本文主要是介绍PaddleSlim对BERT-base模型进行压缩/OFA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
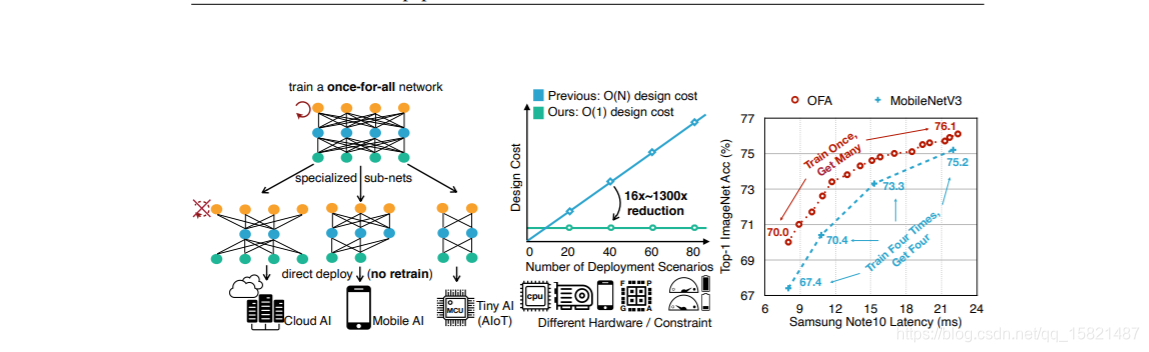
针对不同的应用,能快速训练选择出来
BERT-base模型是一个迁移能力很强的通用语义表示模型,但是模型中也有一些参数冗余。本教程将介绍如何使用PaddleSlim对BERT-base模型进行压缩。
压缩原理
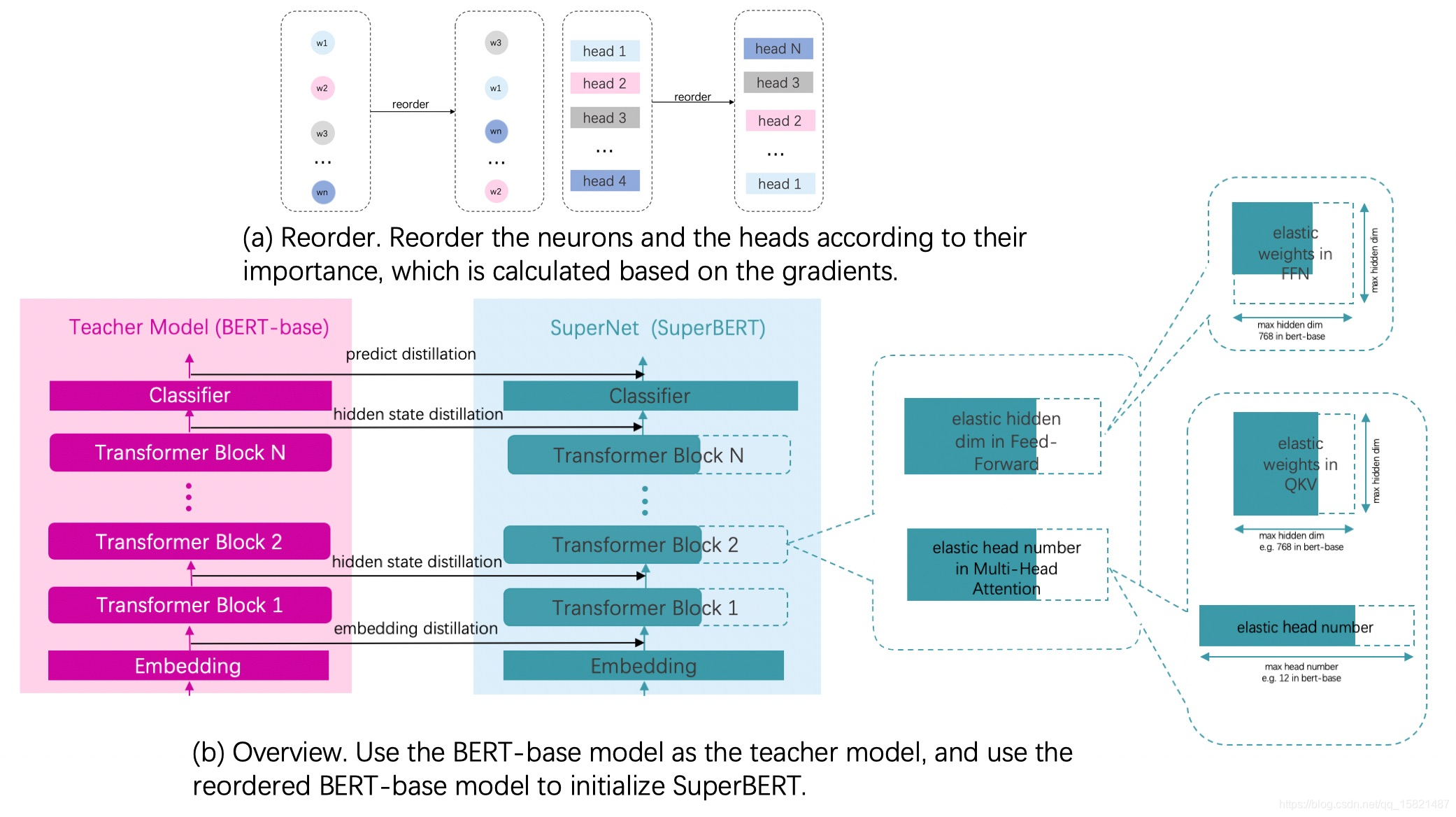
对Fine-tuning得到模型通过计算参数及其梯度的乘积得到参数的重要性,把模型参数根据重要性进行重排序。
超网络中最大的子网络选择和Bert-base模型网络结构一致的网络结构,其他小的子网络是对最大网络的进行不同的宽度选择来得到的,宽度选择具体指的是网络中的参数进行裁剪,所有子网络在整个训练过程中都是参数共享的。
用重排序之后的模型参数作为超网络模型的初始化参数。
Fine-tuning之后的模型作为教师网络,超网络作为学生网络,进行知识蒸馏。
OFA-训练
在进行Once-For-All训练之前,需要把普通的模型先转换为由动态OP组网的超网络。超网络转换方式可以参考 超网络转换 。Once-For-All 训练参数配置
RunConfig
超网络实际运行需要用到的配置和超参,通过字典的形式配置。如果想使用论文中默认的 Progressive shrinking 的方式进行超网络训练,则本项为必填参数。否则可以通过 paddleslim.nas.ofa.OFA().set_epoch(epoch) 和 paddleslim.nas.ofa.OFA().set_task(task, phase=None) 来手动指定超网络训练所处的阶段。默认:None。参数:
train_batch_size:(int, 可选): 训练时的batch size,用来计算每个epoch包括的iteration数量。默认:None。
n_epochs(list, 可选): 包含每个阶段运行到多少epochs,用来判断当前epoch在超网训练中所处的阶段,默认:None。
total_images(int, 可选): 训练集图片数量,用来计算每个epoch包括的iteration数量。默认:None。
elastic_depth(list/tuple, 可选): 如果设置为None,则不把depth作为搜索的一部分,否则,采样到的config中会包含depth。对模型depth的改变需要在模型定义中的forward部分配合使用,具体示例可以参考 示例 ,默认:None。
dynamic_batch_size(list, 可选): 代表每个阶段每个batch数据应该参与几个子网络的训练,shape应该和n_epochs的shape保持一致。默认:None。
返回: 训练配置。示例代码:from paddleslim.nas.ofa import RunConfig
default_run_config = {'train_batch_size': 1,'n_epochs': [[1], [2, 3], [4, 5]],'total_images': 12,'elastic_depth': (5, 15, 24),'dynamic_batch_size': [1, 1, 1],
}
run_config = RunConfig(**default_run_config)
DistillConfig
如果在训练过程中需要添加蒸馏的话,蒸馏过程的配置和超参,通过字典的形式配置,默认:None。参数:
lambda_distill(float, 可选): 蒸馏loss的缩放比例,默认:None。
teacher_model(instance of paddle.nn.Layer, 可选): 教师网络实例,默认:None。
mapping_layers(list[str], 可选): 如果需要给模型中间层添加蒸馏,则需要用这个参数给出需要添加蒸馏的中间层的名字,默认:None。
teacher_model_path(str, 可选): 教师网络预训练模型的路径,默认:None。
