模块,负责管理模型结构定义和实现
│ ├── solver # 负责管理 optimizer 和 lr_scheduler 等的实现
│ └── utils # 辅助模块,负责管理日志、存储、模型注册等
├── train.py # 模型训练的主函数入口文件
├── requirements # 系统运行的依赖包列表
├── third_party # 系统所依赖的第三方模块,包括 apex 和 flash-attention 等
├── tools # 一些脚本工具,用于原始数据集处理和转换,模型 checkpoint 转换等
└── version.txt # 系统版本号1、配置环境
T1、手动安装环境(安装复杂但环境控制高):
| 安装依赖包 | 首先,需要安装的依赖包及对应版本列表如下: Python == 3.10 GCC == 10.2.0 MPFR == 4.1.0 CUDA >= 11.7 Pytorch >= 1.13.1 Transformers >= 4.28.0 Flash-Attention >= v1.0.5 Apex == 23.05 Ampere或者Hopper架构的GPU (例如H100, A100) Linux OS 以上依赖包安装完成后,需要更新配置系统环境变量: export CUDA_PATH={path_of_cuda_11.7} export GCC_HOME={path_of_gcc_10.2.0} export MPFR_HOME={path_of_mpfr_4.1.0} export LD_LIBRARY_PATH=${GCC_HOME}/lib64:${MPFR_HOME}/lib:${CUDA_PATH}/lib64:$LD_LIBRARY_PATH export PATH=${GCC_HOME}/bin:${CUDA_PATH}/bin:$PATH export CC=${GCC_HOME}/bin/gcc export CXX=${GCC_HOME}/bin/c++ |
| 环境安装 | 下载项目代码、conda启动虚拟环境、安装flash-attention和Apex 将项目internlm及其依赖子模块,从 github 仓库中 clone 下来,命令如下: git clone git@github.com:InternLM/InternLM.git --recurse-submodules 推荐使用 conda 构建一个 Python-3.10 的虚拟环境, 并基于requirements/文件安装项目所需的依赖包: conda create --name internlm-env python=3.10 -y conda activate internlm-env cd internlm pip install -r requirements/torch.txt pip install -r requirements/runtime.txt 安装 flash-attention (version v1.0.5): cd ./third_party/flash-attention python setup.py install cd ./csrc cd fused_dense_lib && pip install -v . cd ../xentropy && pip install -v . cd ../rotary && pip install -v . cd ../layer_norm && pip install -v . cd ../../../../ 安装 Apex (version 23.05): cd ./third_party/apex pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./ cd ../../ |
T2、基于提供的Docker镜像安装(安装简单但环境控制低):镜像配置及构造、镜像拉取、容器启动
| 镜像配置及构造 | 用户可以使用提供的 dockerfile 结合 docker.Makefile 来构建自己的镜像,或者也可以从 https://hub.docker.com/r/internlm/internlm 获取安装了 InternLM 运行环境的镜像。 (1)、镜像配置及构造 dockerfile 的配置以及构造均通过 docker.Makefile 文件实现,在 InternLM 根目录下执行如下命令即可 build 镜像: make -f docker.Makefile BASE_OS=centos7 在 docker.Makefile 中可自定义基础镜像,环境版本等内容,对应参数可直接通过命令行传递。对于 BASE_OS 分别支持 ubuntu20.04 和 centos7。 |
| 镜像拉取 | (2)、镜像拉取 基于 ubuntu 和 centos 的标准镜像已经 build 完成也可直接拉取使用: # ubuntu20.04 docker pull internlm/internlm:torch1.13.1-cuda11.7.1-flashatten1.0.5-ubuntu20.04 # centos7 docker pull internlm/internlm:torch1.13.1-cuda11.7.1-flashatten1.0.5-centos7 |
