本文主要是介绍Deep Learning for Hate Speech Detection in Tweets,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习使用,如有侵权联系我删除哦~
Deep Learning for Hate Speech Detection in Tweets
摘要(ABSTRACT)
Hate speech detection on Twitter is critical for applications like controversial event extraction, building AI chatterbots, content recommendation, and sentiment analysis. We define this task as being able to classify a tweet as racist, sexist or neither. The complexity of the natural language constructs makes this task very challenging. We perform extensive experiments with multiple deep learning architectures to learn semantic word embeddings to handle this complexity. Our experiments on a benchmark dataset of 16K annotated tweets show that such deep learning methods outperform state-of-the-art char/word n-gram methods by ∼18 F1 points.
Twitter 上的暴力言论检测对于有争议的事件提取、构建 AI 聊天机器人、内容推荐和情绪分析等应用至关重要。我们将这项任务定义为能够将推文分类为种族主义、性别歧视或两者都不是。自然语言结构的复杂性使这项任务非常具有挑战性。我们对多种深度学习架构进行了广泛的实验,以学习语义词嵌入来处理这种复杂性。我们在 16K 条带注释推文的基准数据集上进行的实验表明,这种深度学习方法比最先进的 char/word n-gram 方法要好 18 个 F1 点。
1、简介(INTRODUCTION)
With the massive increase in social interactions on online social networks, there has also been an increase of hateful activities that exploit such infrastructure. On Twitter, hateful tweets are those that contain abusive speech targeting individuals (cyber-bullying, a politician, a celebrity, a product) or particular groups (a country, LGBT, a religion, gender, an organization, etc.). Detecting such hateful speech is important for analyzing public sentiment of a group of users towards another group, and for discouraging associated wrongful activities. It is also useful to filter tweets before content recommendation, or learning AI chatterbots from tweets1.
随着在线社交网络上社交互动的大量增加,利用此类基础设施的暴力活动也有所增加。在 Twitter 上,暴力推文包含针对个人(网络欺凌、政治家、名人、产品)或特定群体(国家、LGBT、宗教、性别、组织等)的辱骂性言论。检测这种仇恨言论对于分析一组用户对另一组的公众情绪以及阻止相关的不法活动非常重要。在内容推荐之前过滤推文或从推文中学习 AI 聊天机器人也很有用。
The manual way of filtering out hateful tweets is not scalable, motivating researchers to identify automated ways. In this work, we focus on the problem of classifying a tweet as racist, sexist or neither. The task is quite challenging due to the inherent complexity of the natural language constructs – different forms of hatred, different kinds of targets, different ways of representing the same meaning. Most of the earlier work revolves either around manual feature extraction [6] or use representation learning methods followed by a linear classifier [1, 4].
过滤暴力推文的手动方式不可扩展,促使研究人员识别自动化方式。在这项工作中,我们专注于将推文分类为种族主义、性别歧视或两者都不是的问题。由于自然语言结构固有的复杂性——不同形式的仇恨、不同类型的目标、不同的表达相同含义的方式,这项任务非常具有挑战性。大多数早期的工作要么围绕手动特征提取[6],要么使用表示学习方法,然后使用线性分类器[1、4]。
However, recently deep learning methods have shown accuracy improvements across a large number of complex problems in speech, vision and text applications. To the best of our knowledge, we are the first to experi-ment with deep learning architectures for the hate speech
detection task.
然而,最近深度学习方法在语音、视觉和文本应用中的大量复杂问题上显示出准确性的提高。据我们所知,我们是第一个将深度学习架构用于暴力言论检测任务的人。
In this paper, we experiment with multiple classifiers such as Logistic Regression, Random Forest, SVMs, Gradient Boosted Decision Trees (GBDTs) and Deep Neural Networks(DNNs). The feature spaces for these classifiers are in turn defined by task-specific embeddings learned using three deep learning architectures: FastText, Convolutional Neural Networks (CNNs), Long Short-Term Memory Networks (LSTMs). As baselines, we compare with feature spaces comprising of char n-grams [6], TF-IDF vectors, and Bag of Words vectors (BoWV).
