本文主要是介绍区别探索:掩码语言模型 (MLM) 和因果语言模型 (CLM)的区别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大多数现代 NLP 系统都遵循相当标准的方法来为各种用例训练新模型,即首先预训练,然后微调。这里, 预训练的目标是利用大量未标记的文本并构建语言理解的通用模型,然后针对各种特定的 NLP 任务(例如机器翻译、文本摘要等)进行微调。
在本博客中,我们将讨论两种流行的预训练方案,即掩码语言建模(MLM)和因果语言建模(CLM)。
没有时间阅读整个博客?然后观看这段 <60 秒的 短片 -
掩码语言模型解释
在屏蔽语言模型下,我们通常屏蔽给定句子中一定比例的单词,并且模型预计会根据该句子中的其他单词来预测这些屏蔽单词。这样的训练方案使得该模型本质上是双向的,因为掩码词的表示是根据左侧和右侧出现的单词来学习的。您还可以将其想象为填空式的问题陈述。
下图显示了同样的情况——
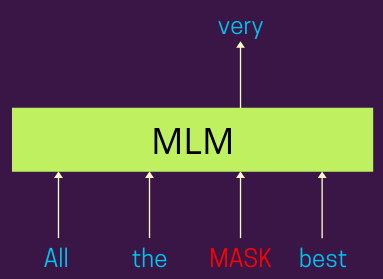
掩码语言模型| 作者提供的图片
下图。显示带有损失计算步骤的更详细视图 —
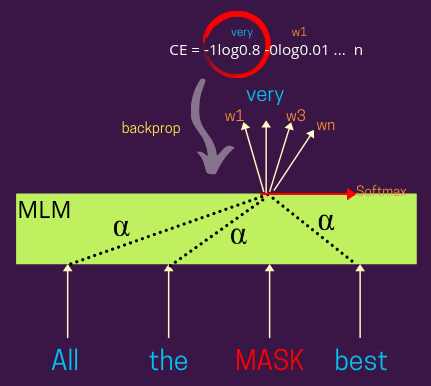
带有损失的屏蔽语言模型 | 作者提供的图片
在这里,屏蔽词的表示可以是基于注意力的,就像BERT及其变体一样,或者你也可以在没有注意力的情况下设计它。基于Alpha (注意力权重)的分布,您可以权衡每个其他输入单词的表示,以学习屏蔽单词的表示,例如 - Alpha=1 会给周围的单词赋予相同的权重(意味着每个单词都会持有MASK 表示中的同等贡献)。
因果语言模型解释
因果语言模型。因果语言模型(causal language model),是跟掩码语言模型相对的语言模型,跟transformer机制中的decoder很相似,因果语言模型采用了对角掩蔽矩阵,使得每个token只能看到在它之前的token信息,而看不到在它之后的token,模型的训练目标是根据在这之前的token来预测下一个位置的token。通常是根据概率分布来计算词之间组合的出现概率,因果语言模型根据所有之前的token信息来预测当前时刻token,所以可以很直接地应用到文本生成任务中。可以理解为encoder-decoder的模型结果使用了完整的transformer结构,但是因果语言模型则只用到transformer的decoder结构(同时去掉transformer中间的encoder-decoder attention,因为没有encoder的结构)。