| 容器启动 | (3)、容器启动 对于使用 dockerfile 构建或拉取的本地标准镜像,使用如下命令启动并进入容器: docker run --gpus all -it -m 500g --cap-add=SYS_PTRACE --cap-add=IPC_LOCK --shm-size 20g --network=host --name myinternlm internlm/internlm:torch1.13.1-cuda11.7.1-flashatten1.0.5-centos7 bash 容器内默认目录即 /InternLM,根据使用文档即可启动训练。 |
2、数据处理:tokenizer.py文件
2.1、【预训练阶段】的数据集:读取不同输入文件格式(txt/json/jsonl)转为bin文件
| 简介 | InternLM训练任务的数据集包括一系列的bin和meta文件。 |
| 使用tokenizer从原始文本文件生成训练用数据集。通过在tools/tokenizer.py中指定模型参数路径的方式来导入tokenizer模型。目前提供V7_sft.model来生成tokens。若想使用不同的模型,可直接修改tokernizer.py中的模型参数路径。 | |
| 使用方法 | 可以运行以下命令生成原始数据对应的bin和meta文件,其中参数text_input_path表示原始文本数据路径,目前支持txt、json和jsonl三种输入格式,bin_output_path表示生成的bin文件的保存路径。 $ python tools/tokenizer.py --text_input_path your_input_text_path --bin_output_path your_output_bin_path |
| 案例 | 下面是一个数据处理的例子: 给定一个包含原始数据集的文件raw_data.txt,原始数据集如下所示: 感恩生活中的每一个细节,才能真正体会到幸福的滋味。 梦想是人生的动力源泉,努力追逐,才能实现自己的目标。 学会宽容和理解,才能建立真正和谐的人际关系。 可以通过运行以下命令来生成bin和meta文件: $ python tools/tokenizer.py --text_input_path raw_data.txt --bin_output_path cn/output.bin |
| 文件简介 | 生成的bin文件简介 需要注意的是,生成的bin文件需要保存在cn【中文数据集】或者en【英文数据集】或者code【代码数据集】或者ja【日语数据集】或者ar【阿拉伯语数据集】或者kaoshi【考试数据集】这六个目录下,以区分数据集的类型。 生成的bin文件的格式如下: {"tokens": [73075, 75302, 69522, 69022, 98899, 67713, 68015, 81269, 74637, 75445, 99157]} {"tokens": [69469, 60355, 73026, 68524, 60846, 61844, 98899, 67775, 79241, 98899, 67713, 67800, 67453, 67838, 99157]} {"tokens": [68057, 79017, 60378, 68014, 98899, 67713, 67990, 68015, 70381, 67428, 61003, 67622, 99157]} bin文件中的每一行均对应原始数据集中的每一个句子,表示每个句子的token(下文将用sequence指定)。 |
| 生成的meta文件简介 | 生成的meta文件简介 生成的meta文件的格式如下: (0, 11), (90, 15), (208, 13) 在meta文件中,每个元组对应着bin文件中每一个sequence的元信息。其中,元组的 第一个元素表示每个sequence在所有sequence中的starting index, 第二个元素表示每个sequence中有多少个tokens。 例如,对于第一个sequence,starting index为 0,有 11 个tokens;对于第二个sequence,由于第一个sequence转换为string后的长度为89,因此它的starting index为 90,有 15 个tokens。 json和jsonl类型的文件的bin和meta文件格式和txt一致,此处不再赘叙。 |
2.2、【微调阶段】的数据集
| 简介 | 微调任务的数据集格式与预训练任务保持一致,生成的数据格式为一系列的bin和meta文件。以下以 Alpaca 数据集为例,介绍微调的数据准备流程。 |
| 实现步骤 | 第一步,下载Alpaca 数据集:https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json 第二步,对 Alpaca 数据进行 tokenize,使用以下命令 python tools/alpaca_tokenizer.py /path/to/alpaca_dataset /path/to/output_dataset /path/to/tokenizer --split_ratio 0.1 建议用户参考 alpaca_tokenizer.py 编写新的脚本对自己的数据集进行tokenize |
3、预训练
3.1、训练配置,configs/7B_sft.py
以 7B Demo 的配置文件configs/7B_sft.py为例:接下来将详细介绍启动一个模型训练所需要进行的数据、模型、并行和监控等相关的配置。
JOB_NAME = "7b_train"
DO_ALERT = FalseSEQ_LEN = 2048
HIDDEN_SIZE = 4096
NUM_ATTENTION_HEAD = 32
