本文主要是介绍BSA研究方案——如何从容不迫的进行性状定位,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(一)BSA基本概念
BSA即集群分离分析法,是Bulked-Segregant Analysis的首字母缩写。具体是利用差异目标性状的两个亲本构建家系,在子代分离群体中选取目标性状个体构建DNA混合池,采用高通量测序技术对混池DNA进行建库测序,开发全基因组范围内的SNP、InDel分子标记,以通过计算SNP、InDel的基因型频率,在基因组范围内检测与目标性状相关联的位点与基因,然后对候选基因进行功能注释,进一步探究控制目标性状的基因及其分子机制。

(二)BSA整体实验+测序分析策略
BSA分析是对分离群体极端个体混池进行深度重测序,定位候选区间。适用于参考基因组中等或者较小的物种。
BSR是将BSA与RNA-seq结合起来的分析方法,是对分离群体极端性状的个体,分别提取两个池的总RNA,进行RNA-seq。由于基因只占基因组的1-3%,BSR更适用于基因组较大的物种,比如麦类物种。
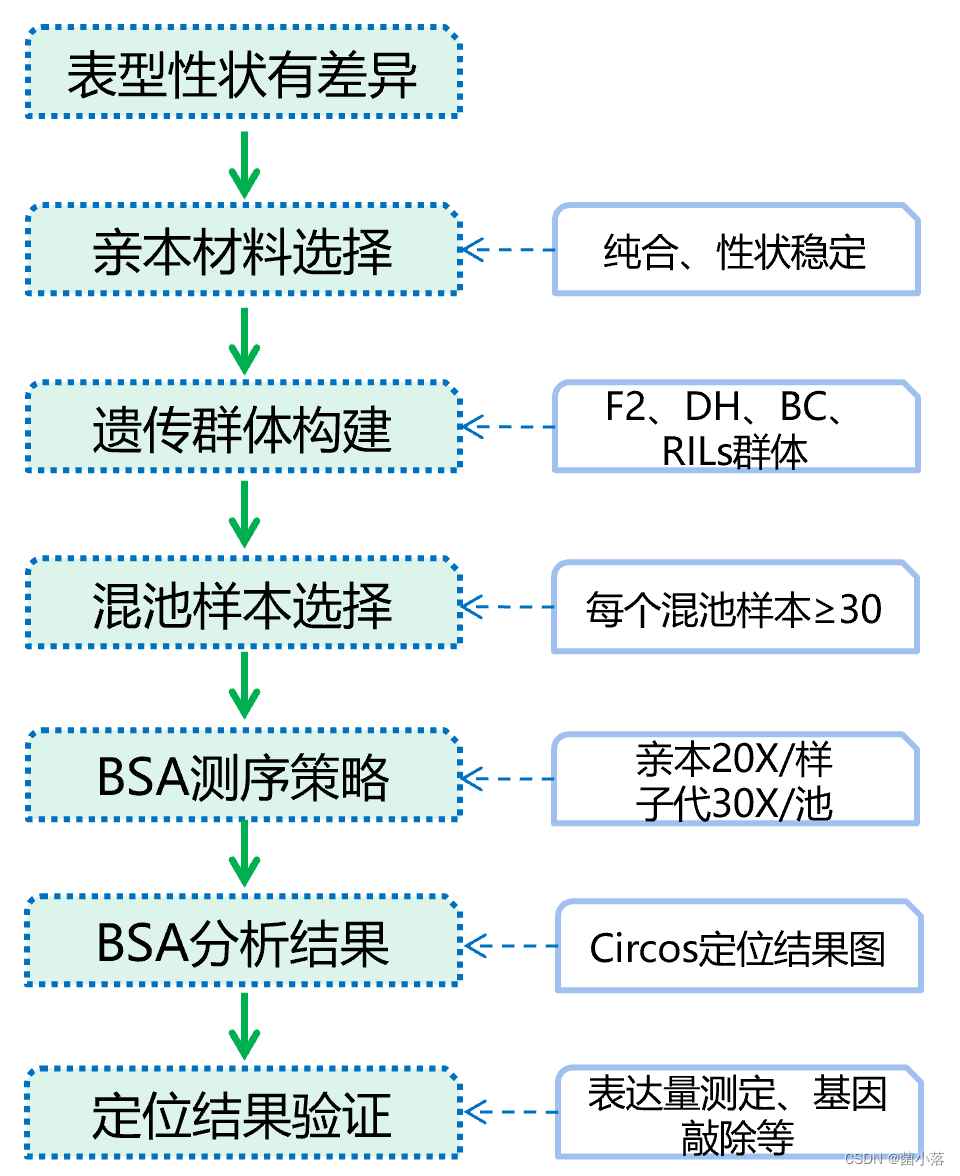
(三)派森诺BSA优势-有六种分析方法适用不同群体方案
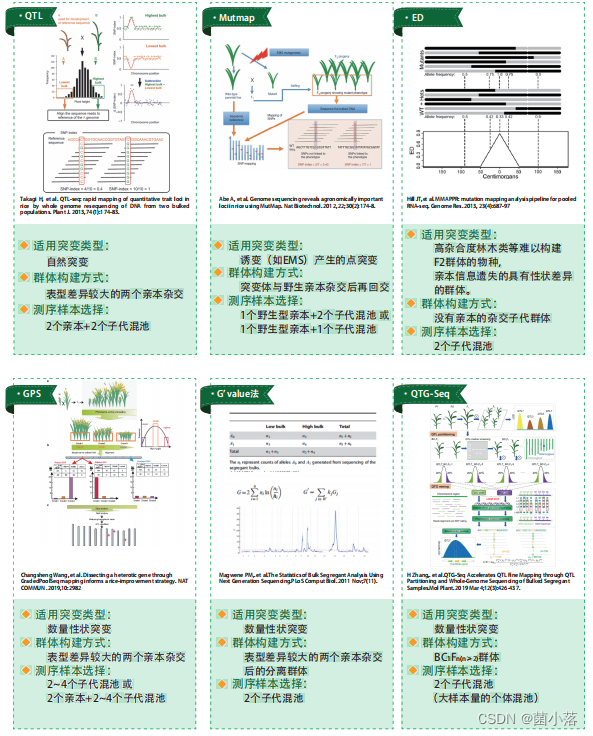