distill_fn(instance of paddle.nn.Layer, 可选): 如果需要自定义添加蒸馏loss,则需要传入loss的实例,若传入参数为None,则默认使用mse_loss作为蒸馏损失,默认:None。
mapping_op(str, 可选): 如果在给模型中间层添加蒸馏的时候教师网络和学生网络中间层的shape不相同,则给学生网络中间层添加相应的op,保证在计算蒸馏损失时,教师网络和学生网络中间层的shape相同。该参数可选范围为 ["conv", "linear", None] ,'conv'表示添加Conv2D,'linear'表示添加Linear,None表示不添加任何op。若使用本参数在蒸馏过程中额外添加op,则在优化过程中可以调用 paddleslim.nas.ofa.OFA().netAs_param 获取到这些op的参数,并把这些op的参数添加到优化器的参数列表中。默认:None。
返回: 蒸馏配置。示例代码:from paddleslim.nas.ofa import DistillConfig
default_distill_config = {'lambda_distill': 0.01,'teacher_model': teacher_model,'mapping_layers': ['models.0.fn'],'teacher_model_path': None,'distill_fn': None,'mapping_op': 'conv2d'
}
distill_config = DistillConfig(**default_distill_config)
OFA
把超网络训练方式转换为Once-For-All的方式训练。在 Once-For-All论文 中,提出 Progressive Shrinking 的超网络训练方式,具体原理是在训练过程中按照 elastic kernel_size 、 elastic width 、 elactic depth 的顺序分阶段进行训练,并且在训练过程中逐步扩大搜索空间,例如:搜索空间为 kernel_size=(3,5,7), expand_ratio=(0.5, 1.0, 2.0), depth=(0.5, 0.75, 1.0) ,则在训练过程中首先对kernel size的大小进行动态训练,并把kernel_size的动态训练分为两个阶段,第一阶段kernel_size的搜索空间为 [5, 7] ,第二阶段kernel_size的搜索空间为 [3, 5, 7] ;之后把expand_ratio的动态训练加入到超网络训练中,和对kernel_size的训练方式相同,对expand_ratio的动态训练也分为两个阶段,第一阶段expand_ratio的搜索空间为 [1.0, 2.0] ,第二阶段expand_ratio的搜索空间为 [0.5, 1.0, 2.0] ;最后对depth进行动态训练,训练阶段和kernel_size相同。.. py:class:: paddleslim.nas.ofa.OFA(model, run_config=None, distill_config=None, elastic_order=None, train_full=False)源代码参数:model(paddle.nn.Layer): 把超网络的训练规则转换成默认的Once-For-All论文中推荐的方式训练。
run_config(paddleslim.ofa.RunConfig, 可选): 模型运行过程中的配置,默认:None。
distill_config(paddleslim.ofa.DistillConfig, 可选): 若模型运行过程中添加蒸馏的话,蒸馏相关的配置,具体可配置的参数请参考 `DistillConfig <>`_ , 为None的话则不添加蒸馏,默认:None。
elastic_order(list, 可选): 指定训练顺序,若传入None,则按照默认的 Progressive Shrinking 的方式进行超网络训练,默认:None。
train_full(bool, 可选): 是否训练超网络中最大的子网络,默认:False。
返回: OFA实例示例代码:from paddle.vision.models import mobilenet_v1
from paddleslim.nas.ofa import OFA
