本文主要是介绍ChatGPT热潮下水力模型的思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

ChatGPT横空出世,快速火爆全球,基于大数据、大算力的人工智能技术来势汹汹、势不可挡,似乎要革全世界打工人的命!
本人多年来一直从事供排水系统水力建模和应用相关的工作,在水行业里,算是跟数据和模型打交道比较多了。面对大数据时代的到来,我也常在思考,数据能给水行业带来怎样的变化?也常有朋友问我关于数据模型和机理模型的问题,例如:
● 二者的本质区别是什么?
● 既然水力模型的建立和维护如此困难,未来是不是数据模型直接取代机理模型?
● 假如数据模型和机理模型可以结合起来应用,结合的逻辑是什么?
对于上述问题,虽然自己也有一些零零碎碎的思考,但同时也有不少疑惑。最近观看了美国国家工程院院士、东方理工高等研究院常务副院长张东晓教授的线上主题演讲《科学机器学习中的知识嵌入与知识发现》,有点醍醐灌顶的感觉,特以此文与大家分享。

#点击获取演讲链接#![]() https://www.bilibili.com/video/BV1254y1w7Kh/?spm_id_from=333.337.search-card.all.click&vd_source=b8f422275696efa2614c3b0539869466
https://www.bilibili.com/video/BV1254y1w7Kh/?spm_id_from=333.337.search-card.all.click&vd_source=b8f422275696efa2614c3b0539869466
张教授的演讲包括三部分,分别是:
● 数据模型:数据驱动模型及其局限性;
● 知识嵌入:即理论指导的数据驱动模型,也就是构建具有物理常识的AI模型;
● 知识发现:即数据驱动的模型挖掘,是利用AI探索物理原理和机理等新知识。
张教授指出,机理模型属于人类探索世界,已经获取的知识的一部分。通过引入行业知识,可以有效提升机器学习模型的效果;将知识的嵌入和知识的发现结合起来,形成闭环,可以极大提高AI解决实际问题的能力。
01/数据驱动模型:有效但有局限性
张教授先举了光伏发电预测的例子,来说明数据驱动的有效性。通过输入辐照量、温度、湿度、风速、昼夜等特征变量,以及历史的光伏发电量数据,利用卷积神经网络或者循环神经网络等方法建立数据的映射关系,基于此映射关系和天气预报数据,预测第二天光伏的发电量。核心逻辑就是寻找多元输入变量和目标变量之间的复杂映射关系,从而构建它预测的模型。
在供水行业,大量的研究也是采用类似的方法进行需水量预测,相关的文章不计其数,但实际用于供水生产实践的寥寥。
张教授继而分析了数据驱动模型的局限性,主要有:
● 数据不易获取且采集成本高昂;如地下水资源勘查所需一口测量井的成本高达几千万元;深度学习和参数训练需要大数据、大模型和大算力,如ChatGPT-3有1750亿个参数,费用不菲。
● 数据驱动模型常用的MSE(均方误差)等指标,是对误差的数据平均度量,无法区分物理系统过程的差异。
● 没有常识、缺少知识;由于缺乏人类世界的各种常识和知识,结果可能错的离谱!
02/知识嵌入:克服数据模型局限性的解决方案
张教授提出构建数据和知识(机理)双驱动模型的理念,提升模型精度和鲁棒性,降低数据的需求。
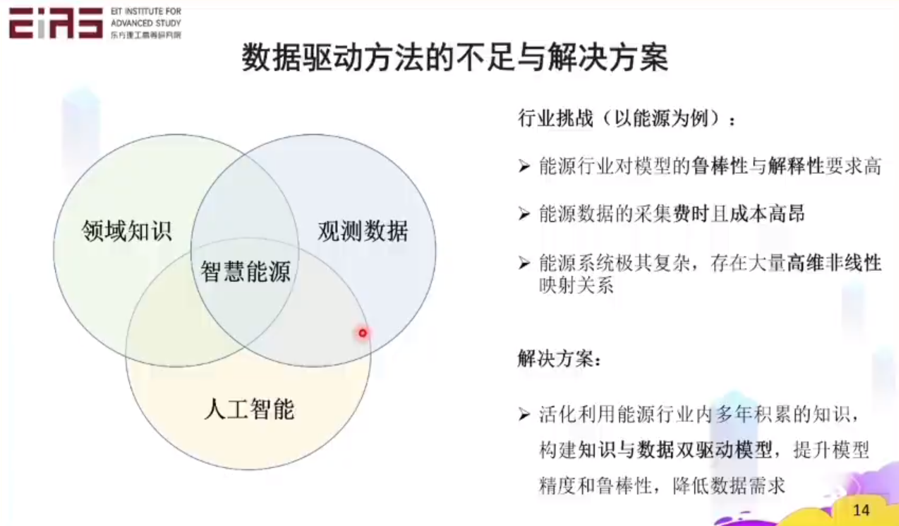
