本文主要是介绍【论文精读04】AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【论文精读04】AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
论文链接:https://arxiv.org/pdf/2211.06679v2.pdf
源码:https://github.com/FlagAI-Open/FlagAI
从题目上可以看出,这篇论文的工作是对CLIP结构进行调整,以此来提高模型的语言理解能力。很有意思、有想法的一篇文章,借此做一个简单的精读,如有解读不当,请批评指正。
领域关键词:对比学习;多模态;零次学习
文章目录
- 【论文精读04】AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
- 1.摘要
- 2.结论
- 3.引言
- 4.相关工作
- 5.方法
- 5.1 教师学习阶段
- 5.2 对比学习阶段
- 6.模型训练
- 7.实验
1.摘要
在这项工作中,我们提出了一个概念上简单和有效的方法来训练一个强大的双语/多语言的多模态表示模型。设计一个预训练好的多语言文本编码器——XLM-R来替代CLIP中的文本编码器,并通过一个两阶段的训练模式——教师学习和对比学习来对齐语言-图像表示。我们在一系列任务上设置了最先进的性能,包括ImageNet-CN、Flicker30kCN、COCO-CN和XTD。此外,我们与CLIP在几乎所有任务上都获得了非常接近的性能,这表明人们可以简单地改变CLIP中的文本编码器,以扩展功能,如多语言理解。
2.结论
结论的前半部分和摘要差不多,这里不赘述。重点记录一下后半部分。
在中文上,我们的方法有新的SOTA的性能:在多个zero-shot图像分类和检索任务上。**我们只需使用数千万的文本数据和二百万文本图像进行训练,而此前大多数的工作则需要在数亿的文本图像对上训练。**未来的工作包括:尝试改变图像编码器,以结合从不同的数据分布中学习到的视觉信号,并消除可能需要机器翻译的数据,进而构建一个多语言多模态预训练模型。
3.引言
现有研究工作存在的问题:
(1)训练一个好的语言图像表示模型通常需要大量的文本图像对和大量的计算资源。
(2)现有的跨语言或多语言设置下的工作主要关注模型的检索性能,而忽略了模型的泛化能力。
我们提出了一种名为Alter自我CLIP(AltCLIP)的双语模型,该模型在ImageNet和多模态检索任务中都取得了很好的性能。我们的AltCLIP在一个两阶段的框架下学习了一个强大的双语语言图像表示(见图1)。**第一阶段,我们使用教师学习来提取从CLIP中学到的知识。第二阶段,我们采用对比学习对少量的中文和英语文本-图像对训练模型。**我们通过对广泛的英-中基准的实验,证明了我们的方法的有效性。此外,我们在中文的多重图像分类和检索任务上建立了新的最新的结果。我们进一步扩展了这种方法,训练一个多语言多模态模型,我们称之为AltCLIPM9。

4.相关工作
这一部分主要介绍了一下CLIP、知识蒸馏等方法背景,比较基础所以略过。XLM-R模型是Facebook在2020年提出的,大致内容是采用无监督的方法训练了一个多语言模型(基于transformer的、多语言mask的),在2.5TB新创建的100种语言的干净CommonCrawl数据上进行训练。
XLM-R(Conneau等人,2020年)是一种多语言语言模型,它在广泛的跨语言任务中取得了强大的性能。在我们的工作中,我们使用XLM-R模型作为底层文本编码器,并将其与用CLIP训练的图像编码器对齐,以实现在跨语言和跨模态任务上的竞争性能。
XLM-R论文:https://arxiv.org/abs/1911.02116
5.方法