虽然因果语言模型结构简单而且对于文本生成来说直截了当,但是它本身还是带有一些结构或者算法上的限制。首先因果语言模型都是从左往右对token依次进行编码,忽略了相应的双向信息。其次,因果语言模型不适合处理部分端到端的任务,在包括摘要和翻译等任务中不能取得令人满意的结果。
在因果语言模型下,这里的想法再次是预测给定句子中的屏蔽标记,但与 MLM 不同,该模型允许只考虑出现在其左侧的单词来执行相同的操作(理想情况下,这可以是左侧或右侧)正好,思路就是让它单向)。这样的训练方案使得这个模型本质上是单向的。
如下图所示,模型预计会根据出现在句子左侧的单词来预测句子中存在的掩码标记。根据模型对实际标签的预测,我们计算交叉熵损失并将其反向传播以训练模型参数。
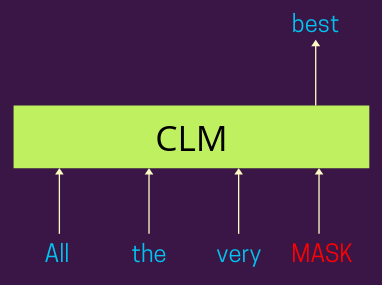
因果语言模型 | 作者提供的图片
下图。显示带有损失计算步骤的更详细视图 —
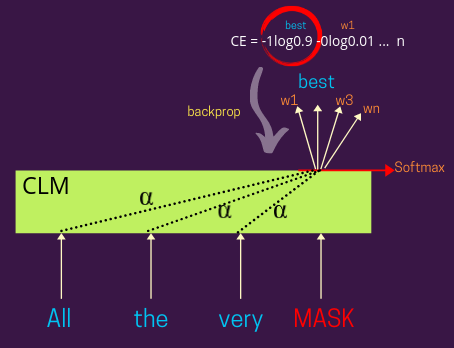
带有损失的因果语言模型 | 作者提供的图片
在这里,屏蔽词的表示可以是基于注意力的,就像GPT和变体一样,或者你也可以在没有它的情况下设计它,就像我们在 LSTM 时代那样。根据Alpha的分布(见图),您可以权衡每个其他输入单词的表示,以学习屏蔽单词的表示,例如 - Alpha=1 会给周围的单词赋予相同的权重(这意味着每个单词都将具有相同的权重)对学习到的 MASK 表示的贡献)。
这些系统也称为仅解码器模型,因为在机器翻译、文本摘要等典型的编码器-解码器架构中,解码器(文本生成器)的工作原理类似。
何时使用什么?
当目标是学习输入文档的良好表示时,MLM 损失是首选, 然而,当我们希望学习生成流畅文本的系统时,CLM 是首选。另外,直观上这是有道理的,因为在学习每个单词的良好输入表示时,您会想知道它出现在左侧和右侧的单词,而当您想学习生成文本的系统时,您只能看到什么到目前为止您所生成的所有内容(就像人类的书写方式一样)。因此,制作一个在生成文本时也可以查看另一侧的系统可能会引入偏差,从而限制模型的创造力。
making a system that could peek to the other side as well while generating text can introduce bias limiting the creative ability of the model.
尽管在训练具有编码器和解码器的整个架构时,您经常会发现 MLM 和 CLM 损失。两者都有各自的优点和局限性,一种名为XLNet的新模型使用排列技术来充分利用两个领域(MLM 和 CLM)的优点。
图1. Judea Pearl 的因果之梯包括三个层级:关联(association)、干预(intervention)和反事实(counterfactual),分别对应逐级复杂的因果问题。
