本文主要是介绍基于双级阈值及过零率的语音激活检测(VAD),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
语音激活检测(Voice Activity Detection, VAD):也称为端点检测,目的就是要找到音频信号的开始和结束位置。
时域方法:
- 音量:只用音量来进行端点检测,是最简单的方法,但是会对清音造成误判。
- 音量和过零率:以音量为主,过零率为辅,可以对清音进行较准确的检测。
这里介绍第二种方法,结合音量和过零率的语音激活检测方法:
- 以高阈值tu为标准,决定端点,作为初始端点;
- 将端点前后延伸到低阈值tl处(如下图N1、N2点);
- 再将端点前后延伸到过零率(tzc)处,以包含语音中的清音部分。

图中 tl 的范围是完全包含了 tu 的范围。为什么还需要第一步,因为仅仅用第2步的话,噪音的部分会被计算进来。
结合过零率找到 SUV 来做端点检测,基于如下的特征:浊音 ZCR < 静音 ZCR < 清音 ZCR。
import librosa
import matplotlib.pyplot as plt
import numpy as np
import soundfile as sf# 加载数据
file_path = 'test1.wav'
y, fs = librosa.load(file_path, sr=8000, mono=False)
if len(y) == 2:y = y[0, :]# 分帧:每帧数据、每帧最大值、每帧幅度
frame_length = 160
hop_length = 80
frame_datas = []
frame_maxs = []
frame_amps = []
frame_zcrs = []
for i in range(0, len(y) - frame_length, hop_length):frame_data = y[i: i + frame_length] - np.mean(y[i: i + frame_length])frame_max = np.max(frame_data)frame_amp = np.sum(np.abs(frame_data))frame_datas.append(frame_data)frame_maxs.append(frame_max)frame_amps.append(frame_amp)# 过门限率
door_th = np.abs(np.min(frame_maxs)) * 2
for i in range(len(frame_datas)):frame_data = frame_datas[i]frame_data = frame_data - door_thframe_zcr = np.sum(np.abs([np.sign(frame_data[j]) - np.sign(frame_data[j + 1]) for j in range(len(frame_data) - 1)])) / 2frame_zcrs.append(frame_zcr)# 基于双级阈值及过零率的语音激活检测(VAD)
th = np.max(frame_amps) * 0.1
tl = np.max(frame_amps) * 0.05
th_zcr = np.max(frame_zcrs) * 0.2
