本文主要是介绍Hadoop3教程(五):NameNode和SecondaryNameNode,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- (59)NN和2NN的工作机制
- (60)FsImage镜像文件
- (61)Edits编辑日志
- (62)Checkpoint时间设置
- 参考文献
(59)NN和2NN的工作机制
NameNode的数据是存储在磁盘中,还是在内存中?
内存:计算快,但可靠差,节点崩了就全丢了;
磁盘:可靠性高,但是计算慢(因为需要频繁的IO交互);
内存+磁盘:内存计算完后就持久化到磁盘,可靠性提高了,计算也相对较快了,但其实相比全内存,还是会慢一些(毕竟还是有频繁IO交互);
目前NN的机制是,内存中维护一套数据,然后磁盘上维护两个文件,fsImage负责存储数据的值,Edits负责记录对数据的操作记录,且fsImage + Edits = 内存中的数据。
fsImage:存储数据
Edits:只记录追加,不修改原始地址,类似日志,只记录操作;
服务器启动的时候,就会将fsImage + Edits 的数据加载到内存。
服务器关闭的时候,就把Edits的数据加载到fsImage中(保证fsImage中是最完全的)。
但只在关闭的时候做刷新,也不行,太危险,而且会导致关机时间变长,因此最好的方式是每隔一段时间,就用Edits去刷一下fsImage中的值,这部分就是2NN负责的(定期进行合并)。
这两个文件在集群的data/dfs/name/current/下。
NameNode的完整流程如图:
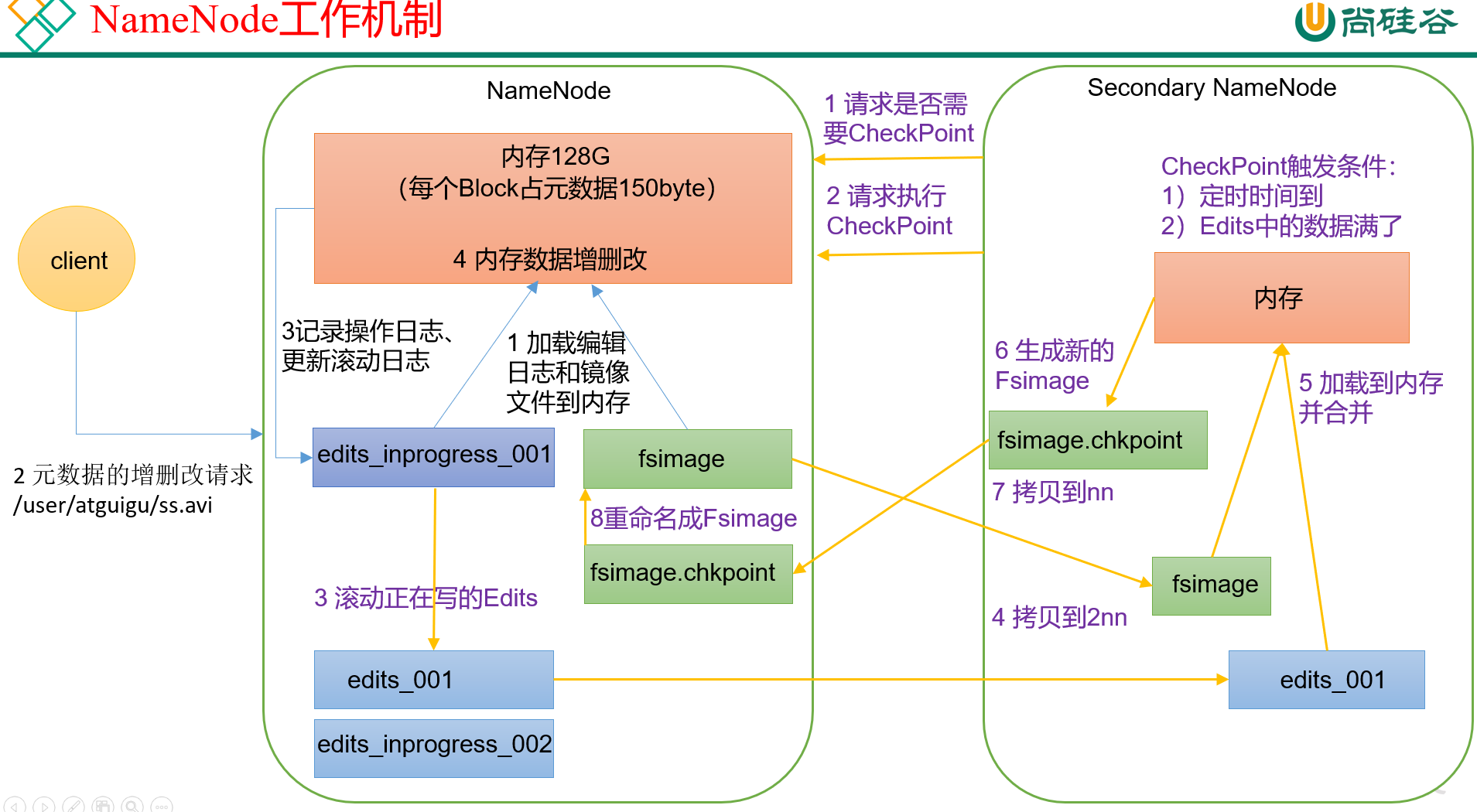
对NameNode来讲,主要是执行以下几步:
- 开机,加载fsImage镜像文件和Edits编辑文件进内存(如果NameNode是第一次启动,则是新建这两个文件);
- client发送增删改请求;
- Edits编辑文件,负责记录数据的增删改日志,然后再发送请求,修改内存中的对应值
- 内存开始对应的增删改;
2NN工作流程:
2NN会周期性被触发,去问NN是否需要合并数据做checkpoint。
触发条件有两个:
- 定时时间到(默认时间是1h);
- Edits文件中的数据满了(一般是1百万条,防止数据过多,合并时效率会慢);
2NN在请求执行checkpoint操作时:
- 滚动正在写的Edits。如果当前在写的Edits文件叫做
edits_inprogress_001,那么NN会将其命名为edits_001,同时新建edits_inprogress_002,之后client过来的增删改请求,会由新的edits_inprogress_002来记录; - 将上一步中的
edits_001和fsIamge镜像文件复制到2NN,两者合并加载到内存。 - 上一步后,会在2NN中生成一个新的fsImage,被命名为
fsImage.chkpoint; - 把得到的
fsImage.chkpoint文件拷贝回NN目录下,并重命名,覆盖原先的fsImage。
因此,2NN和NN之间的文件差异,就在于NN会有一个edits_inprogress_xxx的文件,而2NN中只有edits_xxx这样的文件。
(60)FsImage镜像文件
NameNode被格式化之后,会在/opt/module/hadoop-3.13/data/tmp/dfs/name/current目录中产生如下文件:
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
- fsimage:是HDFS文件系统元数据的一个永久性的检查点,包含HDFS文件系统的所有目录和iNode的序列化信息等;
- Edits:存放HDFS文件系统的所有增删改操作。所有写操作会首先被记录在Edits文件里,而不是先直接操作内存;