MLP_RATIO = 8 / 3
NUM_LAYER = 32
VOCAB_SIZE = 103168MODEL_ONLY_FOLDER = "local:llm_ckpts/xxxx"
# Ckpt folder format:
# fs: 'local:/mnt/nfs/XXX'
SAVE_CKPT_FOLDER = "local:llm_ckpts"
LOAD_CKPT_FOLDER = "local:llm_ckpts/49"# boto3 Ckpt folder format:
# import os
# BOTO3_IP = os.environ["BOTO3_IP"] # boto3 bucket endpoint
# SAVE_CKPT_FOLDER = f"boto3:s3://model_weights.{BOTO3_IP}/internlm"
# LOAD_CKPT_FOLDER = f"boto3:s3://model_weights.{BOTO3_IP}/internlm/snapshot/1/"
CHECKPOINT_EVERY = 50
ckpt = dict(enable_save_ckpt=False, # enable ckpt save.save_ckpt_folder=SAVE_CKPT_FOLDER, # Path to save training ckpt.# load_ckpt_folder= dict(path=MODEL_ONLY_FOLDER, content=["model"], ckpt_type="normal"),load_ckpt_folder="local:llm_ckpts/",# 'load_ckpt_info' setting guide:# 1. the 'path' indicate ckpt path,# 2. the 'content‘ means what states will be loaded, support: "model", "sampler", "optimizer", "scheduler", "all"# 3. the ’ckpt_type‘ means the type of checkpoint to be loaded, now only 'normal' type is supported.load_ckpt_info=dict(path=MODEL_ONLY_FOLDER, content=("model",), ckpt_type="internlm"),checkpoint_every=CHECKPOINT_EVERY,async_upload=True, # async ckpt upload. (only work for boto3 ckpt)async_upload_tmp_folder="/dev/shm/internlm_tmp_ckpt/", # path for temporarily files during asynchronous upload.oss_snapshot_freq=int(CHECKPOINT_EVERY / 2), # snapshot ckpt save frequency.
)TRAIN_FOLDER = "/path/to/dataset"
VALID_FOLDER = "/path/to/dataset"
data = dict(seq_len=SEQ_LEN,# micro_num means the number of micro_batch contained in one gradient updatemicro_num=4,# packed_length = micro_bsz * SEQ_LENmicro_bsz=2,# defaults to the value of micro_numvalid_micro_num=4,# defaults to 0, means disable evaluatevalid_every=50,pack_sample_into_one=False,total_steps=50000,skip_batches="",rampup_batch_size="",# Datasets with less than 50 rows will be discardedmin_length=50,# train_folder=TRAIN_FOLDER,# valid_folder=VALID_FOLDER,empty_cache_and_diag_interval=10,diag_outlier_ratio=1.1,
)grad_scaler = dict(fp16=dict(# the initial loss scale, defaults to 2**16initial_scale=2**16,# the minimum loss scale, defaults to Nonemin_scale=1,# the number of steps to increase loss scale when no overflow occursgrowth_interval=1000,),# the multiplication factor for increasing loss scale, defaults to 2growth_factor=2,# the multiplication factor for decreasing loss scale, defaults to 0.5backoff_factor=0.5,# the maximum loss scale, defaults to Nonemax_scale=2**24,# the number of overflows before decreasing loss scale, defaults to 2hysteresis=2,
