vad专题

解密FSMN-Monophone VAD模型:语音活动检测的未来
在现代语音处理领域,语音活动检测(Voice Activity Detection, VAD)是一个关键技术,广泛应用于语音识别、语音编码和语音增强等任务。随着深度学习的快速发展,传统的VAD方法逐渐被更为先进的模型所取代。本文将深入探讨FSMN-Monophone VAD模型的原理、优势及其实际应用案例,帮助读者更好地理解这一前沿技术。 一、什么是FSMN-Monophone VAD? FS
pyaudio webrtcvad实现实时录制语音加VAD检测没人说话自动停止录制
vad检测没人说话超过2秒就自动停止录制并保存前面有人说话的音频文件 pip install webrtcvad 代码: import pyaudioimport waveimport timeimport webrtcvadCHUNK = 320 # 20ms 的语音帧FORMAT = pyaudio.paInt16CHANNELS = 1RATE = 16000WA
{“sn“:““,“error“:3,“desc“:“VAD is not available“,“sub_error“:3100}解决办法
目录 问题描述: 解决顺序: 问题描述: 这个问题是在使用百度语音识别时出现的问题,当一切都配置好之后,启动程序,点击录音,发现程序并没有执行onEvent方法,直接闪退了,当断点调试时发现程序并没有进入onEvent方法,抛出异常{"sn":"","error":3,"desc":"VAD is not available","sub_error":3100},情况见下图: 解


语音端点检测(voice activity detection VAD)综述+论文百篇(195*~2019)
能量 短时过零率 自相关 pitch G.729B AMR opt 1/2 深度学习 bDNN 基于听觉机制 Method Feature Concept Work Environment G.729B VAD [6, 24] linear spectrum frequency, zero crossing rate, full band signal energy,
![将音频分割为60s内的短文件[Cygwin; speech-vad-demo]](https://img-blog.csdnimg.cn/2019121209534828.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0dyZWF0WGlhbmc4ODg=,size_16,color_FFFFFF,t_70)
将音频分割为60s内的短文件[Cygwin; speech-vad-demo]
安装Cygwin和打开 Windows 安装 cygwin,及cygwin 中 下载cmake make gcc g++等编译软件 安装后,打开cygwin软件,进入相应目录E:\Program_Files\Cygwin\home\ASUS\speech-vad-demo 其中,E:\Program_Files\Cygwin是我安装Cygwin的位置,ASUS是我主机名称,speech-vad-
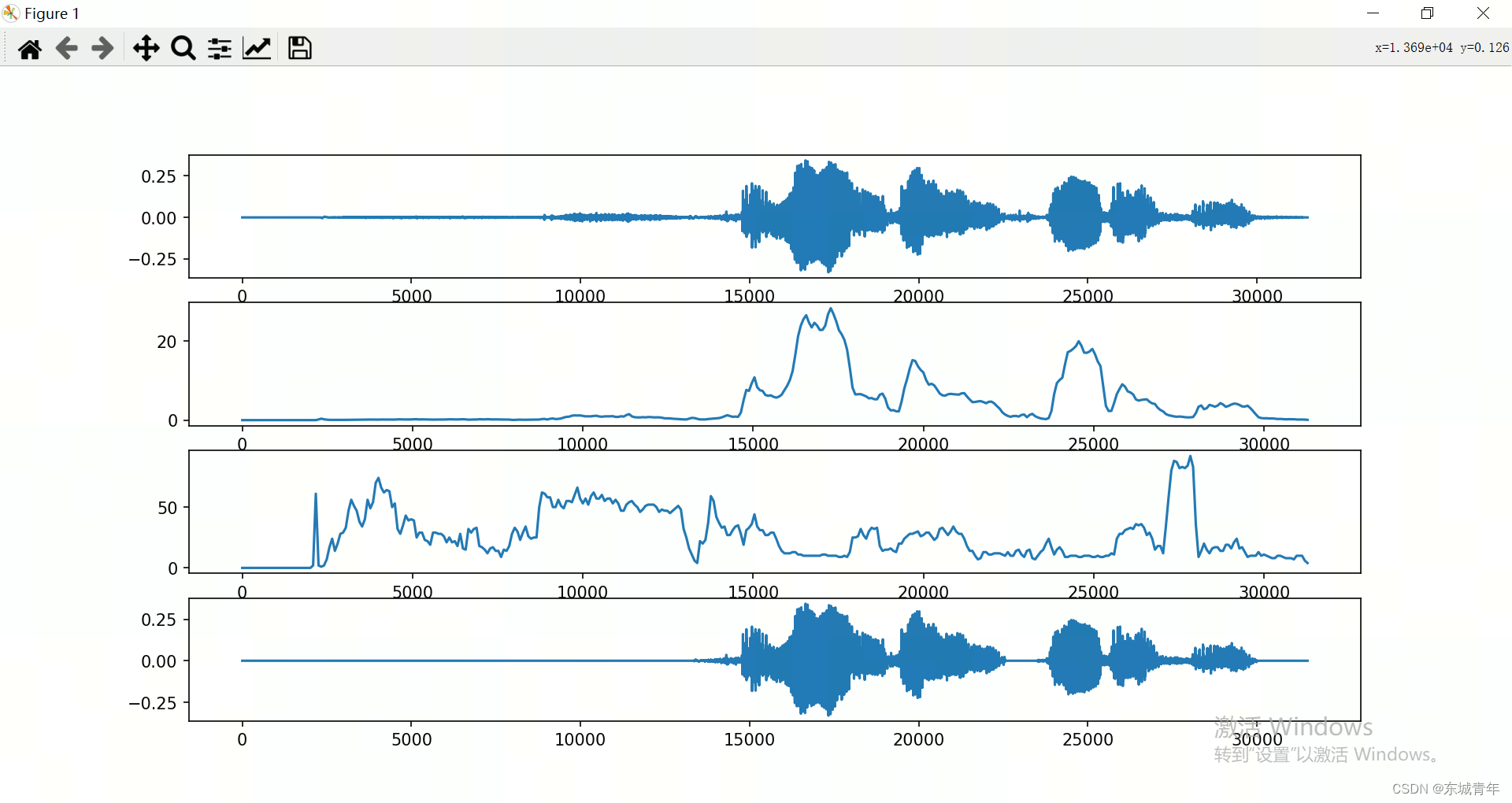
基于双级阈值及过零率的语音激活检测(VAD)
语音激活检测(Voice Activity Detection, VAD):也称为端点检测,目的就是要找到音频信号的开始和结束位置。 时域方法: 音量:只用音量来进行端点检测,是最简单的方法,但是会对清音造成误判。音量和过零率:以音量为主,过零率为辅,可以对清音进行较准确的检测。 这里介绍第二种方法,结合音量和过零率的语音激活检测方法: 以高阈值tu为标准,决定端点,作为初始端点;将端点