th_pairs = []
temp = np.argwhere(frame_amps > th).squeeze()
stop_flag = 1
start = 0
stop = 0
for i in range(len(temp) - 1):if stop_flag == 1:start = temp[i]stop_flag = 0elif abs(temp[i] - temp[i - 1]) == 1 and (abs(temp[i] - temp[i + 1]) > 1 or i + 1 == len(temp) - 1) :stop = temp[i]stop_flag = 1th_pairs.append([start, stop])
dst_data = np.zeros_like(y)
for i in range(len(th_pairs)):start = th_pairs[i][0]stop = th_pairs[i][1]for i in range(start, 0, -1):if frame_amps[i] < tl:start_1 = ibreakfor i in range(stop, len(frame_amps), 1):if frame_amps[i] < tl:stop_1 = ibreakfor i in range(start_1, 0, -1):if frame_zcrs[i] < th_zcr:start_2 = ibreakfor i in range(stop_1, len(frame_zcrs), 1):if frame_zcrs[i] < th_zcr:stop_2 = ibreakdst_data[hop_length * start_2: hop_length * stop_2 + frame_length] = \y[hop_length * start_2: hop_length * stop_2 + frame_length]# sf.write('dst_data2.wav', dst_data, fs)
plt.subplot(4, 1, 1)
plt.plot(y)
plt.subplot(4, 1, 2)
print(len([i for i in range(0, len(y) - frame_length, hop_length)]), len(frame_amps))
plt.plot([i for i in range(0, len(y) - frame_length, hop_length)], frame_amps)
plt.subplot(4, 1, 3)
plt.plot([i for i in range(0, len(y) - frame_length, hop_length)], frame_zcrs)
plt.subplot(4, 1, 4)
plt.plot(dst_data)
plt.show()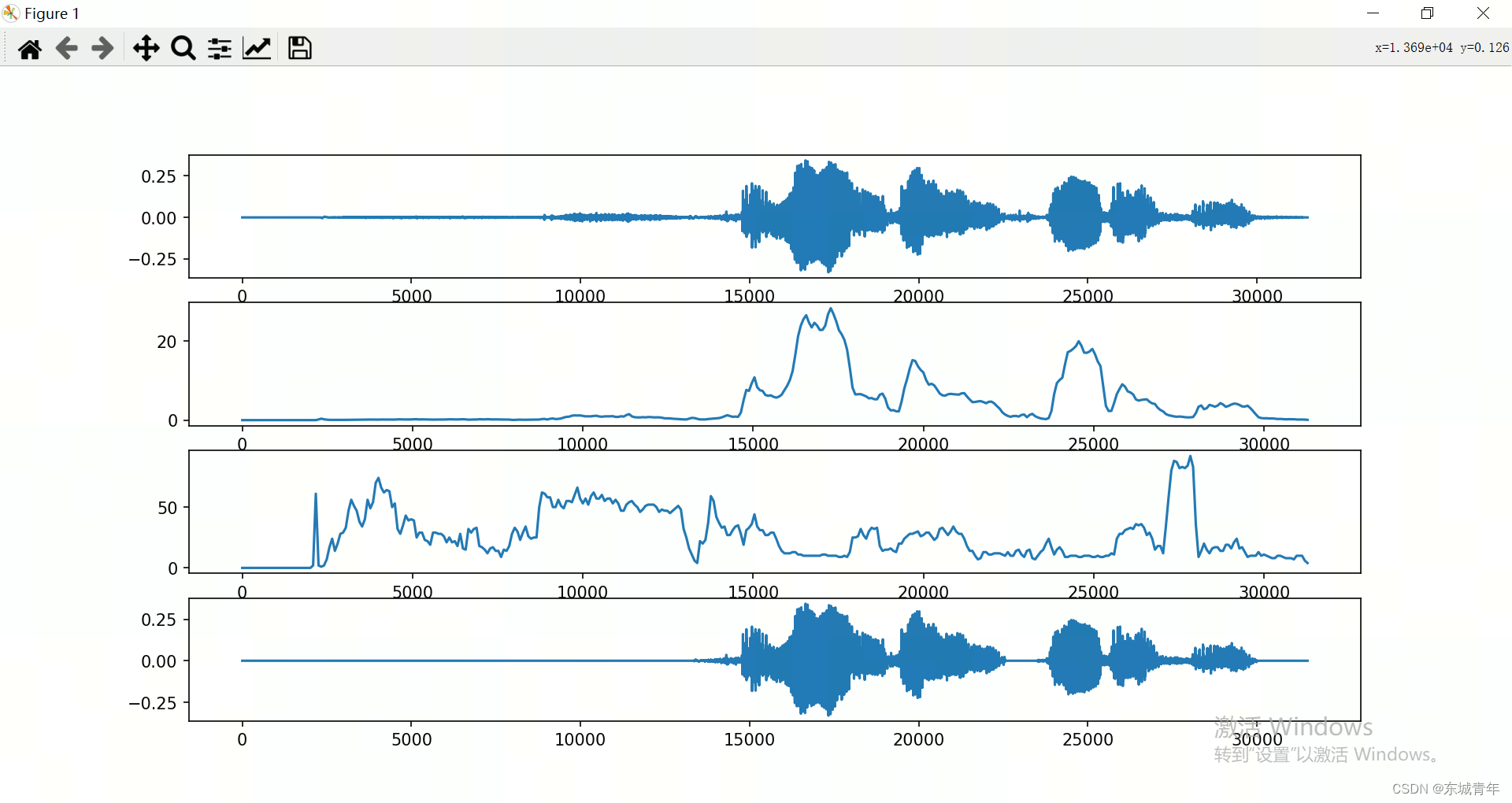
参考: 语音处理/语音识别基础(六)- 语音的端点检测(EPD/VAD)
这篇关于基于双级阈值及过零率的语音激活检测(VAD)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