)hybrid_zero_optimizer = dict(# Enable low_level_optimzer overlap_communicationoverlap_sync_grad=True,overlap_sync_param=True,# bucket size for nccl communication paramsreduce_bucket_size=512 * 1024 * 1024,# grad clippingclip_grad_norm=1.0,
)loss = dict(label_smoothing=0,
)adam = dict(lr=1e-4,adam_beta1=0.9,adam_beta2=0.95,adam_beta2_c=0,adam_eps=1e-8,weight_decay=0.01,
)lr_scheduler = dict(total_steps=data["total_steps"],init_steps=0, # optimizer_warmup_stepwarmup_ratio=0.01,eta_min=1e-5,last_epoch=-1,
)beta2_scheduler = dict(init_beta2=adam["adam_beta2"],c=adam["adam_beta2_c"],cur_iter=-1,
)model = dict(checkpoint=False, # The proportion of layers for activation aheckpointing, the optional value are True/False/[0-1]num_attention_heads=NUM_ATTENTION_HEAD,embed_split_hidden=True,vocab_size=VOCAB_SIZE,embed_grad_scale=1,parallel_output=True,hidden_size=HIDDEN_SIZE,num_layers=NUM_LAYER,mlp_ratio=MLP_RATIO,apply_post_layer_norm=False,dtype="torch.float16", # Support: "torch.float16", "torch.half", "torch.bfloat16", "torch.float32", "torch.tf32"norm_type="rmsnorm",layer_norm_epsilon=1e-5,use_flash_attn=True,num_chunks=1, # if num_chunks > 1, interleaved pipeline scheduler is used.
)
"""
zero1 parallel:1. if zero1 <= 0, The size of the zero process group is equal to the size of the dp process group,so parameters will be divided within the range of dp.2. if zero1 == 1, zero is not used, and all dp groups retain the full amount of model parameters.3. zero1 > 1 and zero1 <= dp world size, the world size of zero is a subset of dp world size.For smaller models, it is usually a better choice to split the parameters within nodes with a setting <= 8.
pipeline parallel (dict):1. size: int, the size of pipeline parallel.2. interleaved_overlap: bool, enable/disable communication overlap when using interleaved pipeline scheduler.
tensor parallel: tensor parallel size, usually the number of GPUs per node.
"""
parallel = dict(zero1=8,pipeline=dict(size=1, interleaved_overlap=True),sequence_parallel=False,
)cudnn_deterministic = False
cudnn_benchmark = Falsemonitor = dict(# feishu alert configsalert=dict(enable_feishu_alert=DO_ALERT,feishu_alert_address=None, # feishu webhook to send alert messagelight_monitor_address=None, # light_monitor address to send heartbeat),