- seen_txid:保存的是一个数字,代表最新fsimage文件后缀的数字;
- VERSION:保存集群ID等信息;
如何查看FsImage镜像文件里的内容呢?
常规方式不可以,可以通过HDFS指令来把镜像文件转成常规格式的文件,以此来查看:
hdfs oiv -p 文件类型 -i 镜像文件地址 -o 转换后文件的输出路径
如:
hdfs oiv -p XML -i /opt/module/hadoop-3.13/data/tmp/dfs/name/current/fsimage_0000000000000000234 -o /opt/software/fsimage.xml
就是把指定的fsImage文件,输出成常规的xml文件,然后cat输出的xml文件就可以查看内容。
fsImage文件里都放了什么内容?
如HDFS的目录结构,在HDFS中,无论是文件还是目录,都被视为是一个inode节点。通过每个iNode的parent和child的依赖关系,镜像文件里以树形结构维护着整个HDFS的目录结构等信息。
NameNode里面如何记录块信息呢?
事实上,NameNode里并不会主动记录,哪个文件块存储在哪个DataNode上,而是每次通电后,DataNode们会主动向NameNode汇报,我这里存了哪些文件块。
所以FsImage镜像文件里,只会记录HDFS的目录信息,而不会记录文件块存储在哪些DataNode上,估计这种信息是维护在内存里的?
(61)Edits编辑日志
查看Edits编辑日志文件:
hdfs oev -p 文件类型 -o 转换后文件的输出路径
打开文件会看到,Edits是由一个一个组成的,每次增删改操作都会在文件后追加生成一个。
那么在合并Edits的时候,应该合并哪个或者哪些Edits呢?
如果当前的fsImage后缀到了355,那么就合并Edits后缀大于355的,如356,357等。
因为fsImage后缀到了355之后,就证明Edits的355及之前的已经合并完了,没啥用了。
(62)Checkpoint时间设置
是指2NN多久时间,会联系NN去合并镜像文件和编辑日志。
之前说过,2NN在触发指定条件后,就会去NN那儿合并文件,触发条件有两个:
- 定时时间到(默认时间是1h);
- Edits文件中的数据满了(一般是1百万条,防止数据过多,合并时效率会慢);
关于定时时间,默认是3600s,即1H,关于默认情况的时间设置是在hdfs-default.xml中,搜索dfs.namenode.checkpoint.period,value就是checkpoint的时间。
如果Edits里面的操作数满了,也会触发合并。这个默认的操作数是一百万次,且每隔1min检查一次。
同样的,也是在hdfs-default.xml中搜索设置。
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value>
<description>操作动作次数</description>
</property><property><name>dfs.namenode.checkpoint.check.period</name><value>60s</value>
<description> 1分钟检查一次操作次数</description>
</property>
注意:在企业生产中,我们一般也用不上这些参数,因为正常情况下,企业会搭建NameNode的高可用,所以就用不到2NN。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
这篇关于Hadoop3教程(五):NameNode和SecondaryNameNode的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







