本文主要是介绍【转】股票K线数据重采样resample()与数据除权处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
3 案例:股票K线数据重采样
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None,kind=None,)
频率转换和时间序列重采样,对象必须具有类似日期时间的索引(DatetimeIndex,PeriodIndex或TimedeltaIndex)
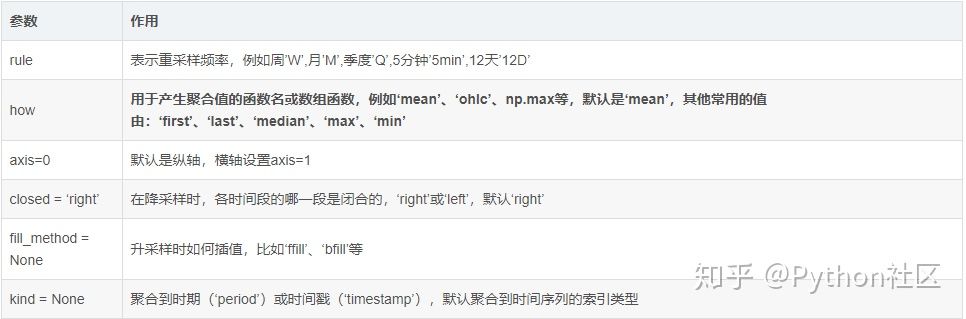
日K周K对比:
那么日线、周线、月线等怎么切换标准??
注:周K线是指以周一的开盘价,周五的收盘价,全周最高价和全周最低价来画的K线图
大部分周线的指标是这个日线指标在这一周最后一个交易日的值。比如周线的’close’应该等于这一周最后一天日线数据的‘close’,但是有的指标是例外,比如周线的’high’应该等于这一周所有日线‘high’中的最大值
接下来我们还是使用之前stock_day当中的某个股票的行情数据
将索引转换成DatetimeIndex类型
对不同指标进行重采样
import pandas as pd
stock_day = pd.read_csv("./stock_day/stock_day.csv")
stock_day = stock_day.sort_index()
# 对每日交易数据进行重采样 (频率转换)
stock_day.index# 1、必须将时间索引类型转换成Pandas默认的类型
stock_day.index = pd.to_datetime(stock_day.index)# 2、进行频率转换日K---周K,首先让所有指标都为最后一天的价格
period_week_data = stock_day.resample('W').last()# 分别对于开盘、收盘、最高价、最低价进行处理
period_week_data['open'] = stock_day['open'].resample('W').first()
# 处理最高价和最低价
period_week_data['high'] = stock_day['high'].resample('W').max()
# 最低价
period_week_data['low'] = stock_day['low'].resample('W').min()
# 成交量 这一周的每天成交量的和
period_week_data['volume'] = stock_day['volume'].resample('W').sum()
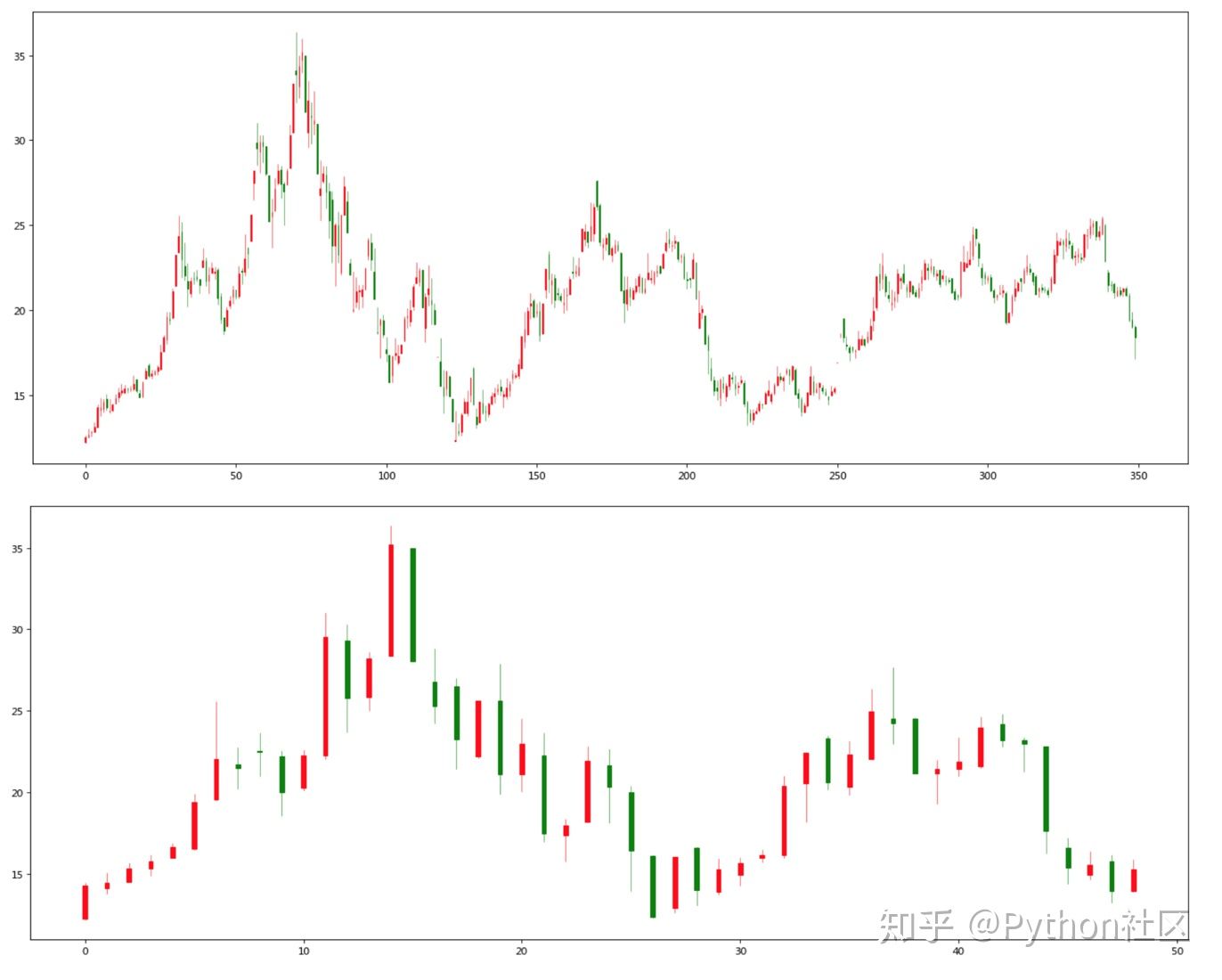
对于其中存在的缺失值
period_week_data.dropna(inplace=True)
我们可以将计算出来的周K和原先的日K画图显示出来
- 画出K线图显示