from paddleslim.nas.ofa.convert_super import Convert, supernetmodel = mobilenet_v1()
sp_net_config = supernet(kernel_size=(3, 5, 7), expand_ratio=[1, 2, 4])
sp_model = Convert(sp_net_config).convert(model)
ofa_model = OFA(sp_model)
.. py:method:: set_epoch(epoch)手动设置OFA训练所处的epoch。参数:
epoch(int): - 模型训练过程中当前所处的epoch。
返回: None示例代码:ofa_model.set_epoch(3)
.. py:method:: set_task(task, phase=None)手动设置OFA超网络训练所处的阶段。参数:
task(list(str)|str): 手动设置超网络训练中当前训练的任务名称,可选 "kernel_size", "width", "depth" 。
phase(int, 可选): 手动设置超网络训练中当前训练任务所处的阶段,阶段指的是 Progresssive Shrinking 训练方式中每个任务依次增加搜索空间,不同阶段代表着不同大小的搜索空间,若为None,则当前任务使用整个搜索空间,默认:None。
返回: None示例代码:ofa_model.set_task('width')
.. py:method:: set_net_config(config)手动指定训练超网络中的指定配置的子网络,在训练超网络中特定的某一个或几个子网络时使用。参数:
config(dict): 某个子网络训练中每层的训练配置。
返回: None示例代码:config = {'conv2d_0': {'expand_ratio': 2}, 'conv2d_1': {'expand_ratio': 2}} ofa_model.set_net_config(config)
.. py:method:: calc_distill_loss()若OFA训练过程中包含中间层蒸馏,则需要调用本接口获取中间蒸馏损失。返回: 中间层蒸馏损失。示例代码:distill_loss = ofa_model.calc_distill_loss()
.. py:method:: search()
### TODO.. py:method:: export(origin_model, config, input_shapes, input_dtypes, load_weights_from_supernet=True)根据传入的原始模型结构、子网络配置,模型输入的形状和类型导出当前子网络,导出的子网络可以进一步训练、预测或者调用框架动静转换功能转为静态图模型。参数:
origin_model(paddle.nn.Layer): 原始模型实例,子模型会直接在原始模型的基础上进行修改。
config(dict): 某个子网络每层的配置,可以用。
input_shapes(list|list(list)): 模型输入的形状。
input_dtypes(list): 模型输入的类型。
load_weights_from_supernet(bool, optional): 是否从超网络加载参数。若为False,则不从超网络加载参数,则只根据config裁剪原始模型的网络结构;若为True,则用超网络参数来初始化原始模型,并根据config裁剪原始模型的网络结构。默认:True。
返回: 子模型实例。示例代码:from paddle.vision.models import mobilenet_v1 origin_model = mobilenet_v1()config = {'conv2d_0': {'expand_ratio': 2}, 'conv2d_1': {'expand_ratio': 2}} origin_model = ofa_model.export(origin_model, config, input_shapes=[1, 3, 28, 28], input_dtypes=['float32'])
这篇关于PaddleSlim对BERT-base模型进行压缩/OFA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







