本文主要是介绍跟着Datawhale打一场时序比赛(SEED新能源赛道-电动汽车充电站充电需求预测)之打卡笔记一,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近Datawhale又开始组织打比赛的培训学习了,很早就认识了这个专业的学习组织,跟着他们也学过不少竞赛知识,但是还没完全打完过一场赛事;所以这次打算跟着Datawhale打这场时序的比赛 —>
2023“SEED”第四届江苏大数据开发与应用大赛–新能源赛道。
1. 赛事学习流程
首先看这张学习计划图表:

时间还比较充足,任务安排也很合理,学习难度逐步加深。今天刚刚完成了第一个任务:跑通baseline,下面谈谈自己对这个baseline的理解。
2.baseline理解
这个baseline其实很简单,整个代码量不到两百行,主打一个快速上手。
2.1 数据探索
首先是在数据探索这一块,baseline只针对power数据集的power(充电量)这一列进行了一个时序的可视化探索,得到下面五个趋势图。
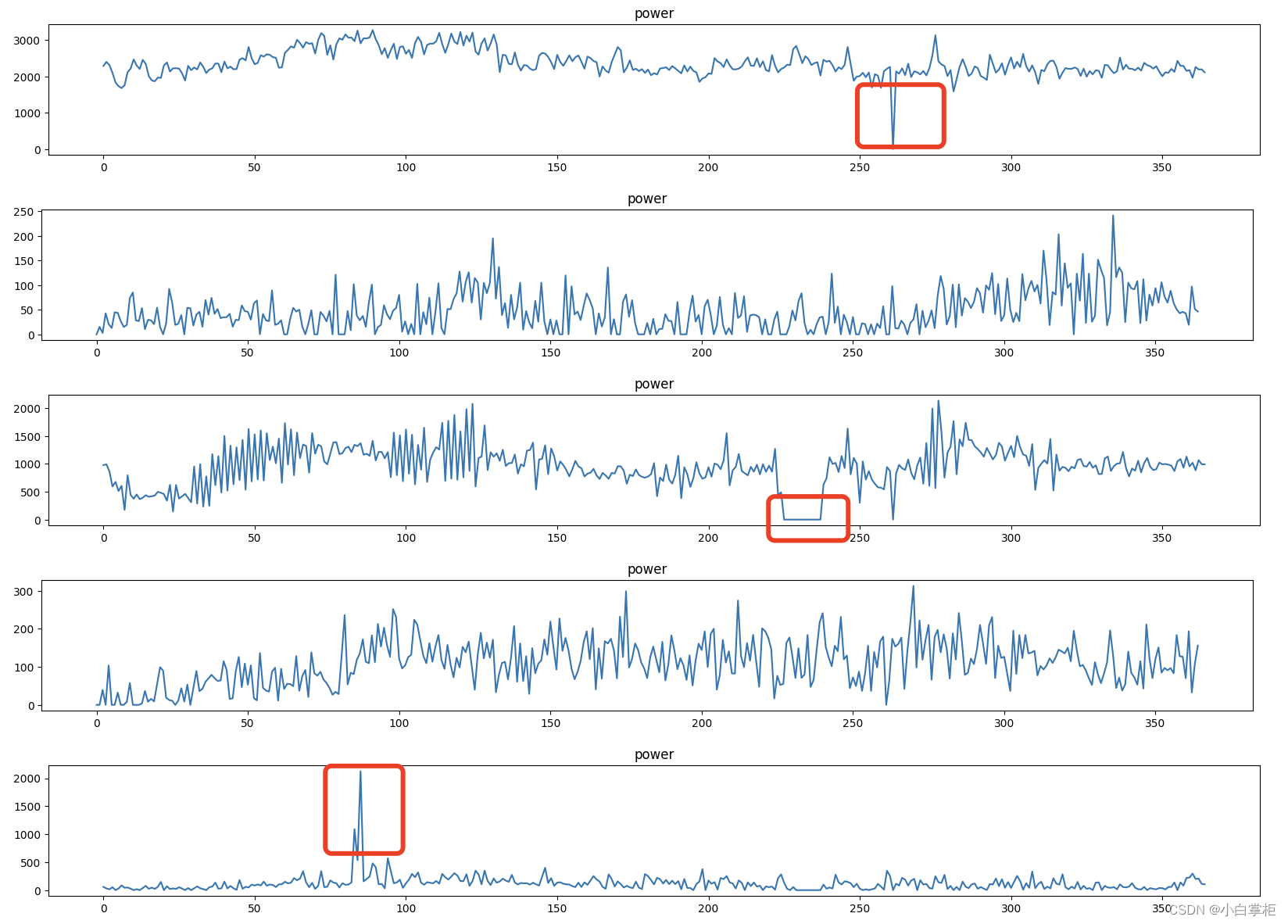
