本文主要是介绍python二叉堆的建立、上浮与下沉,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
def up_adjust(array=[]):"""二叉堆的尾节点上浮操作,最小堆:param array:原数组:return:"""child_index = len(array) - 1parent_index = (child_index - 1) // 2"""temp保存插入的叶子节点值,用于最后的赋值"""temp = array[child_index]while child_index > 0 and temp < array[parent_index]:# 无需真正交换,单向赋值即可array[child_index] = array[parent_index]child_index = parent_indexparent_index = (parent_index - 1) // 2array[child_index] = tempdef down_adjust(parent_index,length,array=[]):"""二叉树的节点下沉操作:param parent_index: 待下沉的节点下标:param length: 堆的长度范围:param array: 原数组:return:"""# temp保存父节点值,用于最后的赋值temp = array[parent_index]child_index = 2 * parent_index + 1while child_index < length:"""如果有右孩子,且右孩子小于左孩子的值,则定位到右孩子"""if child_index + 1 < length and array[child_index+1] < array[child_index]:child_index +=1# 如果父节点小于任何一个孩子的值,直接跳出if temp <= array[child_index]:break# 否则将父节点的值赋值为子节点的值,父节点继续下沉array[parent_index] = array[child_index]parent_index = child_indexchild_index = 2 * parent_index + 1array[parent_index] = tempdef build_heap(array=[]):"""二叉堆的构建操作:param array: 原数组:return:"""# 从最后一个非叶子节点开始,依次下沉调整for i in range((len(array)-2)//2,-1,-1):down_adjust(i,len(array),array)
初始序列,上浮最后一个节点
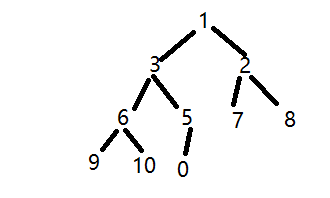
my_array = [1, 3, 2, 6, 5, 7, 8, 9, 10, 0]
up_adjust(my_array)
print(my_array)
my_array = [7, 1, 3, 10, 5, 2, 8, 9, 6]
build_heap(my_array)
print(my_array)
这篇关于python二叉堆的建立、上浮与下沉的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




