本文主要是介绍《Unsupervised Scale-consistent Depth ...》论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇笔记是关于3篇文章的合集,它们分别是:
- 《Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video》
- 《Unsupervised Scale-consistent Depth Learning from Video》
- 《Auto-Rectify Network for Unsupervised IndoorDepth Estimation》
参考代码:
- SC-SfMLearner-Release
- sc_depth_pl
1. 概述
介绍:在自监督的深度估计算法中MonoDepth2一个较为经典的方法,文章的整体pipeline与其存在一定的相似性,都是输入连续视频帧作为输入,通过构建光度重构误差进行深度预测和相机位姿的修正。在这篇文中比较鲜明的创新点主要包含如下几点:
1)对于视频中存在物体运动、遮挡与一些困难像素区域(无纹理或是若纹理)情况提出了一种新的reweight机制,从而去降低这些像素在整体训练过程中的影响,从而提升深度自监督网络的训练稳定性;
2)自监督的深度估计方法在训练和测试中是使用不同的帧切片进行的,这就导致其深度预测的scale是不一致的,这就对后期恢复真实轨迹信息(视觉里程计)带来了困难,对此文章提出了一种对于帧间scale进行约束的方法。在此基础上再套用一个SLAM的上层架构便可以得到基于视频自监督的SLAM;
不过需要注意的是文章提出的scale一致性并不能代表深度预测的一致性和平滑性,这一点需要进行区分。
这篇博文的内容主要来自于上面提到的3篇文章,不过这里进行介绍的内容主要偏向于深度估计,所以像论文2中提到的涉及SLAM相关的内容这里不做更多扩展。
2. 方法设计
2.1 自监督深度估计pipeline
文章的深度估计pipeline见下图所示:
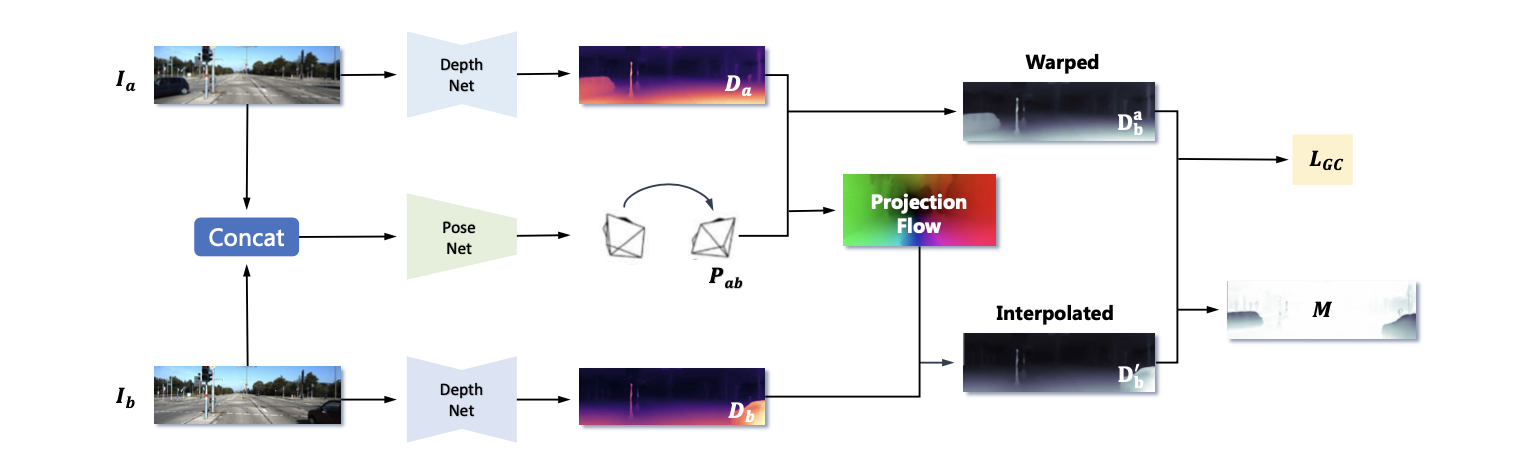
在上图中可以看到文章的方法与MonoDpeth2的方法很接近都是输入连续的2帧图像,通过DepthNet和PoseNet建立起图像之间的光度重构约束。输入的图像 ( I a , I b ) (I_a,I_b) (Ia,Ib)得到对应深度估计结果 ( D a , D b ) (D_a,D_b) (Da,Db)与相机位姿参数 P a b P_{ab} Pab。则对于光度重构误差可以将其描述为如下形式:
L p = 1 ∣ V ∣ ∑ p ∈ V λ i ∣ ∣ I a ( p ) − I a ′ ( p ) ∣ ∣ 1 + λ s 1 − S S I M a a ′ ( p ) 2 L_p=\frac{1}{|V|}\sum_{p\in V}\lambda_i||I_a(p)-I_a^{'}(p)||_1+\lambda_s\frac{1-SSIM_{aa^{'}}(p)}{2} Lp
这篇关于《Unsupervised Scale-consistent Depth ...》论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