)数据配置
| 数据相关的关键参数配置及释义如下所示 | |
| 目前支持传入数据集文件路径train_folder,且要求文件格式如下: - folder - code train_000.bin train_000.bin.meta 数据集的详细内容可参考数据准备模块相关的介绍。 |
TRAIN_FOLDER = "/path/to/dataset"
SEQ_LEN = 2048
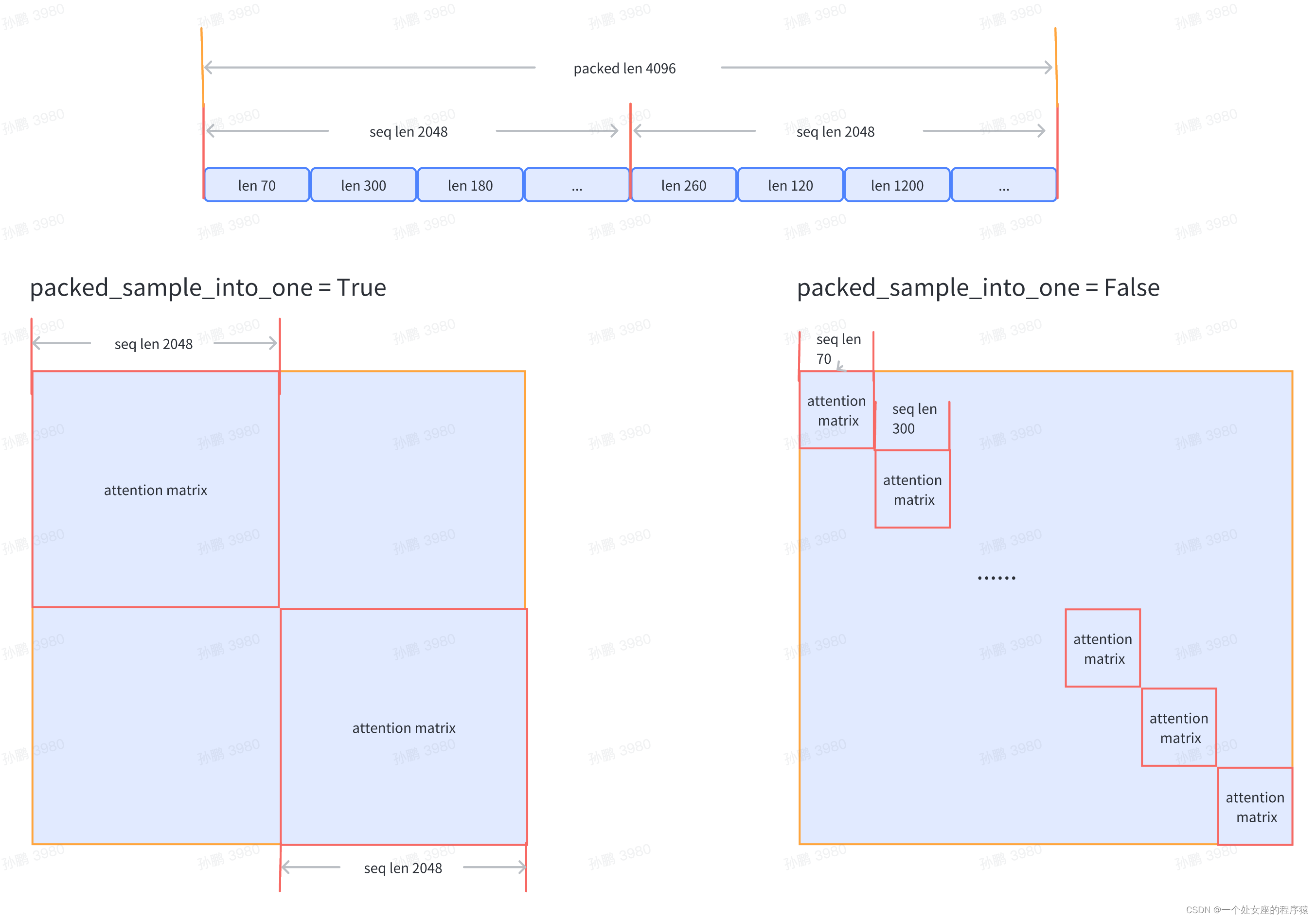
data = dict(seq_len=SEQ_LEN, # 数据样本长度,默认值为 2048micro_num=1, # micro_num 是指在一次模型参数更新中会处理的 micro_batch 的数目,默认值为 1micro_bsz=1, # packed_length = micro_bsz * SEQ_LEN,为一次处理的 micro_batch 的数据大小,默认值为 1total_steps=50000, # 总的所需执行的 step 的数目,默认值为 50000min_length=50, # 若数据集文件中,数据行数少于50,将会被废弃train_folder=TRAIN_FOLDER, # 数据集文件路径,默认值为 None;若 train_folder 为空,则以自动生成的随机数据集进行训练测试pack_sample_into_one=False, # 数据整理的逻辑,决定是按照 seq_len 维度或者是 sequence 的真实长度来进行attention计算
)
模型配置
| 加载模型 checkpoint | 如果在启动训练时要加载模型 checkpoint,可进行如下相关配置: 注意:路径若以 local: 为前缀,则存储在本地文件系统;若以 boto3: 为前缀,则存储在远程 oss 上 |
| 关键参数 | 模型相关关键参数配置如下所示: 注意:用户可自定义模型类型名和模型结构,并配置相对应的模型参数。通过utils/registry.py下的MODEL_INITIALIZER对象进行模型初始化函数接口注册,在训练主函数train.py中初始化模型时,可通过model_type配置获取指定的模型初始化接口函数。 如果基于 InternLM 7B继续训练,可以参考 ModelZoo 中 OpenXLab 链接下载权重 |
如果在启动训练时要加载模型 checkpoint,可进行如下相关配置:
SAVE_CKPT_FOLDER = "local:/path/to/save/ckpt"
LOAD_CKPT_FOLDER = "local:/path/to/load/resume/ckpt"
ckpt = dict(save_ckpt_folder=SAVE_CKPT_FOLDER, # 存储模型和优化器 checkpoint 的路径checkpoint_every=float("inf"), # 每多少个 step 存储一次 checkpoint,默认值为 inf# 断点续训时,加载模型和优化器等权重的路径,将从指定的 step 恢复训练# content 表示哪些状态会被加载,支持: "model", "sampler", "optimizer", "scheduler", "all"# ckpt_type 表示加载的模型类型,目前支持: "internlm"load_ckpt_info=dict(path=MODEL_ONLY_FOLDER, content=("model",), ckpt_type="internlm"),
)模型相关关键参数配置如下所示:
model_type = "INTERNLM" # 模型类型,默认值为 "INTERNLM",对应模型结构初始化接口函数
NUM_ATTENTION_HEAD = 32
VOCAB_SIZE = 103168
HIDDEN_SIZE = 4096
NUM_LAYER = 32
MLP_RATIO = 8 / 3
model = dict(checkpoint=False, # 进行重计算的模型层数比例,可选值为 True/False/[0-1]num_attention_heads=NUM_ATTENTION_HEAD,embed_split_hidden=True,vocab_size=VOCAB_SIZE,embed_grad_scale=1,parallel_output=True,hidden_size=HIDDEN_SIZE,num_layers=NUM_LAYER,mlp_ratio=MLP_RATIO,apply_post_layer_norm=False,dtype="torch.bfloat16",norm_type="rmsnorm",layer_norm_epsilon=1e-5,
)注意:用户可自定义模型类型名和模型结构,并配置相对应的模型参数。通过utils/registry.py下的MODEL_INITIALIZER对象进行模型初始化函数接口注册,在训练主函数train.py中初始化模型时,可通过model_type配置获取指定的模型初始化接口函数。
如果基于 InternLM 7B继续训练,可以参考 ModelZoo 中 OpenXLab 链接下载权重
并行配置
训练并行配置样例如下:
