斗图专题

装X - 建立自己的斗图网站库
https://zhuanlan.zhihu.com/p/25130191?utm_source=tuicool&utm_medium=referral 作者:yuyuyu 链接:https://zhuanlan.zhihu.com/p/25130191 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 之前加过一个斗图群,看到很多经典的表情,然后就

2020/4/11 斗图啦多线程爬取表情包
【斗图啦多线程爬虫思路】 网站:https://www.doutula.com/photo/list/?page=1 爬取的是最新的表情包这个页面的图片 思路 1.分析需求,创建解析线程和下载线程 因为按照顺序爬取速度比较忙,所以也是第一次使用多线程来爬取,加快爬取速度。 2.空列表的预先准备 把初始url地址构造好后统一放入到一个空列表中,方便调用多个线程解析 把线程解析后的url统一放入
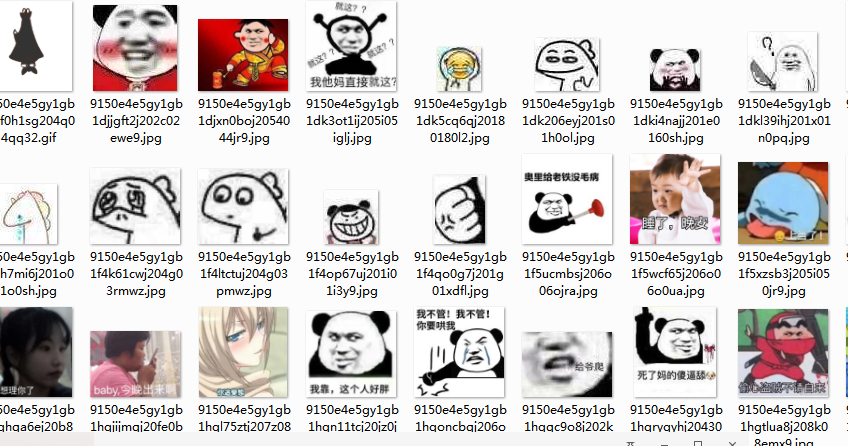
多线程采集表情包,下一届斗图王者属于你
前几天和朋友微信吹牛,这年头吹牛光发文字,根本解决不了问题,无法让他感觉到你此时的情绪波动,奈何自己平常不怎么注意盗图,导致自己在斗图这一环节败下阵来。当时那是一个气呀,我堂堂八尺男儿,怎么能被这样嘲讽,不能忍,我大鱼人今天要教他做大人!!! 想着确实好久没有写爬虫,之前在学习的时候,线程的消费者和生产者队列也该拿出来实践实践了。 逻辑梳理 使用queue来做队列,生产者调用来个queue,

聊天没有表情包被嘲讽,python在手,从此斗图无敌手~
导语: 哈喽,哈喽~微信斗图,大家最喜欢的就是发布Gif动图表情包了。 “表情包”是现在非常流行的交流方式,通过一张图片就能把文字不能表达或不便于表达的情感给表示出来,表情包一经诞生,就统治了中国人的社交圈,尤其是年轻人,他们的社交方式是所谓“天可不聊,图不可不斗”。 Gif动图,它的原理其实很简单,就是一帧一帧的图片拼接在一起,组合而成的。当他们来回切换的速度很快时,就相当于在

