学习重点:
一、主要的安装包,requests、BeautifulSoup4
二、首先爬取每页的网址
三、再爬取每页的全部图片
四、下载图片和设置保存路径和图片名字
五、整合代码
1、主要的安装包requests、BeautifulSoup4
1)用来请求网络数据requests
2)用来解析html文档,然后过滤我们需要的数据BeautifulSoup4
3)引用安装包有两种方法,可以全部导入进来,也可以只导入你需要的部分进来
import requestsFrom bs4 import BeautifulSoup4 2、首先爬取每页的网址
爬取的网站为斗图啦:https://www.doutula.com/photo/list/
我们要来分析一下爬取网站的url=https://www.doutula.com/photo/list/ 当你点击到不同的页面上是会发现网址变了,而且还非常有规律的变化,如图到第三页(https://www.doutula.com/photo/list/?page=3)多了一个?page=3,
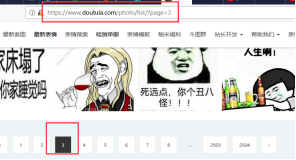
当你到100页你发现多了一个?page=100,所以我们可以用一个For循环来获取全部的页面,
BASE_PAGE_URL = ‘https://www.doutula.com/photo/list/?page=’
BASE_URL_LIST = []
for x in range(1,401): #爬取1到400页的表情url = BASE_PAGE_URL + str(x)#将1到400转换成字符串形式#print(url)#可以打印来看看是不是1-400页全部的网址PAGE_URL_LIST.append(url)#存入到列表中 打印结果:

3、再爬取每页的全部图片
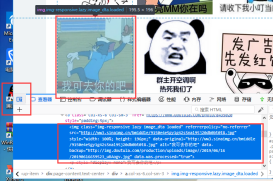
爬取每页的全部图片,这时就需要来分析网页源代码,看图片放在什么地方。鼠标右击进入网页元素界面如下图:

要想找到某张图片对应的网页源代码,点击如图所示箭头即可快速找到
找到资源那就来分析是不是有规律,果然如此,我们发现每张图片的img标签的属性class都相同class= “img-responsive lazy image_dta loaded”,不要加loaded,加了下载不到图片(原因不明)
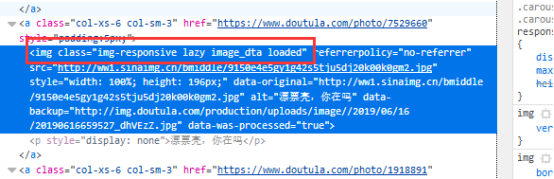
所以又可以通过For循环来获取整页的图片网址
re = requests.get('https://www.doutula.com/photo/list/?page=1')
content = re.content
# 解析该页面
soup = BeautifulSoup(content, 'lxml')
img_list = soup.find_all('img', attrs={'class': 'img-responsive lazy image_dta'})
for img in img_list:print('http:' + img['data-original'])print('_'*30) 打印结果:点击网址即可出现图片
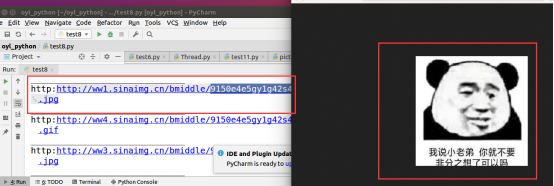
4、下载图片的保存路径和图片名称设置
这里需要用到另外一个python自带urllib.request库,导入方法同上。
url = 'http://ww1.sinaimg.cn/bmiddle/9150e4e5gy1g3wwi7dn6sj208c08caab.jpg'
split_list = url.split('/')#将url字符串分割成四段[‘http:’,’ww1.sinaimg.cn’,’bmiddle’,’9150e4e5gy1g3wwi7dn6sj208c08caab.jpg’]
filename = split_list.pop() #将9150e4e5gy1g3wwi7dn6sj208c08caab.jpg作为图片的名字
path = os.path.join('imgpic', filename)#保存路径,
#注意Windows为(反斜杠)和Linux(斜杠)里面路径不同
#D:\sourceis\imgpic
#~/oyl_python/imgpic
urllib.request.urlretrieve(url, filename=path) 运行结果:创建了一个imgpic的文件夹,里面下载了一张名称为9150e4e5gy1g3wwi7dn6sj208c08caab.jpg的图片
5、整合代码
#!/usr/bin/env/python
# _*_coding:utf-8 _*_#用来请求网络数据
import requests
import urllib.request
#用来解析HTML文档,然后过滤我们需要的数据
from bs4 import BeautifulSoup
import os
#每页数据 https://www.doutula.com/photo/list/?page=1#获取1到400的全部页面
BASE_PAGE_URL = 'https://www.doutula.com/photo/list/?page='
PAGE_URL_LIST = []
for x in range(1,401):url = BASE_PAGE_URL + str(x)PAGE_URL_LIST.append(url)def download_imge(url):#url = 'http://ww1.sinaimg.cn/bmiddle/9150e4e5gy1g3wwi7dn6sj208c08caab.jpg'split_list = url.split('/')filename = split_list.pop() path = os.path.join('imgpic', filename)try:urllib.request.urlretrieve(url, filename=path)except:passdef get_page(page_url):# 获取每页里面的图片#re = requests.get('https://www.doutula.com/photo/list/?page=1')re = requests.get(page_url)# print(re.content)content = re.content# 解析该页面soup = BeautifulSoup(content, 'lxml')img_list = soup.find_all('img', attrs={'class': 'img-responsive lazy image_dta'})# print(img_list)for img in img_list:# print('http:' + img['data-original'])# print('_'*30)# url = 'http:' + img["data-original"]url = img["data-original"]download_imge(url)def main():for page_url in PAGE_URL_LIST:get_page(page_url)passif __name__ == '__main__':main()





