本文主要是介绍张量/数组存储方式与向量化展开/展平、view、reshape、permute对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 逻辑存储与内存存储
- 1.1 高维张量
- 1.2 按行展开和按列展开
- 2 矩阵向量化、按行按列展开
- 2.1 numpy中:
- numpy.ravel()
- ndarray.flatten()
- 2.2 Pytorch中:
- 3 pytoch中的view,reshape,permute对比
- 3.1 view
- 3.2 reshape
- 3.3 permute
链接文章:
python pytorch中 .view()函数讲解
pytorch中张量的分块.chunk()方法和拆分.split()方法
NumPy中 ravel() 和 flatten() 展平数组 对比——Dust_Evc
NumPy:确定 ndarray 是查看还是复制以及它是否共享内存
tensor数据存储与内存共享
深入理解Tensor对象_下:从内存看Tensor
1 逻辑存储与内存存储
对于一个Tensor来说,我们可以认为它有两种存储方式
- 逻辑存储

- 内存存储

1.1 高维张量
- 在torch/numpy中, 即使是高维张量在内存中也是存储在一块连续的内存区域中
- 会记录一些元信息来描述数组的"形态", 例如起始地址, 步长 (stride), 大小 (size)等.
- 对高维张量进行索引时我们采用
起始地址 + 地址偏移量的计算方式, 而地址偏移量就需要用到stride和size的信息

当我们在使用view去修改tensor的时候, 其实我们并没有修改tensor在内存中的存储, 而只是通过修改stride和size来描述张量形状的变化
1.2 按行展开和按列展开