这到底是如何实现的呢?关键之处在于,大语言模型引入一种基于文本和元数据的新推理方式来实现这一目标,称之为基于知识的因果推理(knowledge-based causal reasoning),这与现有的基于数据的方法有所不同。具体而言,大语言模型拥有迄今为止被认为只有人类才具有的能力,如使用知识生成因果图,或从自然语言中识别背景因果关系。
大语言模型可以作为人类领域知识的代理,这对通常依赖于人类输入的因果任务来说是一个巨大的胜利。通过捕捉关于因果机制的常识和领域知识,并支持自然语言与形式方法之间的转换,大语言模型为推进因果关系的研究、实践和采用开辟了新前沿。
1. 大语言模型与因果发现
-
成对因果发现
在成对因果发现任务中,GPT3.5/4 之类的大语言模型在涵盖物理学、工程学、医学和土壤科学的图宾根基准测试中,以超过 90% 的的准确率正确预测成对变量的因果方向(A是否导致B?),此前最高的准确率是83%。提示语使用变量名,并询问更可能的因果方向。
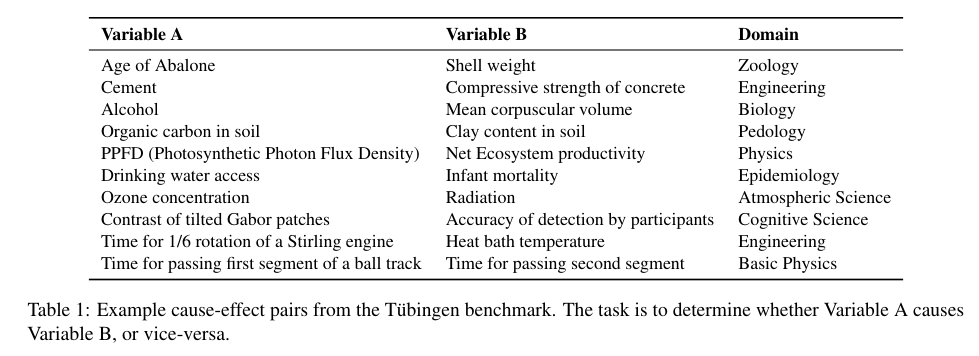
图2. 成对因果关系测试任务试图确定,变量A是否导致变量B,或者反之。
在关于神经性疼痛的专门医学数据集上,大语言模型也获得了类似的高准确率。在这种情况下,因果关系并不明显,然而 GPT-4 以96%的准确率检测到正确的因果方向。提示语的选择对结果有很大影响。
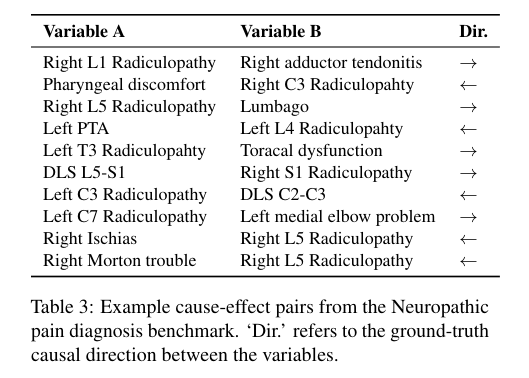
图3. 神经性疼痛诊断基准中的成对因果关系。
-
发现完整因果图
对于更困难的任务,发现完整的因果图,此前在医学数据集上的工作预测大语言模型无效,然而事实并非如此。通过简单的提示调整,测试分数迅速从0.1上升至0.7。在一个北极科学数据集上,GPT-4 超越了最近的深度学习方法。当然,大语言模型也会犯一些愚蠢的错误(例如回答鲍鱼的长度决定了其年龄),所以在关键应用上仍然难以信任。但结果令人惊讶的地方在于,在涵盖广泛人类知识的数据集上,这类错误是如此之少。
这对因果推理具有重要意义。构建因果图可能是因果分析中最具挑战性的部分。这些结果表明,我们可以不再依赖人类提供完整的因果图,而可以使用大语言模型来生成候选因果图或帮助评估。

图4. 大语言模型检测因果方向的推理过程。左侧的因果推理过程给出了正确答案:鲍鱼的年龄导致了其长度;右侧的例子需要同样的因果知识,但大语言模型的论证不连贯,给出了错误答案。
2. 大语言模型用于现实因果推理
-
反事实推理
论文的第二部分关注反事实推理。大语言模型能否从自然语言中推断因果关系?
例如:一个女人看到了火。如果女人触摸了火,会发生什么?