BSA诞生至今,其关联算法也逐渐演变和分化。根据不同的遗传群体材料和遗传设计,有针对自然群体的Δ(SNP-index)、有针对EMS诱变材料的MutMap法(Abe et al., 2012)、针对无亲本只有两个极端混池的欧氏距离法(ED)(Hill et al., 2013)、基于一个大的F2群体并依据表型分组(三组以上)的GradedPool-seq(GPS)法(Wang et al., 2019)和较复杂的遗传设计QTG-seq法(Zhang et al., 2019a)等;根据数学算法不同,除了以上算法外,还有G’ value法(Magwene et al., 2011)算法。
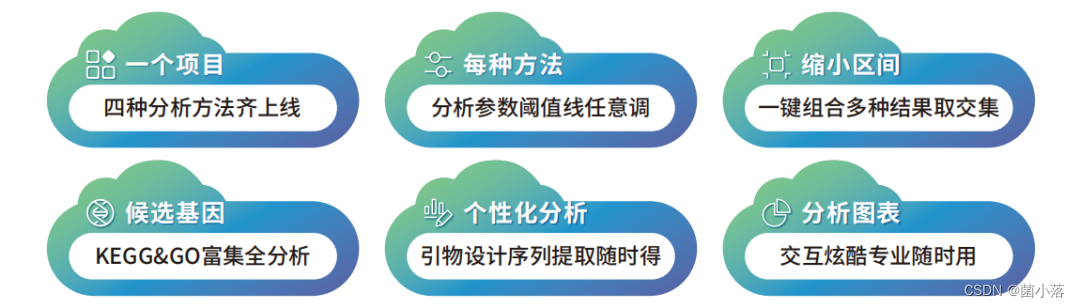
(四)派森诺BSA优势-BSA云平台您身边的生信小能手,助力个性化数据挖掘
派森诺BSA云平台已上线,可提供BSA云分析服务,实现数据上传、参数自主调整、多种方法在线交并集、目标区域序列提取、引物设计…众多个性化分析服务,满足您的定位需求。
(五)BSA经典结果展示
【派森诺BSA项目文章】

中文题目:基因CsUFO涉及黄瓜花和卷须的形成
发表期刊:《Theoretical and Applied Genetics》
影响因子:5.4