表情制作PHP源码 表情斗图生成源码 斗图工具源码 一键搜索百万图片 系统自适应
PHP熊猫头图片表情斗图生成源码,自适应的系统,手机也可以正常用!源码集成了搜狗搜索图片接口,可以一键搜索百万图片,还有表情制作等模块,拿去引流还是非常不错的对于一些新站来说引流神器! 源码下载:https://download.csdn.net/download/m0_66047725/88551821
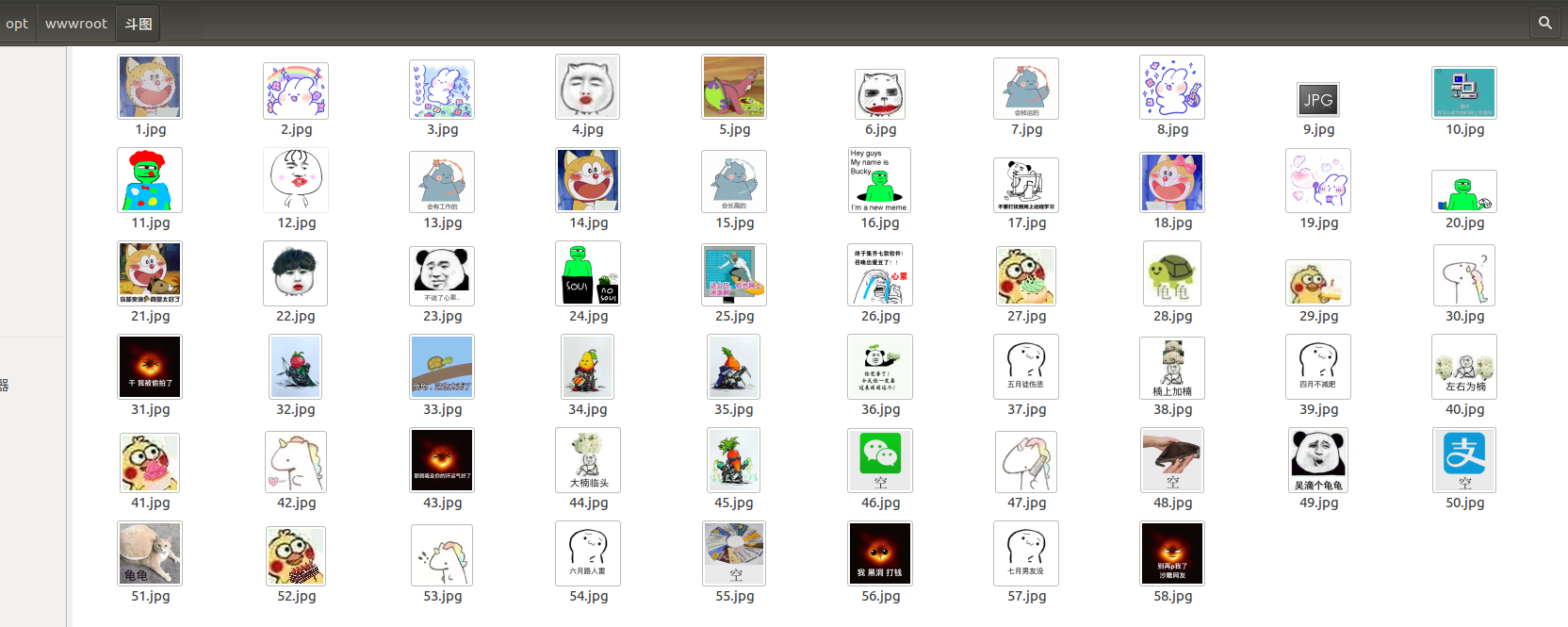
最新PHP熊猫头图片表情斗图生成源码
这是一款能生成熊猫头表情斗图的自适应系统源码,无论是在电脑还是手机上都可以正常使用!这个源码集成了搜狗搜索图片接口,可以轻松地一键搜索数百万张图片,并且还包含了表情制作等功能模块。对于一些新站来说,这是一个非常不错的引流神器,可以帮助他们吸引更多的流量。 来自:人类小徐-分享有价值的资源

斗图不用怕!用 serverless 随时创建你的表情包
meme economy(表情包经济)显然是下一件大事!这是互联网注意力经济的自然延伸,Elon Musk也沉迷于此。据估计,meme economy 已经价值 2.5亿美元了。 The meme economy is where FOMO meets YOLO. — Felix Salmon from AXIOS 现在谁的手机还没存几个表情包 meme 呢? 然而,找到合适的 mem

