本文主要是介绍python实战之泰坦尼克号获救问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据来源:
Kaggle数据集 →
共有1309名乘客数据,其中891是已知存活情况(train.csv),剩下418则是需要进行分析预测的(test.csv)
字段意义:
PassengerId: 乘客编号
Survived :存活情况(存活:1 ; 死亡:0)
Pclass : 客舱等级
Name : 乘客姓名
Sex : 性别
Age : 年龄
SibSp : 同乘的兄弟姐妹/配偶数
Parch : 同乘的父母/小孩数
Ticket : 船票编号
Fare : 船票价格
Cabin :客舱号
Embarked : 登船港口
目的:通过已知获救数据,预测乘客生存情况研究问题:
1、整体来看,存活比例如何?
要求:① 读取已知生存数据train.csv② 查看已知存活数据中,存活比例如何?
提示:① 注意过程中筛选掉缺失值之后再分析② 这里用seaborn制图辅助研究
2、结合性别和年龄数据,分析幸存下来的人是哪些人?
要求:① 年龄数据的分布情况② 男性和女性存活情况③ 老人和小孩存活情况
3、结合 SibSp、Parch字段,研究亲人多少与存活的关系
要求:① 有无兄弟姐妹/父母子女和存活与否的关系② 亲戚多少与存活与否的关系
4、结合票的费用情况,研究票价和存活与否的关系
要求:① 票价分布和存活与否的关系② 比较研究生还者和未生还者的票价情况
5、利用KNN分类模型,对结果进行预测
要求:① 模型训练字段:‘Survived’,‘Pclass’,‘Sex’,‘Age’,‘Fare’,'Family_Size’②模型预测test.csv样本数据的生还率
提示:① 训练数据集中,性别改为数字表示 → 1代表男性,0代表女性
泰坦尼克号获救问题十分经典,比较初级,不过也很有练习价值。在这里我也简单记录一下自己的思路,小小分享,欢迎指正。
拿到问题,先打开数据看一看,了解一下大概情况以及分析目的。
前四问很简单,需要对数据进行描述、评判,最后一问是利用模型进行简单的预测。整体难度不高。
1 导入模块,加载数据
根据题目要求,预测需要的模块,也可以后期用到再加。然后导入数据,查看具体情况。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import timeimport warnings
warnings.filterwarnings('ignore')os.chdir('/Users/eleven/Desktop/python/泰坦尼克号获救问题/')
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
2 查看存活比例
存活只有两个数据值,1和0,可以直接用饼状图来体现,简单直观。
sns.set()
sns.set_style('ticks')
plt.axis('equal')
survive_per = train_data['Survived'].value_counts()
survive_per.plot.pie(autopct = '%.2f%%')
用seaborn制图,设置为正方形的绘图空间,通过value_counts计数,生成pie饼状图
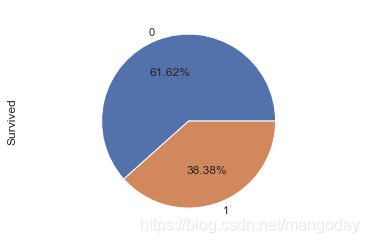
得到存活比例为38.38%。
3 分析幸存下来的人群分布
(1)年龄数据的分布情况
简单的看分布情况,可以用直方图和箱型图来表示。
train_data_age = train_data[train_data['Age'].notnull()]
#去除缺失值plt.figure(figsize = (12,6))
plt.subplot(121)
train_data_age['Age'].hist(bins = 70)
plt.xlabel('age')
plt.ylabel('num')
#绘制直方图plt.subplot(122)
train_data.boxplot(column = 'Age',showfliers = False)
#绘制箱型图train_data_age['Age'].describe()
#数据描述
这篇关于python实战之泰坦尼克号获救问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