| 参数 | zero1:zero 并行策略,分如下三种情况,默认值为 -1 >> 当zero1 <= 0,则 zero1 进程组的大小等于数据并行进程组的大小,因此优化器状态参数将在数据并行范围内分配 >> 当zero1 == 1,则不使用 zero1 ,所有数据并行组保留完整的优化器状态参数 >> 当zero1 > 1且zero1 <= data_parallel_world_size,则 zero1 进程组是数据并行进程组的子集 tensor:张量并行大小,通常是每个节点的 GPU 数量,默认值为 1 pipeline:流水线并行策略 >> size:流水线并行大小,默认值为 1 >> interleaved_overlap:bool 类型,交错式调度时,开启或关闭通信优化,默认值为关闭 sequence_parallel:是否开启序列化并行,默认值为 False |
| 注意 | 注意:数据并行大小 = 总的 GPU 数目 / 流水线并行大小 / 张量并行大小 |
parallel = dict(zero1=8,tensor=1,pipeline=dict(size=1, interleaved_overlap=True),sequence_parallel=False,
)3.2、启动训练:train.py
完成了以上数据集准备和相关训练配置后,可启动 Demo 训练。接下来分别以 slurm 和 torch 环境为例,介绍训练启动方式。
LLMs之InternLM-20B:源码解读(train.py文件)—初始化配置→数据预处理(txt/json/jsonl等需转换为bin/meta文件再入模)→模型训练(批处理加载+内存分析+支持在特定步数进行验证评估+TensorBoard可视化监控+支持分布式训练【多机多卡训练同步更新】)+模型评估(ACC+PPL)+性能监控(日志记录+性能分析+内存监控等)
LLMs之InternLM-20B:源码解读(train.py文件)—初始化配置→数据预处理(txt/json/jsonl等需转换为bin/meta文件再入模)→模型训练(批处理加载+内存分析+支持在_一个处女座的程序猿的博客-CSDN博客
T1、若在 slurm 上启动分布式运行环境,多节点 16 卡的运行命令如下所示
$ srun -p internllm -N 2 -n 16 --ntasks-per-node=8 --gpus-per-task=1 python train.py --config ./configs/7B_sft.pyT2、若在 torch 上启动分布式运行环境,单节点 8 卡的运行命令如下所示
$ torchrun --nnodes=1 --nproc_per_node=8 train.py --config ./configs/7B_sft.py --launcher "torch"3.3、运行结果
以 slurm 上单机 8 卡的 Demo 训练配置为例,训练结果日志展示如下:
2023-07-07 12:26:58,293 INFO launch.py:228 in launch -- Distributed environment is initialized, data parallel size: 8, pipeline parallel size: 1, tensor parallel size: 1
2023-07-07 12:26:58,293 INFO parallel_context.py:535 in set_seed -- initialized seed on rank 2, numpy: 1024, python random: 1024, ParallelMode.DATA: 1024, ParallelMode.TENSOR: 1024,the default parallel seed is ParallelMode.DATA.
2023-07-07 12:26:58,295 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=0===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=5===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=1===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=6===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=7===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=2===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=4===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=3===========
2023-07-07 12:28:27,826 INFO hybrid_zero_optim.py:295 in _partition_param_list -- Number of elements on ranks: [907415552, 907411456, 910163968, 910163968, 921698304, 921698304, 921698304, 921698304], rank:0