发表时间:2021年03月
文章链接:DOI:10.1007/s00122-021-03811-4
摘要
本文材料来源为一个编码F-box蛋白的基因突变而引起黄瓜花和卷须产生不寻常变异的突变体,而花和卷须是黄瓜的重要农艺性状,与产量密切相关。
文章研究思路
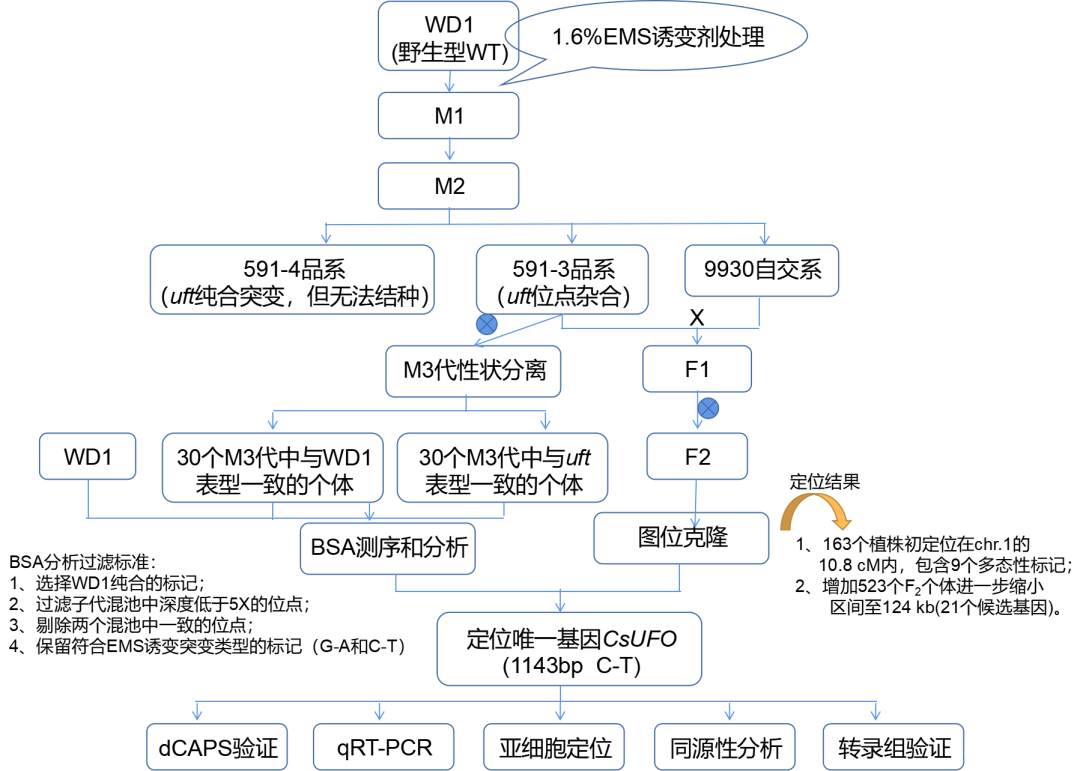
研究结果
R1:突变体表型特征和遗传分析(细致的性状调查是成功的第一步)
uft突变体植雄花在花瓣位置有多余的叶状器官(图1)。典型瓣花通常有五个萼片和五个花冠裂片(图1-A2),而uft突变体花有多达13个生殖器官(萼片和叶状器官)(图1-B2)。此外uft突变体的雌雄蕊不能很好地一起生长(图1-B5、B6),以及雄花的萼片、花瓣和雄蕊原基明显发育不正常(图1-B7)。除了有不正常的花瓣和雌蕊外,uft突变体的雌花还在其果柄上长出叶状器官(图1-B4)。除了花器官,uft突变体也有异常的卷须,其顶端被叶状器官取代(图1-B3)。
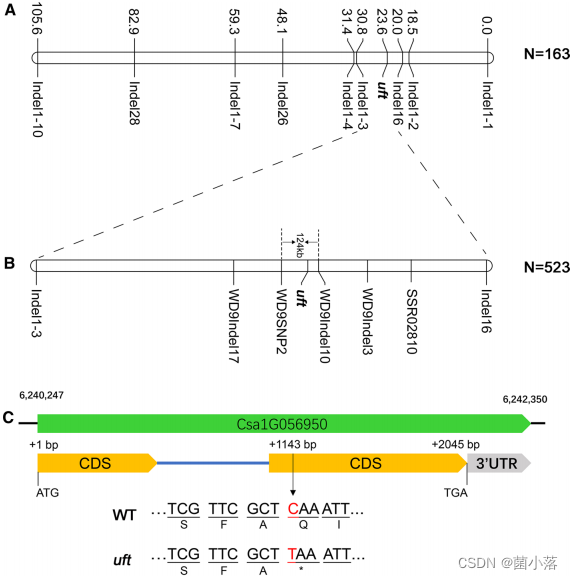
图1 野生型(A表示)与突变体(B表示)的表型特征
R2:精细定位(图位克隆+BSA双管齐下)