我们提出了一种两阶段的方法来学习良好的双语和多语言语言图像表示模型。在第一阶段,我们遵循Carlsson等人(2022年)的工作,使用教师学习从CLIP文本编码器中学习多语言文本编码器。在这一步的训练中不需要图像,只使用并行的语言对数据。在第二阶段,我们利用对比学习方法对输入数据是文本-图像对的模型进一步微调。图1总结了我们的过程。
5.1 教师学习阶段
在这一阶段,我们将CLIP的text encoder作为教师模型,将XLM-R作为学生模型。此外,添加一个全连接层,将XLMR模型的输出转换为与教师编码器相同的输出维度。我们使用英汉并行文本数据来提取文本-图像对齐的知识。
给定并行文本输入 ( s e n t 1 , s e n t 2 ) (sent_1,sent_2) (sent1,sent2),教师文本编码器从输入的 s e n t 1 sent_1 sent1中生成学习目标,即 [ T O S ] [TOS] [TOS]标记的嵌入,用 x t o s t x_{tos}^t xtost表示。学生文本编码器从输入的 s e n t 2 sent_2 sent2中生成嵌入的 x c l s s x^s_{cls} xclss。我们最小化了 x t o s t x_{tos}^t xtost和 x c l s s x^s_{cls} xclss之间的均方误差(MSE)。经过这样的训练后,学生文本编码器可以保持其大部分的多语言能力,并获得两种语言的文本-图像对齐能力。请注意,教师编码器只在培训时使用。在推理时,只使用学生编码器作为文本编码器。
为了证明我们的方法在包含更多语言方面是可扩展的,我们构建了一个多语言版本,它支持九种不同的语言:英语(En)、汉语(Zh)、西班牙语(Es)、法语(Fr)、俄语(Ru)、阿拉伯语(Ar)、日语(Ja)、韩语(Ko)和意大利语(It)。对于多语言版本,我们将更多的语言与英语对齐,其概念和架构与双语版本相同。
5.2 对比学习阶段
这一阶段将CLIP中的ViT作为图像编码器,上一阶段训练得到的XLM-R作为文本编码器;注意,这里的图像编码器在训练阶段是被冻住的,只更新文本编码器中的参数。
6.模型训练
两个阶段所使用的数据集以及超参数设置详见原文。。。
7.实验
在不同数据集上和SOTA的对比实验结果(表2)
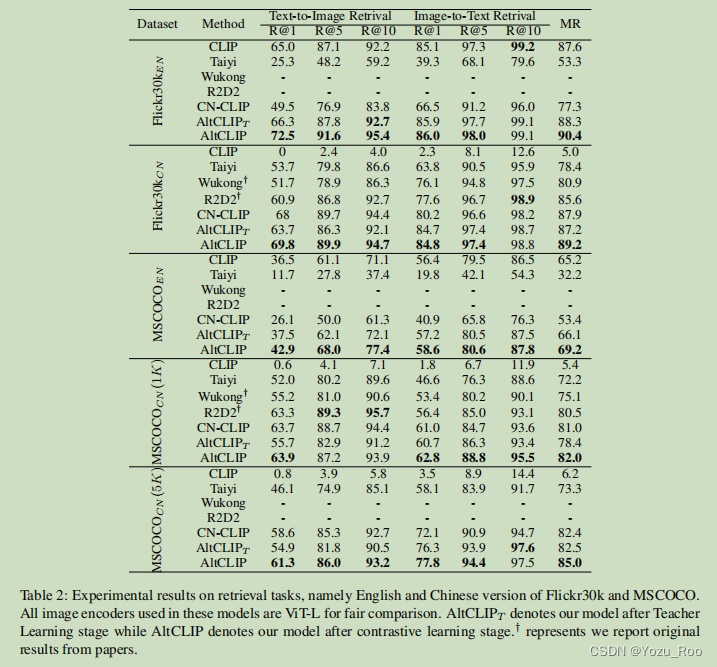
表2:Flickr30k和MSCOCO英文检索任务的实验结果。在这些模型中使用的所有图像编码器都是ViT-L,以便进行公平的比较。 A l t C L I P T AltCLIP_T AltCLIPT表示教师学习阶段后的模型,AltCLIP表示对比学习阶段后的模型。 † † †表示我们报告论文的原始结果。
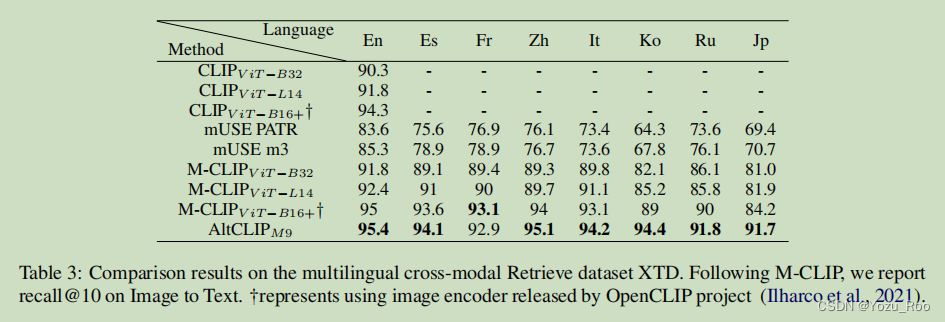
表3:对多语言跨模态检索数据集XTD的比较结果。在M-CLIP之后,我们报告图像到文本的Recall@10。使用OpenCLIP项目发布的图像编码器进行表示(Ilharco等人,2021年)。
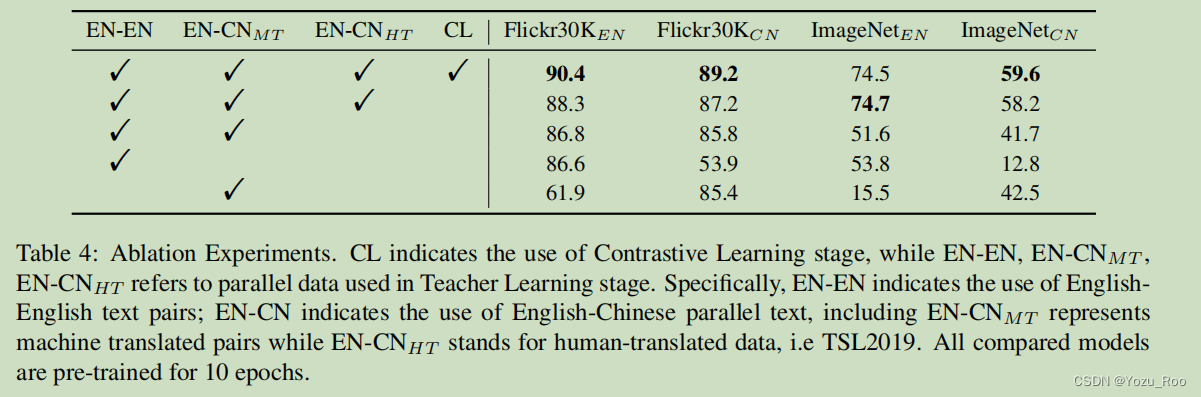
表4:消融实验。CL表示对比学习阶段的使用,而EN-EN、 E N − C N M T EN-CN_{MT} EN−CNMT、 E N − C N H T EN-CN_{HT} EN−CNHT表示在教师学习阶段使用的并行数据。具体来说,EN-EN表示使用英语英语文本对;EN-CN表示使用英汉并行文本,其中 E N − C N M T EN-CN_{MT} EN−CNMT表示机器翻译对, E N − C N H T EN-CN_{HT} EN−CNHT表示人类翻译数据,即TSL2019。所有被比较的模型都经过了10个时代的预训练。
我们使用altclip引导的扩散模型从中文和英文提示中生成图像,具体的实验结果参见原文,这里篇幅有限不再记录。
这篇关于【论文精读04】AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
