本文主要是介绍强化学习基于值6.2 | replay buffer经验回放,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
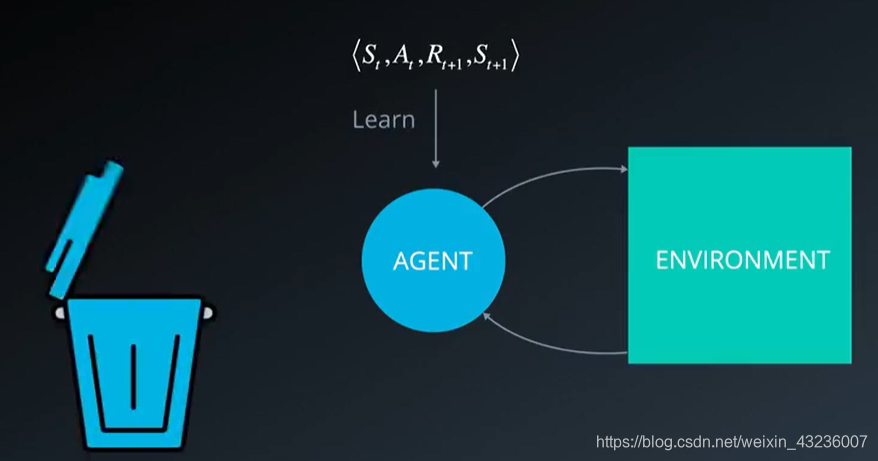
我们与环境进行互动并且在每个时间步,获得一个动作,状态,奖励,下个状态的元组,学完之后就丢弃,在下个时间步移到下个元组
我们将每个经验元组储存在这个缓冲区中,然后从中抽取一小批元组进行学习,因此我们能够从单个元组中多次学习规律。回顾罕见的状态并充分地利用经验;另一个改善是,过往的经验中每个动作A都以某种方式影响下个状态S,意味着一系列经验元组可能关系非常紧密,如果按照顺序学习会面临受到这种联系影响的风险,而借助replay buffer我们可以随机地从缓冲区取样,不一定必须是储存元组的同一顺序,这有助于打破相互之间的联系,并最终防止动作值严重振动或发散
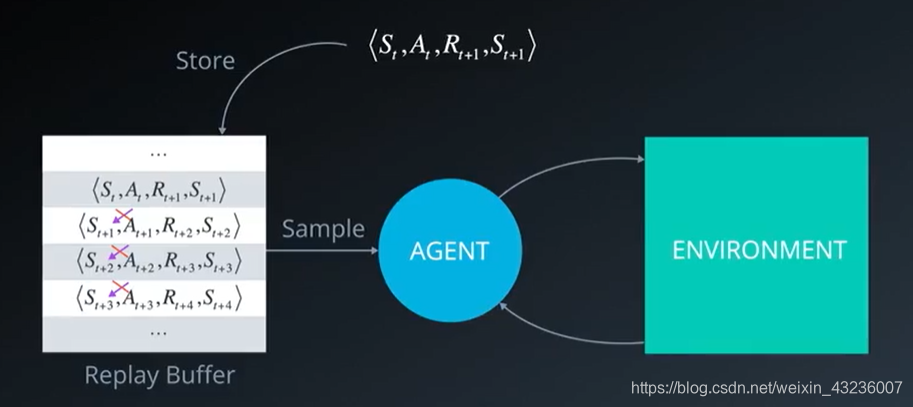
从replay buffer中抽取minibatch的经验元组来训练神经网络
这篇关于强化学习基于值6.2 | replay buffer经验回放的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