python爬虫我是斗图之王
python爬虫我是斗图之王 本文会以斗图啦网站为例,爬取所有表情包。 阅读之前需要对线程池、连接池、正则表达式稍作了解。 分析网站 页面url分析 打开斗图啦网站,简单翻阅之后发现最新表情每页包含的表情是最多的。 其url是: /photo/list/?page=2 其中page参数为页码,目前有1578页 页面图片元素分析 使用chrome的开发者工具分析一个图片的元素 <img src
爬虫python漏洞群_干货分享 | python爬虫我是斗图之王
满满的干货 快来BugScan社区分享交流吧 点击文末“阅读原文”可直接进入社区 悄悄的告诉你,社区论坛留言区有源码喔 本文会以斗图啦网站为例,爬取所有表情包。 阅读之前需要对线程池、连接池、正则表达式稍作了解。 分析网站 页面url分析 打开斗图啦网站,简单翻阅之后发现最新表情每页包含的表情是最多的。 其url是: /photo/list/?page=2 其中page参数为页码,目前有1578
t想成为微信斗图之王么?你需要这款开源工具的力量!
我在全球最大的同性交友社区Github创建了一个仓库,仓库用来收集表情包,表情包已有3000多张 image-20201007141408785 image-20201007141440658 规范的整理并不能让我瞬间定位特定表情包,于是我给表情包按内容做了命名,命名可以让我瞬间定位表情包,使用效果如下 https://www.v2fy.com/asset/0
Python--爬虫之(斗图啦网站)图片爬取
学习重点: 一、主要的安装包,requests、BeautifulSoup4 二、首先爬取每页的网址 三、再爬取每页的全部图片 四、下载图片和设置保存路径和图片名字 五、整合代码 1、主要的安装包requests、BeautifulSoup4 1)用来请求网络数据requests 2)用来解析html文档,然后过滤我们需要的数据BeautifulSoup4
【Python】斗图啦表情包多线程爬取
斗图啦表情包多线程爬取-写在前面 发现好多人写爬虫都在爬取一个叫做斗图啦的网站,里面很多表情包,然后瞅了瞅,各种实现方式都有,今天我给你实现一个多线程版本的。关键技术点 aiohttp ,你可以看一下我前面的文章,然后在学习一下。 网站就不分析了,无非就是找到规律,拼接URL,匹配关键点,然后爬取。 斗图啦表情包多线程爬取-撸代码 首先快速的导入我们需要的模块,和其他文章不同,我把相同的表

爬虫项目(斗图啦scrapy)
斗图啦网址 https://www.doutula.com/photo/list/ (1)分析网站 得到图片的地址 (2)进入得到的网址分析 (3)编写项目代码 (4)scrapy爬取,源码 items.py import scrapyclass DoutubaItem(scrapy.Item):# define the fields for your item here like:#
Python爬虫入门【12】: 斗图啦表情包多线程爬取
斗图啦表情包多线程爬取-写在前面 发现好多人写爬虫都在爬取一个叫做斗图啦的网站,里面很多表情包,然后瞅了瞅,各种实现方式都有,今天我给你实现一个多线程版本的。关键技术点 aiohttp ,你可以看一下我前面的文章,然后在学习一下。 网站就不分析了,无非就是找到规律,拼接URL,匹配关键点,然后爬取。 斗图啦表情包多线程爬取-撸代码 首先快速的导入我们需要的模块,和其他文章不同,我把相同的表
PHP图片表情斗图生成源码 一键搜索百万图片
介绍: 自适应的手机也可以浏览! 源码集成了搜狗搜索图片接口,可以一键搜索百万图片,还有表情制作等模块,拿去引流还是非常不错的对于一些新站来说引流神器! 网盘下载地址: http://kekewl.net/vPRg4V6ugc3 图片:
还在用微信推荐表情包?WordPress斗图插件DCO来喽!你是什么粉?你怎么没声了?你成年了吗?...
2020-10-10-shenyi 我最近开发了一个小项目,可以根据任意关键词搜表情包,可以长按分享给好友,一键粘贴到朋友圈,以及通过关键词分享一组表情包。在线地址:https://www.v2fy.com/asset/0i/ChineseBQB/ image-20201010163928555 但表情包数量只有4000多张,为了获得更多的表情包图片数据完善程