在本文中,我们试验了多种分类器,如逻辑回归、随机森林、SVMs、梯度提升决策树(GBDTs)和深度神经网络(DNNs)。这些分类器的特征空间又由使用三种深度学习架构学习的特定任务嵌入来定义。FastText、卷积神经网络(CNNs)、长短期记忆网络(LSTMs)。作为基线,我们与由char n-grams[6]、TF-IDF向量和Bag of Words向量(BoWV)组成的特征空间进行比较。
Main contributions of our paper are as follows: (1) We investigate the application of deep learning methods for the task of hate speech detection. (2) We explore various tweet semantic embeddings like char n-grams, word Term FrequencyInverse Document Frequency (TF-IDF) values, Bag of Words Vectors (BoWV) over Global Vectors for Word Representation (GloVe), and task-specific embeddings learned using FastText, CNNs and LSTMs. (3) Our methods beat stateof-the-art methods by a large margin (∼18 F1 points better)
我们论文的主要贡献如下。
(1) 我们研究了深度学习方法在暴力言论检测任务中的应用。
(2) 我们探索各种推文语义嵌入,如 char n-gram、单词词频逆文档频率 (TF-IDF) 值、词袋向量 (BoWV) 与用于词表示的全局向量 (GloVe) 以及特定任务的嵌入学习使用 FastText、CNN 和 LSTM。
(3) 我们的方法以很大的优势击败了先进的方法(比F1好18个点)。
2、method(PROPOSED APPROACH)
We first discuss a few baseline methods and then discuss the proposed approach. In all these methods, an embedding is generated for a tweet and is used as its feature representation with a classifier.
我们首先讨论一些基线方法,然后讨论提出的方法。在所有这些方法中,都会为推文生成嵌入,并将其用作分类器的特征表示。
Baseline Methods: As baselines, we experiment with three broad representations. (1) Char n-grams: It is the state-ofthe-art method [6] which uses character n-grams for hate speech detection. (2) TF-IDF: TF-IDF are typical features used for text classification. (3) BoWV: Bag of Words Vector approach uses the average of the word (GloVe) embeddings to represent a sentence. We experiment with multiple classifiers for both the TF-IDF and the BoWV approaches.
基线方法:作为基线,我们尝试了三种广泛的表示。
(1) n-gram:这是最先进的方法 ,它使用字符 n-gram 进行仇恨言论检测。
(2) TF-IDF:TF-IDF是用于文本分类的典型特征。
(3) BoWV: Bag of Words Vector 方法使用词(GloVe)嵌入的平均值来表示一个句子。
我们为 TF-IDF 和 BoWV 方法尝试了多个分类器。
Proposed Methods: We investigate three neural network architectures for the task, described as follows. For each of the three methods, we initialize the word embeddings with either random embeddings or GloVe embeddings. (1) CNN: Inspired by Kim et. al [3]’s work on using CNNs for sentiment classification, we leverage CNNs for hate speech detection. We use the same settings for the CNN as described in [3]. (2) LSTM: Unlike feed-forward neural networks, recurrent neural networks like LSTMs can use their internal memory to process arbitrary sequences of inputs. Hence, we use LSTMs to capture long range dependencies in tweets, which may play a role in hate speech detection.
更优的方法:我们研究了三种用于该任务的神经网络架构,如下所述。对于这三种方法中的每一种,我们使用随机嵌入或 GloVe 嵌入来初始化词嵌入。
(1) CNN:受 Kim 等人的启发在使用 CNN 进行情感分类的工作中,我们利用 CNN 进行仇恨言论检测。我们对 CNN 使用与 [3]中描述的相同的设置。
(2) LSTM:与前馈神经网络不同,像 LSTM 这样的循环神经网络可以使用其内部存储器来处理任意输入序列。因此,我们使用 LSTM 来捕获推文中的远程依赖关系,这可能在暴力言论检测中发挥作用。
(3) FastText: FastText [2] represents a document by average of word vectors similar to the BoWV model, but allows update of word vectors through Back-propagation during training as opposed to the static word representation in the BoWV model, allowing the model to fine-tune the word representations according to the task.
(3) FastText:FastText [2]通过词向量的平均值来表示一个文档,类似于BoWV模型,但允许在训练期间通过反向传播来更新词向量,而不是BoWV模型中的静态词表示,允许模型根据任务微调单词表示。
All of these networks are trained (fine-tuned) using labeled data with back-propagation. Once the network is learned, a new tweet is tested against the network which classifies it as racist, sexist or neither. Besides learning the network weights, these methods also learn task-specific word embeddings tuned towards the hate speech labels. Therefore, for each of the networks, we also experiment by using these embeddings as features and various other classifiers like SVMs and GBDTs as the learning method.