2023-07-07 12:28:57,802 INFO train.py:323 in record_current_batch_training_metrics -- tflops=63.27010355651958,step=0,loss=11.634403228759766,tgs (tokens/gpu/second)=1424.64,lr=4.0000000000000003e-07,loss_scale=65536.0,grad_norm=63.672620777841004,micro_num=4,num_consumed_tokens=131072,inf_nan_skip_batches=0,num_samples_in_batch=19,largest_length=2048,largest_batch=5,smallest_batch=4,adam_beta2=0.95,fwd_bwd_time=6.48
2023-07-07 12:29:01,636 INFO train.py:323 in record_current_batch_training_metrics -- tflops=189.83371103277346,step=1,loss=11.613704681396484,tgs (tokens/gpu/second)=4274.45,lr=6.000000000000001e-07,loss_scale=65536.0,grad_norm=65.150786641452,micro_num=4,num_consumed_tokens=262144,inf_nan_skip_batches=0,num_samples_in_batch=16,largest_length=2048,largest_batch=5,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.67
2023-07-07 12:29:05,451 INFO train.py:323 in record_current_batch_training_metrics -- tflops=190.99928472960033,step=2,loss=11.490386962890625,tgs (tokens/gpu/second)=4300.69,lr=8.000000000000001e-07,loss_scale=65536.0,grad_norm=61.57798028719357,micro_num=4,num_consumed_tokens=393216,inf_nan_skip_batches=0,num_samples_in_batch=14,largest_length=2048,largest_batch=4,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.66
2023-07-07 12:29:09,307 INFO train.py:323 in record_current_batch_training_metrics -- tflops=188.8613541410694,step=3,loss=11.099515914916992,tgs (tokens/gpu/second)=4252.55,lr=1.0000000000000002e-06,loss_scale=65536.0,grad_norm=63.5478796484391,micro_num=4,num_consumed_tokens=524288,inf_nan_skip_batches=0,num_samples_in_batch=16,largest_length=2048,largest_batch=5,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.7
2023-07-07 12:29:13,147 INFO train.py:323 in record_current_batch_training_metrics -- tflops=189.65918563194305,step=4,loss=10.149517059326172,tgs (tokens/gpu/second)=4270.52,lr=1.2000000000000002e-06,loss_scale=65536.0,grad_norm=51.582841631508145,micro_num=4,num_consumed_tokens=655360,inf_nan_skip_batches=0,num_samples_in_batch=19,largest_length=2048,largest_batch=6,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.68
2023-07-07 12:29:16,994 INFO train.py:323 in record_current_batch_training_metrics -- tflops=189.3109313713174,step=5,loss=9.822169303894043,tgs (tokens/gpu/second)=4262.67,lr=1.4000000000000001e-06,loss_scale=65536.0,grad_norm=47.10386835560855,micro_num=4,num_consumed_tokens=786432,inf_nan_skip_batches=0,num_samples_in_batch=17,largest_length=2048,largest_batch=6,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.694、模型转换—转换为主流的Transformers 格式使用