知识嵌入,是将行业的已有经验和知识整合到数据模型中的过程,即是构建具有物理常识的数据模型。与前述的数据驱动模型相比:
● 提高准确性:借助机器学习的强拟合能力,描述变量间高维复杂映射关系;
● 提高可靠性:利用行业先验知识,保证预测结果符合原有的物理机理。
张教授用能源领域的案例,展示了在数学建模过程中的不同环节进行知识嵌入的方法,如数据预处理环节、模型结构设计环节、模型调优环节等。并且以地下水流动模型为例,说明行业经验和机理如控制方程、边界条件等,对于提高模型预测能力的重要性。在此框架下,可构建替代模型或数字孪生,从而减少数据模型对于数据量的依赖,缩短训练时间,提高模型的准确性。
与地下水流动模拟预测相似,城市内涝的实时预测,常受限于机理模型计算的速度太慢,城市级别的内涝模拟动辄几个小时,无法满足即时响应的需求。数据模型由于缺乏足够的历史数据,预测结果误差太大,不足以让人信服。把机理模型和数据模型结合,能大大提高计算的速度和预测的精度,将会是一个很好的技术路线。
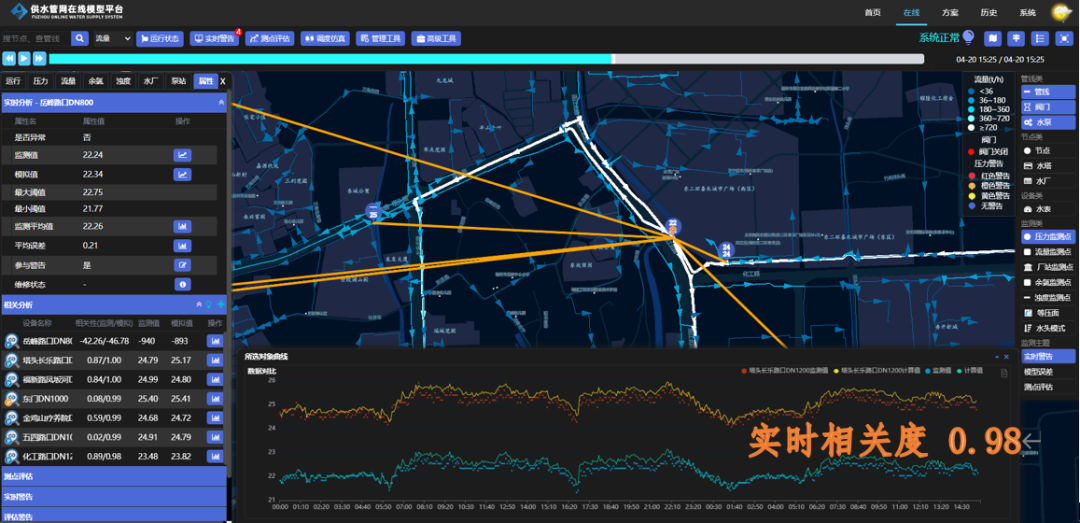
下面分享一个我们公司基于实时在线水力模型做的爆管警告的例子,就是利用机理模型嵌入到数据模型中,实现即时可靠的爆管警告。
常规供水调度的爆管判断,是基于多个相关监测点的压力突降,且用水量上升,则判断为存在大漏或者爆管。这个方法的难点在于:如何确定监测点之间的关联,特别是压力监测点和流量监测点的关系。常规方法是通过测点之间距离形成监测组的概念,这种方法的缺点:人工工作量大,可靠度低,经常误判,导致实用性下降。
基于实时在线水力模型,能实时计算各个监测点之间的相关关系,把相关度高的监测点自动形成事件监测组,再利用模拟值和监测值的误差突变,从而提高事件报警的准确性和可靠度。
03/知识发现:数据+机理,行业+AI的深度融合
最有意思的是张教授最后谈到基于数据模型的知识发现。什么叫知识发现?可以理解为从时空观测数据中直接挖掘控制方程,从而为世界获取新的知识。
以万有引力举例,第谷花了近40 年的时间获取火星轨道的观测数据,开普勒又花了17年的时间,运用这些数据来研究行星运动的轨迹,最后得到行星运行的三大定律。在此基础上,天才的牛顿进行了理论的延伸和公式的推导,发现了万有引力定律,距离开普勒的发现已经是69年之后,从第谷到牛顿前后花了一百多年的时间。但有了AI的加持,未来计算机技术的发展,将大大加快这一过程!

关于是AI加行业,还是行业加AI的争论,张教授认为,AI是算法,属于通用的模型,解决各个行业的问题应该是行业加AI,其实就是机理模型加AI才是未来的发展之路。知识的嵌入和知识的发现,形成一个闭环,从而大大提高人工智能解决实际问题的能力。
最后重新回到文章开始的三个疑问。从本质来说,不管是数据模型还是机理模型,都是人类认识和理解世界的方法,在当前的技术手段,机理模型和数据模型都有其有效性和局限性,寻找他们的结合点将会产生很大的价值。作为一个理工男,基本的观点是:世界是可解释的。相信AI将不仅是系统结果的产生者,而是最终变成知识的发现者。在人工智能的浪潮中,未来人类(机器)发现知识的速度会远远超过曾经的“天才”们,细思极恐!
最后还是强烈建议大家去看张教授的视频。
这篇关于ChatGPT热潮下水力模型的思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