所有这些网络都使用带有反向传播的标记数据进行训练(微调)。一旦了解了网络,就会针对网络测试一条新推文,将其归类为种族主义者、性别歧视者或两者皆非。除了学习网络权重之外,这些方法还学习针对仇恨言论标签调整的特定任务词嵌入。因此,对于每个网络,我们还通过使用这些嵌入作为特征和各种其他分类器(如 SVM 和 GBDT)作为学习方法进行实验。
3、实验(EXPERIMENTS)
3.1 数据集和实验设置(Dataset and Experimental Settings)
We experimented with a dataset of 16K annotated tweets made available by the authors of [6]. Of the 16K tweets, 3383 are labeled as sexist, 1972 as racist, and the remaining are marked as neither sexist nor racist. For the embedding based methods, we used the GloVe [5] pre-trained word embeddings. GloVe embeddings(http://nlp.stanford.edu/projects/glove/) have been trained on a large tweet corpus (2B tweets, 27B tokens, 1.2M vocab, uncased). We experimented with multiple word embedding sizes for our task. We observed similar results with different sizes, and hence due to lack of space we report results using embedding size=200. We performed 10-Fold Cross Validation and calculated weighted macro precision, recall and F1-scores. We use ‘adam’ for CNN and LSTM, and ‘RMS-Prop’ for FastText as our optimizer. We perform training in batches of size 128 for CNN & LSTM and 64 for FastText. More details on the experimental setup can be found from our publicly available source code3.
我们用 [6] 的作者提供的 16K 注释推文数据集进行了实验。在 16K 条推文中,3383 条被标记为性别歧视者,1972 条被标记为种族主义者,其余的被标记为既不是性别歧视者也不是种族主义者。
对于基于嵌入的方法,我们使用了 GloVe [5] 预训练的词嵌入。 GloVe 嵌入 2 已在大型推文语料库(2B 推文、27B 标记、120 万词汇、无大小写)上进行了训练。我们为我们的任务尝试了多种词嵌入大小。我们观察到不同大小的类似结果,因此由于空间不足,我们使用嵌入大小=200 报告结果。
我们进行了 10 倍交叉验证并计算了加权宏观精度、召回率和 F1 分数。我们对 CNN 和 LSTM 使用“adam”,对 FastText 使用“RMS-Prop”作为我们的优化器。我们对 CNN 和 LSTM 以 128 的批量进行训练,对 FastText 进行 64 的训练。有关实验设置的更多详细信息,请参阅我们的公开源代码 。
3.2 结果与分析(Results and Analysis)
Table 1 shows the results of various methods on the hate speech detection task. Part A shows results for baseline methods. Parts B and C focus on the proposed methods where part B contains methods using neural networks only, while part C uses average of word embeddings learned by DNNs as features for GBDTs. We experimented with multiple classifiers but report results mostly for GBDTs only, due to lack of space
表 1 显示了各种方法在暴力言论检测任务上的结果。 A 部分显示了基线方法的结果。 B 部分和 C 部分侧重于优化的方法,其中 B 部分包含仅使用神经网络的方法,而 C 部分使用 DNN 学习的词嵌入的平均值作为 GBDT 的特征。我们尝试了多个分类器,但由于空间不足,主要只报告 GBDT 的结果。
Table 1: Comparison of Various Methods (Embedding Size=200 for GloVe as well as for Random Embedding)
表 1:各种方法的比较(GloVe 和随机嵌入的嵌入大小 = 200)
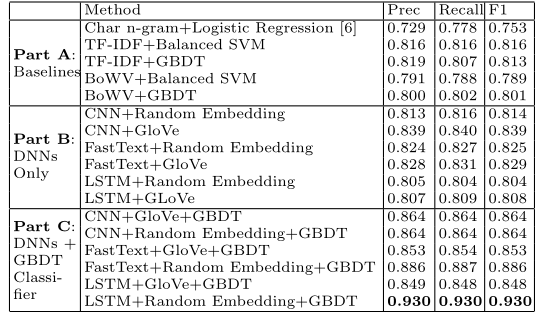
As the table shows, our proposed methods in part B are significantly better than the baseline methods in part A. Among the baseline methods, the word TF-IDF method is better than the character n-gram method. Among part B methods, CNN performed better than LSTM which was better than FastText. Surprisingly, initialization with random embeddings is slightly better than initialization with GloVe embeddings when used along with GBDT. Finally, part C methods are better than part B methods. The best method is “LSTM + Random Embedding + GBDT” where tweet embeddings were initialized to random vectors, LSTM was trained using back-propagation, and then learned embeddings were used to train a GBDT classifier. Combinations of CNN, LSTM, FastText embeddings as features for GBDTs did not lead to better results. Also note that the standard deviation for all these methods varies from 0.01 to 0.025.