通过 InternLM 进行训练的模型可以很轻松地转换为 HuggingFace Transformers 格式,方便与社区各种开源项目无缝对接。借助 tools/transformers/convert2hf.py 可以将训练保存的权重一键转换为 transformers 格式
python tools/transformers/convert2hf.py --src_folder origin_ckpt/ --tgt_folder hf_ckpt/ --tokenizer ./tools/V7_sft.model转换之后可以通过以下的代码加载为 transformers
>>> from transformers import AutoTokenizer, AutoModel
>>> model = AutoModel.from_pretrained("hf_ckpt/", trust_remote_code=True).cuda()InternLM-20B的使用方法
1、利用三种工具实现应用
T1、通过 Transformers 加载
通过以下的代码从 Transformers 加载 InternLM 模型 (可修改模型名称替换不同的模型)
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("internlm/internlm-chat-7b", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("internlm/internlm-chat-7b", trust_remote_code=True).cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好!有什么我可以帮助你的吗?
>>> response, history = model.chat(tokenizer, "请提供三个管理时间的建议。", history=history)
>>> print(response)
当然可以!以下是三个管理时间的建议:
1. 制定计划:制定一个详细的计划,包括每天要完成的任务和活动。这将有助于您更好地组织时间,并确保您能够按时完成任务。
2. 优先级:将任务按照优先级排序,先完成最重要的任务。这将确保您能够在最短的时间内完成最重要的任务,从而节省时间。
3. 集中注意力:避免分心,集中注意力完成任务。关闭社交媒体和电子邮件通知,专注于任务,这将帮助您更快地完成任务,并减少错误的可能性。T2、通过 ModelScope 加载
通过以下的代码从 ModelScope 加载 InternLM 模型 (可修改模型名称替换不同的模型)
from modelscope import snapshot_download, AutoTokenizer, AutoModelForCausalLM
import torch
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b-v1_1', revision='v1.0.0')
tokenizer = AutoTokenizer.from_pretrained(model_dir, device_map="auto", trust_remote_code=True,torch_dtype=torch.float16)
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map="auto", trust_remote_code=True,torch_dtype=torch.float16)
model = model.eval()
response, history = model.chat(tokenizer, "hello", history=[])
print(response)
response, history = model.chat(tokenizer, "please provide three suggestions about time management", history=history)
print(response)T3、通过前端网页对话
可以通过以下代码启动一个前端的界面来与 InternLM Chat 7B 模型进行交互
pip install streamlit==1.24.0
pip install transformers==4.30.2
streamlit run web_demo.pyT4、利用 LMDeploy基于InternLM高性能部署
我们使用 LMDeploy 完成 InternLM 的一键部署。
第一步,首先安装 LMDeploy:
python3 -m pip install lmdeploy快速的部署命令如下:
python3 -m lmdeploy.serve.turbomind.deploy InternLM-7B /path/to/internlm-7b/model hf第二步,启动服务执行对话
在导出模型后,你可以直接通过如下命令启动服务一个服务并和部署后的模型对话。LMDeploy 支持了 InternLM 部署的完整流程,请参考 部署教程 了解 InternLM 的更多部署细节。
python3 -m lmdeploy.serve.client {server_ip_addresss}:33337这篇关于LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









