本文主要是介绍如何削减 50% 机器预算?“人机对抗”探索云端之路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
人机对抗旨在联合各个安全团队,共同治理黑灰产。由于历史原因,业务端对各个安全能力的访问方式入口多,对接系统/协议有十几个,呈现碎片化的状态,对外不利于业务对安全能力的便捷接入,对内不利于安全团队间的协同共建。为了提升各方面的效率,人机对抗服务在建设过程中大范围使用云服务,取得了很好的效果。回顾安全能力上云的过往,是一个从模糊到清晰,从迟疑到坚定的过程,在此给大家做个简要的分享。
关于云
云是什么
我理解的云本质可以理解为自由灵活的资源共享。资源随时加入,随时脱离,如空中飘动的云,来去无定,云起云落,看起来是那片云,细看又不一样。
对云的期待
站在计算机应用的角度,理想的云是可以让计算/网络/存储资源变成生活中的水和电,操控开关即可呼之即来挥之即去。对比物理机部署时代,云用户不用因某台机器死机造成数据损坏而暴走,也不用因机器损坏加班恢复服务而黯然神伤,
自动容灾(异常拉起,故障迁移)
轻松异地部署(多集群)
资源隔离-死道友不死贫道,你贪心了,安息吧
快捷扩容,资源呼之即来,来即能战
一切多么完美,开发运维测试兄弟的福音啊!
系统上云分析
随着公司基础服务的完善,目前公司内已有的服务设施可支持我们上云。经过调研发现,公司云相关平台及部署方式有:
CVM
在物理机基础上是对机器硬盘及 cpu 等资源做了虚拟化,用户使用方式上本质还是物理机的方式,只是可以避免机器裁撤的痛苦,用户体验层面上没有本质的改变。
容器化部署平台
docker 容器化部署是目前业界云主要部署方式,docker 容器化部署让我们一次建构,到处运行,完美满足自由运行,资源隔离的要求,系统环境天然是强维护的,一切程序/脚本/配置都在镜像中,不再有丢失或遗漏维护的问题。物理机时代机器损坏导致脚本配置破坏无法恢复的现象不会再出现,系统维护靠自觉或强约束这些问题天然地消失了。