金融数据绘制需要使用mpl_finance框架
需要指定地址安装:
pip install https://github.com/matplotlib/mpl_finance/archive/master.zip
代码:
from mpl_finance import candlestick_ochl
import matplotlib.pyplot as plt
from matplotlib.pylab import date2num# 先画日K线
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(20, 8), dpi=80)
# 准备数据, array数组
stock_day['date'] = date2num(stock_day.index)
day_k = stock_day[['date', 'open', 'close', 'high', 'low']]
# 绘制k线图
candlestick_ochl(axes, day_k.values, width=0.2, colorup='r', colordown='g')
# x刻度设置为日期
axes.xaxis_date()
plt.show()# 周K线图数据显示出来
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(20, 8), dpi=80)
period_week_data['date'] = date2num(period_week_data.index)
week_k = period_week_data[['date', 'open', 'close', 'high', 'low']]
# 绘制k线图
candlestick_ochl(axes, week_k.values, width=0.2, colorup='r', colordown='g')
# x刻度设置为日期
axes.xaxis_date()
plt.show()
4 什么是除权数据以及复权操作(了解)
上市公司会时不时的发生现金分红、送股等一系列股本变动,这会造成股价的非正常变化,导致我们不能直接通过股价来计算股票的涨跌幅。这种数据我们也称之为除权数据。
所以我们要对这种数据做处理,也称之为复权数据。怎么进行复权呢?
简单的一种方式:
原始数据:
1号:100 2号:50 3号:53 4号:51
复权后:
100 / 50 = 2 比例
1号:100 2号:100 3号:106 4号:102
5 基本面数据
基本面数据的用处
主要用于基本面分析,主要侧重于从股票的基本面因素,如企业经营能力,财务状况,行业背景等对公司进行研究与分析,试图从公司角度找出股票的“内在价值”,从而与股票市场价值进行比较,挑选出最具投资价值的股票。
这篇关于【转】股票K线数据重采样resample()与数据除权处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