对于实际因果关系,由于人类需要判断相关变量及其因果贡献,这是一个非常具有挑战性的任务。GPT3.5/4 在这方面优于现有算法。在预测日常反事实情况结果的 CRASS 基准测试中,GPT-4 获得 92% 的准确率,比之前的最好结果高出 20%。
-
推断必要和充分原因
接下来,大语言模型能否推断必要和充分原因?研究中考虑了15个具有挑战性的实际因果事件。GPT3.5 在这种情况下失效了,但 GPT4 仍然达到了86%的准确率。
-
推断是否符合社会规范
这些发现意味着大语言模型可以作为工具,直接从混乱的人类文本中进行因果归因。虽然大语言模型可以从文本中推断相关变量,但评估人类因素(例如,一个行动是否被认为合乎社会规范的?)对大语言模型来说仍然是艰难的任务。在需要算法匹配人类直觉的 Big Bench 因果判断任务上,GPT-3.5/4获得了较低的准确率。
3. 大语言模型推动因果推理的新前沿
总体而言,大语言模型为因果推理带来了新的能力,与现有方法相辅相成。我们看到了因果推理充满前景的未来,大语言模型可以协助和自动化因果推理的各个步骤,在基于知识的因果推理和基于数据的因果推理之间无缝转变。
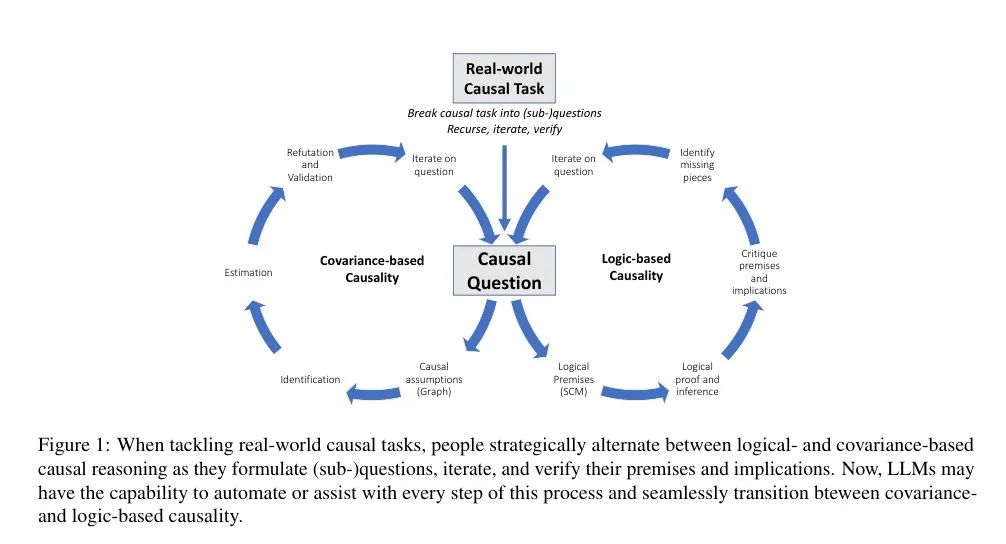
图5. 在处理现实世界因果任务时,人类会在基于逻辑的因果推理和基于协变的因果推理之间转换。现在,大语言模型能够协助和自动化因果推理的每一个步骤,帮助实现协变与逻辑因果推理的统一。
大语言模型并不完美,具有不可预测的失效模式。鲁棒性检测表明存在记忆的因果关系,这部分解释了大语言模型的表现。因此,我们仍然需要原理性的因果算法,不过大语言模型可以用来扩展其范围和能力。
展望未来,这项工作提出了更多问题而非给出答案。大语言模型如何帮助重新发明或增强现有的因果任务,如何让大语言模型的推理更加鲁棒,是许多研究关注的问题。
AI+Science 读书会
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣,共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。读书会从2023年3月26日开始,每周日早上 9:00-11:00 线上举行,持续时间预计10周。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。

详情请见:
人工智能和科学发现相互赋能的新范式:AI+Science 读书会启动
因果表征学习读书会
随着“因果革命”在人工智能与大数据领域徐徐展开,作为连接因果科学与深度学习桥梁的因果表征学习,成为备受关注的前沿方向。以往的深度表征学习在数据降维中保留信息并过滤噪音,新兴的因果科学则形成了因果推理与发现的一系列方法。随着二者结合,因果表征学习有望催生更强大的新一代AI。集智俱乐部组织以“因果表征学习”为主题、为期十周的读书会,聚焦因果科学相关问题,共学共研相关文献。欢迎从事因果科学、人工智能与复杂系统等相关研究领域,或对因果表征学习的理论与应用感兴趣的各界朋友报名参与。

详情请见:
连接因果科学与深度学习的桥梁:因果表征学习读书会启动
这篇关于区别探索:掩码语言模型 (MLM) 和因果语言模型 (CLM)的区别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