如表所示,我们在 B 部分提出的方法明显优于 A 部分的基线方法。在基线方法中,单词 TF-IDF 方法优于字符 n-gram 方法。在 B 部分方法中,CNN 的表现优于 LSTM,LSTM 优于 FastText。令人惊讶的是,与 GBDT 一起使用时,随机嵌入的初始化比使用 GloVe 嵌入的初始化略好。最后,C 部分方法优于 B 部分方法。
最好的方法是“LSTM + Random Embedding + GBDT”,其中将推文嵌入初始化为随机向量,使用反向传播训练 LSTM,然后使用学习嵌入来训练 GBDT 分类器。 CNN、LSTM、FastText 嵌入作为 GBDT 的特征的组合并没有带来更好的结果。另请注意,所有这些方法的标准偏差从 0.01 到 0.025 不等。
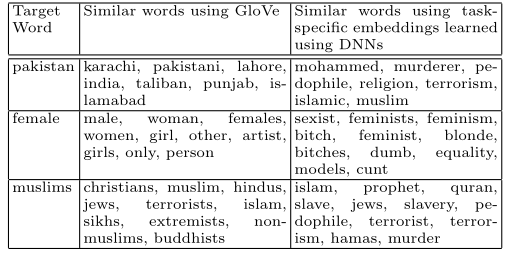
To verify the task-specific nature of the embeddings, we show top few similar words for a few chosen words in Table 2 using the original GloVe embeddings and also embeddings learned using DNNs. The similar words obtained using deep neural network learned embeddings clearly show the “hatred” towards the target words, which is in general not visible at all in similar words obtained using GloVe.
为了验证嵌入的特定任务性质,我们使用原始 GloVe 嵌入和使用 DNN 学习的嵌入在表 2 中显示了一些选定单词的前几个相似单词。使用深度神经网络学习嵌入获得的相似词清楚地显示了对目标词的“仇恨”,这在使用GloVe得到的相似词中一般是完全看不到的。
Table 2: Embeddings learned using DNNs clearly show the “racist” or “sexist” bias for various words.
表 2:使用 DNN 学习的嵌入清楚地显示了各种词的“种族主义”或“性别歧视”偏见。
4、结论(CONCLUTION)
In this paper, we investigated the application of deep neural network architectures for the task of hate speech detection. We found them to significantly outperform the existing methods. Embeddings learned from deep neural network models when combined with gradient boosted decision trees led to best accuracy values. In the future, we plan to explore the importance of the user network features for the task.
在本文中,我们研究了深度神经网络架构在仇恨言论检测任务中的应用。我们发现它们明显优于现有方法。从深度神经网络模型中学习到的嵌入与梯度增强决策树相结合会产生最佳准确度值。未来,我们计划探索用户网络特征对任务的重要性。
5、参考文献(REFERENCES)
[1] N. Djuric, J. Zhou, R. Morris, M. Grbovic, V. Radosavljevic, and N. Bhamidipati. Hate Speech Detection with Comment Embeddings. In WWW, pages 29–30, 2015.
[2] A. Joulin, E. Grave, P. Bojanowski, and T. Mikolov. Bag of Tricks for Efficient Text Classification. arXiv preprint arXiv:1607.01759, 2016.
[3] Y. Kim. Convolutional Neural Networks for Sentence Classification. In EMNLP, pages 1746–1751, 2014.
[4] C. Nobata, J. Tetreault, A. Thomas, Y. Mehdad, and Y. Chang. Abusive Language Detection in Online User Content. In WWW, pages 145–153, 2016.
[5] J. Pennington, R. Socher, and C. D. Manning. GloVe: Global Vectors for Word Representation. In EMNLP, volume 14, pages 1532–43, 2014.
[6] Z. Waseem and D. Hovy. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In NAACL-HLT, pages 88–93, 2016.
这篇关于Deep Learning for Hate Speech Detection in Tweets的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