五个趋势图分别表示0到4这五个站点编码一年的用电量情况(个人建议这里的时序图最好在标题上做个区分以及给出横纵坐标的含义,不然可能会有同学不清楚到底是哪些站点编码被探索过。)
- 很明显这五个站点的用电量存在一些异常值的情况,比如0号站点、2号站点和4号站点。
- 其次,0号站点一整年的用量都很高,除开异常值那部分,几乎都在1500以上。
- 接着,1、2、3号站点的用电量趋势有一定的相似性,是否后面构建特征的时候可以一并处理?
- 然后,4号站点整年的用电量(除开异常值部分)都很低,(个人大胆猜测)是否4号站点的样本数据后面可以删除处理?
以上都是根据baseline里面数据探索得出的思考方向,或许后面模型优化的时候可以把其他站点的历史用电量也打印出来一并观察处理。
2.2 数据清洗
baseline的数据清洗只对站点的静态数据集这里面的flag列(即“场站标签”)进行了一个类别的转化处理,方便后面模型的训练。
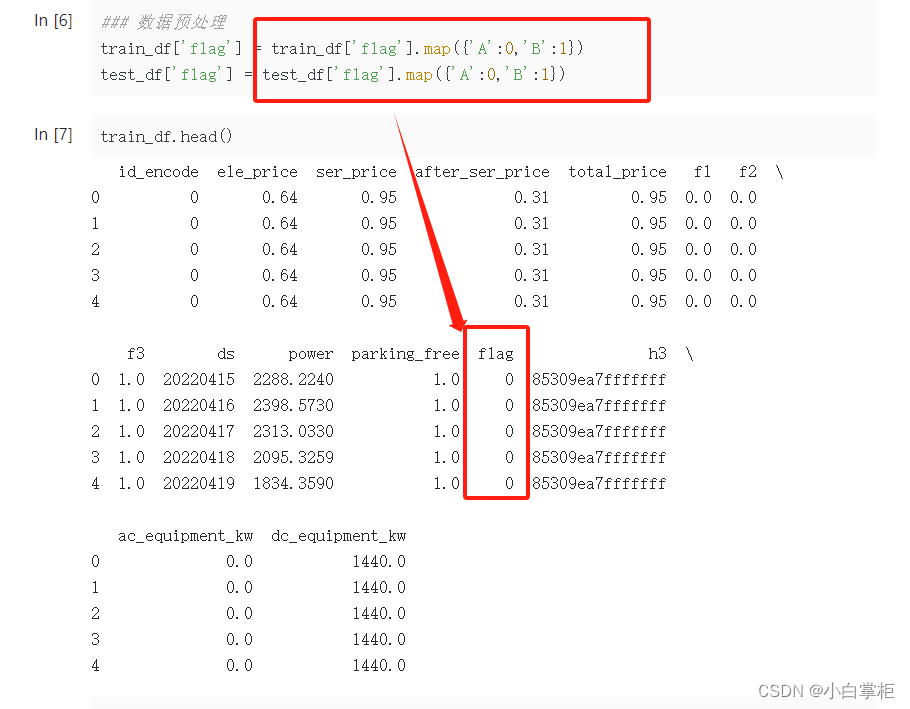
这个很好理解,所以没什么好说的。看官方给出教程说后续会进行更细致的数据清洗工作(比如异常值处理、数据分箱、归一化等),期待。