基于163个F2单株、9对多态性标记,初定位到Chr.1上的20.0cM到30.8cM之间(2.3Mb),进一步开发多态标记、增加上图个体进一步定缩小到124kb,共21个候选基因。
重点:通过30个野生型表型的个体DNA混池和30个uft表型的个体DNA混池,再加WD1亲本的高通量测序,基于MutMap+分析策略在候选区间内获得4个候选SNP位点,进一步分析确定标记SNP6241389。
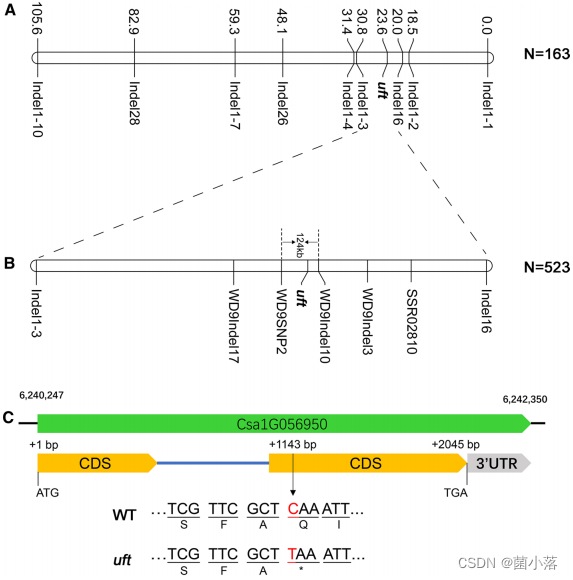
图2 uft的精细定位结果
R3:候选基因的功能、表达水平和亚细胞定位(充分的验证)
突变导致氨基酸编码提前终止,与正常基因相比在C端少300个氨基酸。通过5个UFO以及另外13个MADS-box蛋白序列构建进化树表明UFO在同一科的不同物种中高度保守。qRT-PCR结果表明野生型顶芽中CsUFO高表达,而uft突变体的顶芽中该基因表达显著下调。
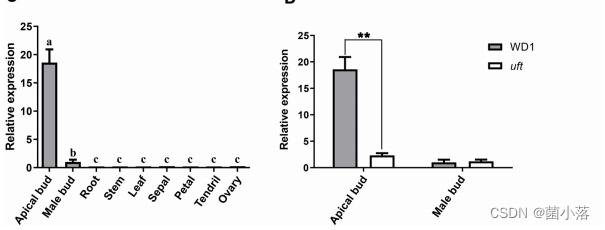
图3候选基因CsUFO的结构、保守性与表达分析。
总 结
本文将传统图位克隆与BSA相结合,利用高通量测序开发全基因组上最丰富的标记类型–SNP,有效弥补传统标记的缺失实现候选区间进一步缩小。
此外本实验的分析根据诱变类型精准锁定SNP突变类型,实现快速准确定位,大大缩短了定位周期,为后续验证实验争取了宝贵时间,丰满文章!
