获救专题
Titanic沉船数据集之获救乘客预测
项目目标: Titanic数据集是我们进入到机器学习领域中的第一个数据集,同我们学习编程的第一句程序语言(‘hello,world’)是一样的。通过对该数据集进行机器学习建模,掌握Numpy,Pandas,Matplotlib,Sklearn等常用数据分析库的使用,并掌握机器学习的完成流程数据预处理 - 建立基础模型 - 模型评估 - 调参 - 固定模型参数。 背景介绍: 泰坦尼克沉船是震惊

教女朋友学数据挖掘——泰坦尼克号获救预测
学习笔记 一、数据挖掘任务流程 1.1 数据读取 统计数据,并进行展示统计数据各项指标明确数据规模和要完成任务 1.2 特征理解分析 单特征分析,逐个变量分析其对结果的影响多变量统计分析,综合考虑多种情况影响统计绘图得出结论 1.3 数据清洗与预处理 对缺失值进行填充特征标准化/归一化筛选有价值的特征分析特征之间的相关性 1.4 建立模型 特征数据与标签准备数据集切分帅
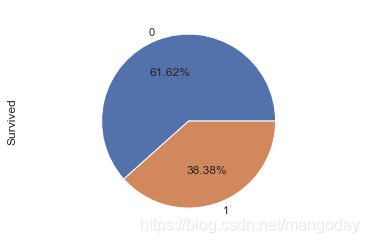
python实战之泰坦尼克号获救问题
数据来源: Kaggle数据集 → 共有1309名乘客数据,其中891是已知存活情况(train.csv),剩下418则是需要进行分析预测的(test.csv) 字段意义: PassengerId: 乘客编号 Survived :存活情况(存活:1 ; 死亡:0) Pclass : 客舱等级 Name : 乘客姓名 Sex : 性别 Age : 年龄 SibSp : 同乘的兄弟姐妹/配偶数 Pa

数据分析案例实战:泰坦尼克船员获救
学习唐宇迪《python数据分析与机器学习实战》视频 一、数据分析 可以看到有些数据是字符串形式,有些是数值形式,有数据缺失。 survived:1代表存活,0代表死亡,目标tag。 Pclass:船舱,较重要。 sex:性别,较重要。 age:年龄,有缺失值,较重要。 SibSp:兄弟姐妹。Parch:父母孩子。 Ticket:票。 Fare:船票价格,特征可能与船舱特征重复,也较重要

泰坦尼克号船员获救学习记录
基于已有的信息预测当遇难时,是否可以获救 第一步,提取出最有价值的信息 survived→0表示遇难,1表示幸存 Pclass→舱室类型 Name→遇难者姓名 Sex→性别 Age→年龄 SibSp→有多少亲人一起来坐船 Parch→身边有多少老人和孩子 Ticket→票的编号 Fare→票价 Cabin→舱号 Eabarked→在不同的站区上的车 第二步,制作出分类器完成预测是否可以获救