2.3 特征工程
这里baseline直接对日期(即ds)这个特征进行了一个基本的时间特征构建,分别按照年、月、日、周、是否周末、季度、是否月初以及是否月末这些维度展开。算是一个比较简单的特征工程,也是为了让大家能更好上手比赛,所以没做很复杂的特征工程。想要构建更复杂的特征,根据官网给出的提示,还可以对h3这个特征进行额外的特征构造。

当然,后续特征工程也可以对第一个数据集(站点运营数据)进行尝试,但特征是否对模型有优化作用就有待观察了。
2.4 模型训练和验证
baseline这里它采用的训练模型是lightGBM,并使用了5折交叉验证的评估方法。
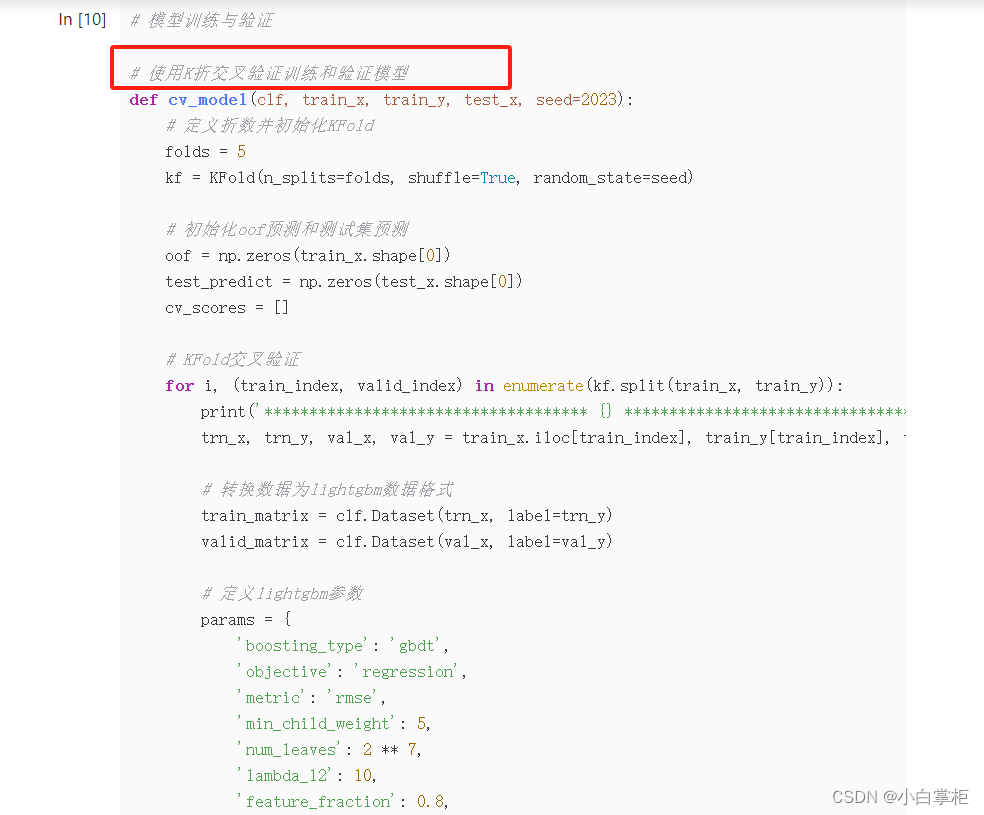
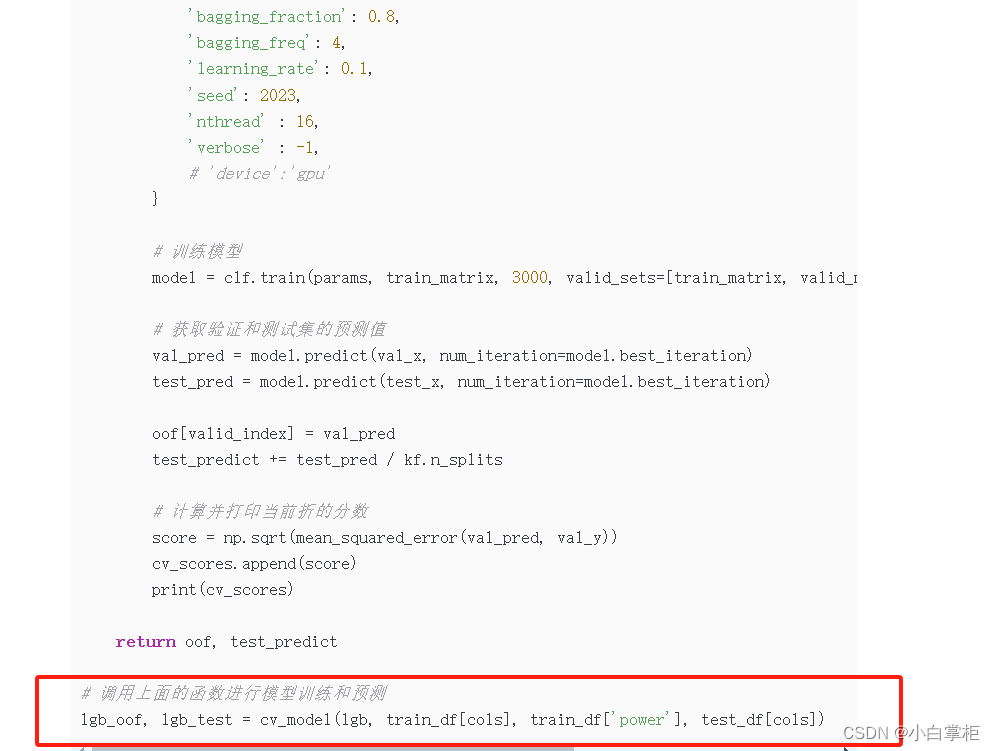
看过他家蛮多baseline,发现他们挺喜欢在baseline里面采用lightGBM模型和5折交叉验证作为初始模型训练的方法。个人猜测他们之所以用lightGBM作为初始模型,可能是因为这个模型高性能且轻便,易于运行、还能直接处理类别特征等因素。简单来说,这个模型有很好的鲁棒性,所以他家才总是在baseline里面采用。而用5折交叉验证的评估方法是因为它除了能评估模型的性能,检查模型的泛化能力外,还能减少因数据集的划分方式不同而引起的偶然性。
当然后续肯定可以用其他模型来进行优化,但是效果如何还需进一步去验证。
2.5 模型预测结果+后续思考
最后的预测很简单,直接把训练好的模型放入测试集进行预测,结果还行,RMSE的值在243左右。

因为此次比赛采用的评估指标是RMSE,那么后续如果想要更低的RMSE值,个人觉得对异常值的处理会是一个比较重要的方向。其次是时间特征构建这里,或许可以尝试进行一阶差分、滑动窗口等方法。
以上就是对本次baseline学习的一个打卡记录,期待后续更加深入的学习,也欢迎有兴趣的朋友一起打卡探讨。
参考资料:
SEED江苏大数据大赛-新能源赛道学习手册
竞赛实践路线分享
数据竞赛入门讲义
手把手带打一场时间序列实践
这篇关于跟着Datawhale打一场时序比赛(SEED新能源赛道-电动汽车充电站充电需求预测)之打卡笔记一的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








