本文主要是介绍使用TF-IDF对Tweets做summarization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文本自动文摘(automatic summarization/abstracting)是利用计算机自动实现文本分析、内容归纳和摘要自动生成的技术。这项技术在互联网技术迅速发展、海量信息急速膨胀的今天,具有非常重要的用途。Tweets作为社交媒体内容的典型代表,具有极大的研究价值。本文尝试将经典的TF-IDF算法应用到tweets上提取原文中最有代表性的句子做automatic summarization。
写文章不容易,如果这篇文章对你有帮助,请给我的github仓库加个star~
github项目地址
0. 认识数据
本文中使用的tweets数据由以下几个属性组成:
- id. Twitter API 中下载数据自带的id;
- topic. 命名实体识别的结果,作为topic使用;
- sentiment. 情感分析的结果,在本文中没有使用;
- body. Tweets正文,summarization作用的具体对象;
E.g:
id topic sentiment body
628949369883000832 @microsoft negative dear @Microsoft the newOoffice for Mac is grea...1. 预处理
第一步是句子级的tokenization,因为我们的任务目标是提取句子。
第二步是清理数据。 直观地讲,像URL这样的字符串,“@ …”,标题和标点符号很少有助于句子的重要性。 另外,在大多数的NLP任务中,stopwords通常都会被视为噪音。 这些东西应该被删除。
第三步,为tf-idf计算创建一个遵循原始句子序列的过滤单词列表。
示例预处理输出:
Number of sentences:158
['dear @Microsoft the newOoffice for Mac is great and all, but no Lync update?',"C'mon.","@Microsoft how about you make a system that doesn't eat my friggin discs.",'This is the 2nd time this has happened and I am so sick of it!',"I may be ignorant on this issue but... should we celebrate @Microsoft's "'parental leave changes?']
------------------------------------------------------------------------------------
Number of unique words after filtering:591
[['dear', 'newooffice', 'mac', 'great', 'lync', 'update'],['cmon'],['microsoft', 'make', 'system', 'doesnt', 'eat', 'friggin', 'discs'],['2nd', 'time', 'happened', 'sick'],['may', 'ignorant', 'issue', 'celebrates', 'parental', 'leave', 'changes']]3. 计算TF-IDF值
数学意义上,tf-idf可以表示为如下公式:
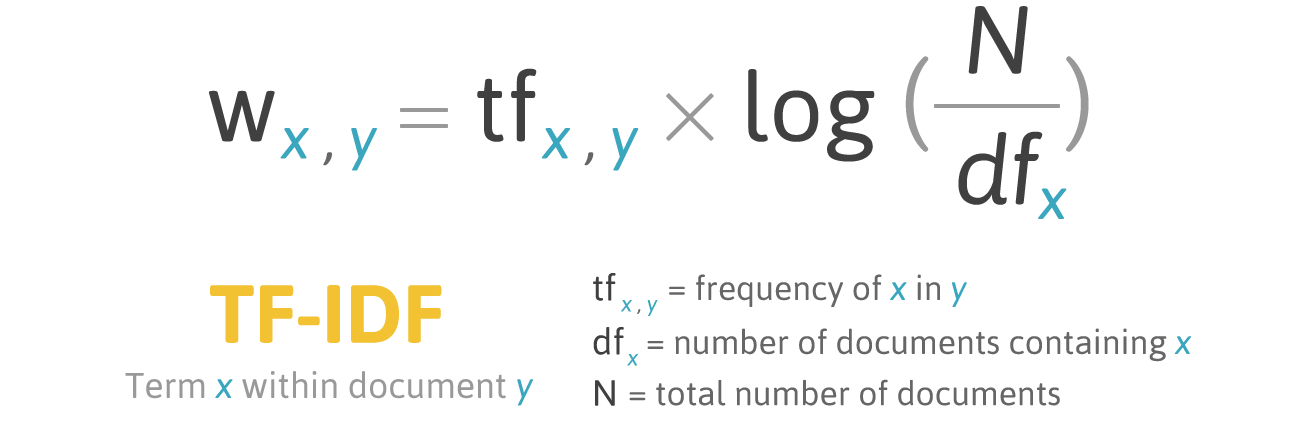
在本文中,tf代表经过预处理后的单词x在输入句子中出现的频率,N代表tokenized后的句子总数,df代表包含单词x的句子总数。
算法实现中,我使用textacy,一个基于spaCy的python库。由于我只关心每个句子的有意义的单词,所以我将此技术应用在上一步创建的过滤单词列表上。
def tfidf(data_tokenized):'''Caculate tf-idf matrix.:param data_tokenized: A sequence of tokenized documents, where each document is a sequence of (str) terms.:return: vectorizer, instance of textacy.vsm.Vectorizer.calculate , tf-idf matrix whose row is document, column is term'''vectorizer = Vectorizer(weighting='tfidf')term_matrix = vectorizer.fit_transform(data_tokenized).todense() # dense matrix means most of the elements are nonzeroreturn vectorizer, term_matrix正如我在代码注释中提到的,返回term_matrix是一个单词-文档矩阵,也称为“bag-of-words”。 在这种情况下,term_matrix包含158个文档和591个单词,它们与在预处理步骤中创建的过滤后的句子数量和去掉重复词的单词数量相对应。
4. 提取最具代表性的句子作summarization
由于tweet很短,一些广泛使用的技术,如position weights和biased heading weights不适合此任务。在目前阶段,使用每个句子的tf-idf值的总和排序句子。
def rank_sentences(sents, filtered_words, vectorizer, term_matrix, top_n=3):'''Select top n important sentence.:param sents: a list containing sentences.:param filtered_words: a tokenized sentences list whose element is word list:param vectorizer: instance of textacy.vsm.Vectorizer:param term_matrix: tf-idf matrix whose row is document, column is term:param top_n: the selecting number:return: a list containing top n important sentences'''tfidf_sent = [[term_matrix[index, vectorizer.vocabulary[token]] for token in sent] for index, sent inenumerate(filtered_words)] # Get tfidf value for noun word in each sentencesent_values = [sum(sent) for sent in tfidf_sent] # Caculate whole tfidf weights for each sentenceranked_sent = sorted(zip(sents, sent_values), key=lambda x: x[1], reverse=True) # Sort sentence at descending orderreturn [sent[0] for sent in ranked_sent[:top_n]]示例最终结果输出:
["@eyesonfoxorg @Microsoft I'm still using Vista on one & Win-7 on "'another, Vista is a dinosaur, unfortunately I may use a free 10 with limits','W/ all the $$$ and drones U have working 4 U, maybe U guys could get it ''right the 1st time?',"@Lumia #Lumia @Microsoft 2nd, you guys haven't released a lumia that has a "'QHD screen, or takes video in 2k resolution yet.']参考文献
- Sentence Extraction by tf/idf and Position Weighting from Newspaper Articles
- Automatic Summarization
- 统计自然语言处理(第2版)
这篇关于使用TF-IDF对Tweets做summarization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