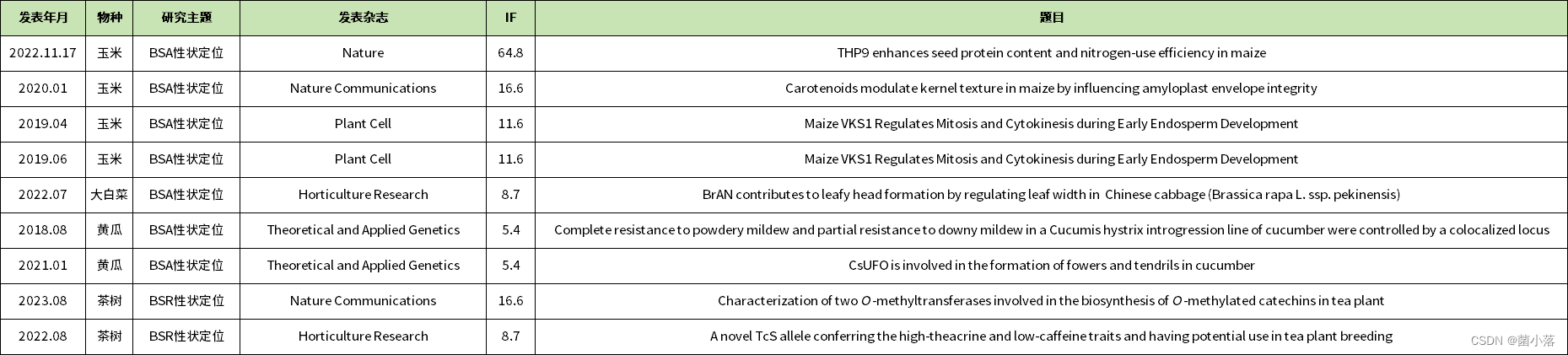
(六)派森诺高分项目文章
总结:BSA是基于群体中挑选极端性状的个体构建混池进行分析的方法,通过研究混池之间等位基因频率的差异,将与性状相关的位点在基因组上进行定位,应用的物种越来越广泛,发表的文章也越来越多,已经是分子遗传育种常规方法之一。赶紧来派森诺云平台试试手,搜索“派森诺基因云”或者点击www.genescloud.cn进入网站进行分析体验吧!当然在体验过程中,有任何的宝贵建议欢迎提交至邮箱 gc_support@personalbio.cn,我们会认真对待每一份建议,不断提升,让您每一次都有更好的体验!
参考文献
Yue Chen, Haifan Wen et al. CsUFO is involved in the formation of flowers and tendrils in cucumber [J] .Theor Appl Genet. 2021 Mar 19. DOI:10.1007/s00122-021-03811-4.
这篇关于BSA研究方案——如何从容不迫的进行性状定位的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