而类似 K8s 这样的容器编排调度系统的出现,支持了自动容灾/故障切换/多集群部署等强大的平台特性,使我们离云服务的目标更近一步。基于 K8s 容器编排调度机制,目前公司内开发出一系列的部署平台,比如 123 平台,GaiaStack,TKE 等,再完美配合L5/北极星等寻址服务的自动关联管理,为云服务提供了完整的平台机制支撑。再加上基于资源管理平台对资源的灵活调配,使云计算使用的便捷性更上一台阶。比如在云梯上资源申请TKE容器资源(CPU/内存/存储等),过程就像到淘宝下单购物一样流畅,资源到位快速,在强推动审批下可达到分钟级到位,我第一次体验时是惊讶赞叹的。
基于对公司服务的深入了解及分析,最终我们决定使用 TKE 部署平台,采用 docker 容器化部署的方式对人机对抗服务上云
上云对开发的核心影响
上云带来一个核心变化就是资源是易变的,为了便于系统资源调度,服务结点IP是可变的,上云后需要面对包括上游业务端/自身/下游依赖端的IP变化,由此衍生出一系列的约束及依赖
- 上游变化: 对客户端通过来源IP鉴权模式不再可行,需要一种更灵活有弹性的鉴权方式
- 自身变化: 对外服务地址可将服务地址关联绑定到北极星的方式向外提供服务,如果所依赖的下游需要鉴权且使用源IP鉴权的话,下游需要改造支持更灵活的鉴权方式。多数情况下,服务需要对自身做一些例行运维工作,比如需要频繁修改配置下发,老的运维工具不再行得通,需要一个集中的运维配置中心。
- 下游的变化: 这个倒问题不大,只要提供L5或北极星方式自动寻址即可,目前平台提供了相应的服务管理功能。
系统架构及上云规划
人机对抗数据中心主要模块为变量共享平台,它的核心有2个,一个查询服务模块,另一个是支持变量管理 api 的 web 模块,这两模块都基于 tRPC-Go 框架开发,系统架构图如下:
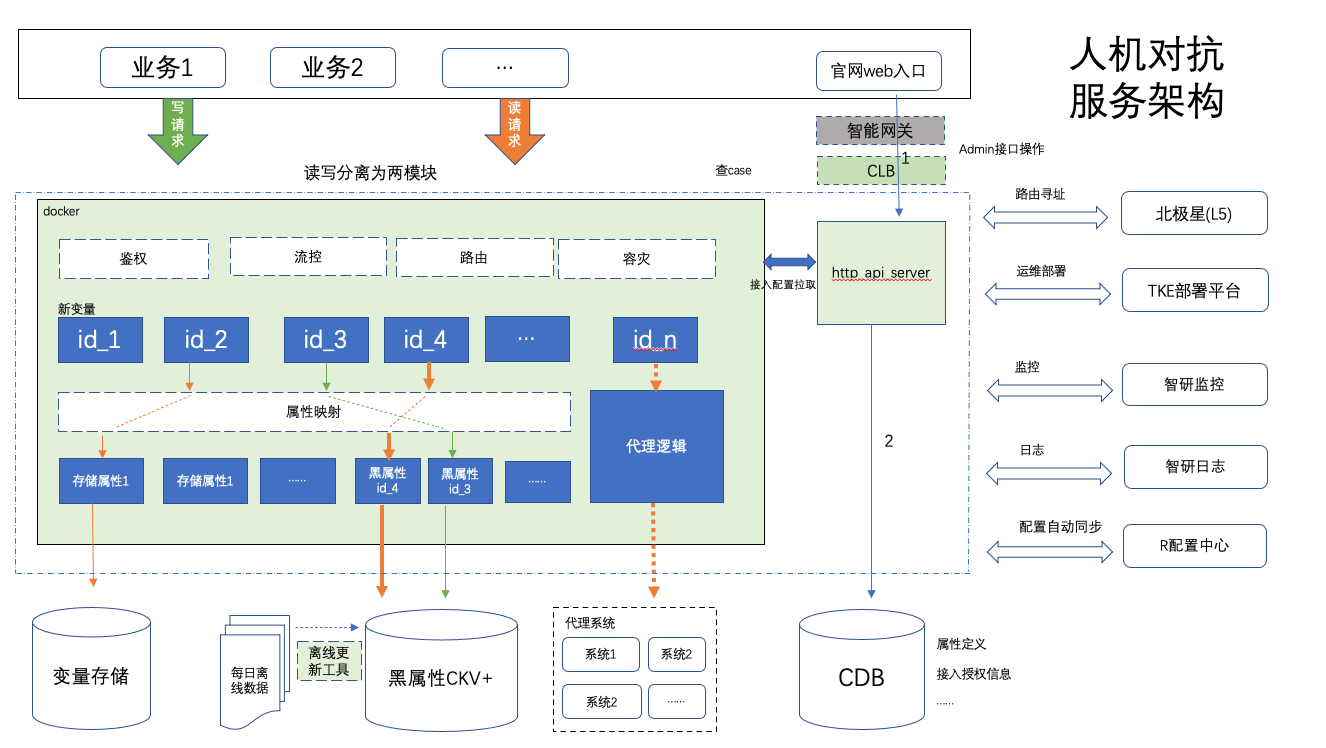
忽略一些依赖系统,目前暂时只对两个核心部分使用 TKE 部署上云,整个 TKE 部署架构如下:
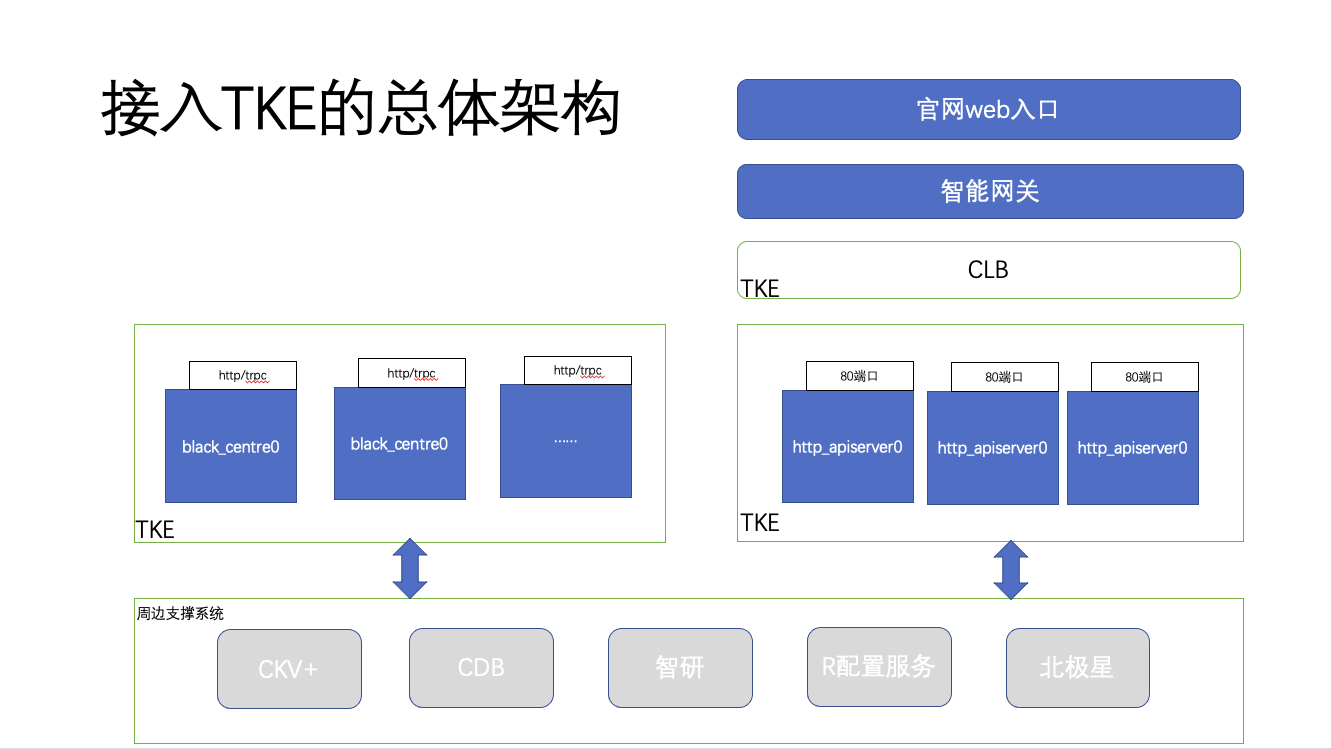
整个系统的部署规划,分别在 TKE 上创建两个系统负载 black_centre,http_apiserver,这两部分都是核心&#
这篇关于如何削减 50% 机器预算?“人机对抗”探索云端之路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