- 如果张量x的行优先展开形式和其内存存储一致, 则我们称之为 C-contiguous
- Numpy, Pytorch中的
contiguous指的就是C-contiguous
- Numpy, Pytorch中的
- 如果张量x的列优先展开形式和其内存存储一致, 则我们称之为 Fortran-contiguous
- Matlab, Fortran中的
contiguous指的是Fortran-contiguous.
- Matlab, Fortran中的
- 可用转置实现两种存储格式的转换,以pytorch为例:
vp=torch.randn(1,204)
vp1=vp.view(68,-1) ## torch.size ([68,3])
vp2=vp1.t() ## torch.size ([3,68])# vp2 就是 vp 的 Fortran-contiguous 版本
2 矩阵向量化、按行按列展开
2.1 numpy中:
numpy.ravel()
numpy.ravel(a, order=‘C’)
返回一个连续的展平数组。
返回包含输入元素的一维数组。仅在需要时制作副本。
从 NumPy 1.10 开始,返回的数组将与输入数组具有相同的类型。(例如,将为masked 数组输入返回masked 数组)
参数:
输入:
a :array_like
输入数组。_a_中的元素按order 指定的 顺序 读取,并打包为数组。
order {‘C’,‘F’, ‘A’, ‘K’}, 可选
使用此索引顺序读取_a_的元素。‘C’ 表示以行优先、C 风格的顺序对元素进行索引,最后一个轴索引变化最快,回到第一个轴索引变化最慢。‘F’ 表示以列优先、Fortran 风格的顺序对元素进行索引,第一个索引变化最快,最后一个索引变化最慢。请注意,“C”和“F”选项不考虑底层数组的内存布局,仅参考轴索引的顺序。_‘A’ 表示如果a_是 Fortran_连续_的,则以类似 Fortran 的索引顺序读取元素在内存中,否则是类似 C 的顺序。‘K’ 表示按照元素在内存中出现的顺序读取元素,除了在步幅为负时反转数据。默认情况下,使用“C”索引顺序。
输出:
y :array_like
y 是与a_具有相同子类型的数组,形状为(a.size,)。请注意,矩阵是为了向后兼容而特制的,如果_a 是矩阵,则 y 是一维 ndarray。
例1:
import numpy as np
nd15=np.arange(6).reshape(2,-1)print(nd15)
#按照列优先,展平。
print("按列优先,展平")
print(nd15.ravel('F'))#按照行优先,展平。
print("按行优先,展平")
print(nd15.ravel())
结果:
[[0 1 2] [3 4 5]]
按列优先,展平
[0 3 1 4 2 5]
按行优先,展平
[0 1 2 3 4 5]
例2:
它相当于.reshape(-1, order=order)
>> > x = np.array([[ 1 , 2 , 3 ], [ 4 , 5 , 6 ]])
>> > np.ravel(x)
array([ 1 , 2 , 3 , 4 , 5 , 6 ])>>> x .reshape ( -1 )
array( [1, 2, 3, 4, 5, 6] )>> > np.ravel(x, order= 'F' )
array([ 1 , 4 , 2 , 5 , 3 , 6 ])当order是 ‘A’ 时,它将保留数组的 ‘C’ 或 ‘F’ 排序:
>> > np.ravel(xT)
array([ 1 , 4 , 2 , 5 , 3 , 6 ])
>> > np.ravel(xT, order= 'A' )
array([ 1 , 2 , 3 , 4 , 5 , 6 ])ndarray.flatten()
返回折叠成一维数组的副本。
-
参数:
order {‘C’, ‘F’, ‘A’, ‘K’}, 可选==‘C’ 表示按行优先(C 样式)顺序展平。“F”表示按列优先(Fortran 风格)顺序展平。‘A’ 表示如果a在内存中是 Fortran连续的,则按列优先顺序展平,否则按行优先顺序展平==。‘K’ 表示 按照元素在内存中出现的顺序展平*a 。*默认值为“C”。
-
输出:
yndarray _输入数组的副本,展平为一维。
例1:
>>> a = np.array([[1,2], [3,4]])
>>> a.flatten() # 按行展平
array([1, 2, 3, 4])
>>> a.flatten('F') # 按列展平
array([1, 3, 2, 4])例2:
a = torch.Tensor([[1,2], [3,4]])a.detach().numpy().flatten('C') #returns array([1., 2., 3., 4.], dtype=float32) # 按行展平
a.detach().numpy().flatten('F') #returns array([1., 3., 2., 4.], dtype=float32) # 按列展平
a.flatten() #returns tensor([1., 2., 3., 4.]) # 按行展平
2.2 Pytorch中:
pytorch中,flatten()、ravel()都是只能按行展平的,因此,如需按列展平,先转置、再展平。
并且官方文档里指出:与始终复制输入数据的 NumPy 的flatten不同,此函数可能会返回原始对象、视图或副本。如果没有尺寸被展平,则返回原始对象input。否则,如果可以将输入视为扁平形状,则返回该视图。最后,只有当输入不能被视为扁平形状时,才会复制输入的数据。
例子参考:https://discuss.pytorch.org/t/how-to-flatten-a-tensor-in-column-major-order/78636
例1:
# 使用转置方法reshape张量,然后再展平:
x = torch.tensor([[1,2,3],[4,5,6],[7,8,9]])
x.flatten()
tensor([1, 2, 3, 4, 5, 6, 7, 8, 9])
x.transpose(1, 0).flatten()
tensor([1, 4, 7, 2, 5, 8, 3, 6, 9])
例2:
t = torch.randn(3, 5)
t = t.t().contiguous().t() # .t()表转置
print(t.shape) # torch.Size([3, 5])
print(t.stride()) # (1, 3)
例3 (高维数组情况):
t = torch.rand(3, 3, 3)# convert to column-major order
t.set_(t.storage(), t.storage_offset(), t.size(), tuple(reversed(t.stride())))
t.flatten() # 1D array in column-major order
注意,如果你只是想要一个张量的一维以列为主序表示,上面的操作将改变张量t中元素的顺序。
下面这个函数不改变原张量t中元素的顺序(通过创建副本):
def flatten_fortran_w_clone(t): nt = t.clone()nt = nt.set_(nt.storage(), nt.storage_offset(), nt.size(), tuple(reversed(nt.stride()))) return nt.flatten()
自己以下面这个进行测试,发现最长一行执行后数据错误异常
t = torch.arange(24).view(2,3,4)# convert to column-major order
t.set_(t.storage(), t.storage_offset(), t.size(), tuple(reversed(t.stride())))
t_1 = t.flatten() # 1D array in column-major order
最长一行执行后,数据变为,并导致最后结果不对:
tensor([[[ 0, 12, 4198805246726073967,2333189101087841629],[ 4, 16, 4990343733199463764,2819301914315665708],[ 8, 20, 4404627256239728488,3181614316598867291]],[[ 1, 13, 4913279190858748719,3344032066469896253],[ 5, 17, 6712455194575194719,7165912501647646817],[ 9, 21, 8371743533659288608,8390891584407283488]]])
例4 (转为ndarray再展平,与上面ndarray.flatten()中的一个例子相同):
a = torch.Tensor([[1,2], [3,4]])a.detach().numpy().flatten('C') #returns array([1., 2., 3., 4.], dtype=float32) (row)
a.detach().numpy().flatten('F') #returns array([1., 3., 2., 4.], dtype=float32) (column)
a.flatten() #returns tensor([1., 2., 3., 4.]) (row)
3 pytoch中的view,reshape,permute对比
3.1 view
view要求输入和输出的 tensor 都是 contiguous 的, 否则会 throw exception- 换言之, 你不管对一个 tensor 使用了多少次
view, 你都只是在改变 stride 和 size, 并没有修改这个 tensor 的内存存储
3.2 reshape
- 对于 contiguous 的输入,
reshape等于view - 对于 incontiguous 的输入,
reshape等于tensor.contigous().view- 其中
contiguous()会开辟一块新的内存空间, 将 incontiguous 的张量按照行优先展开的方式存储进去. - 所以
reshape是有可能修改内存存储的结构的
- 其中
3.3 permute
- 虽然
permute和view一样, 都是修改 stride 和 size, 但是permute并不保证返回的 tensor 是 contiguous 的. - 换言之
permute().contiguous()就有可能修改内存存储方式了.
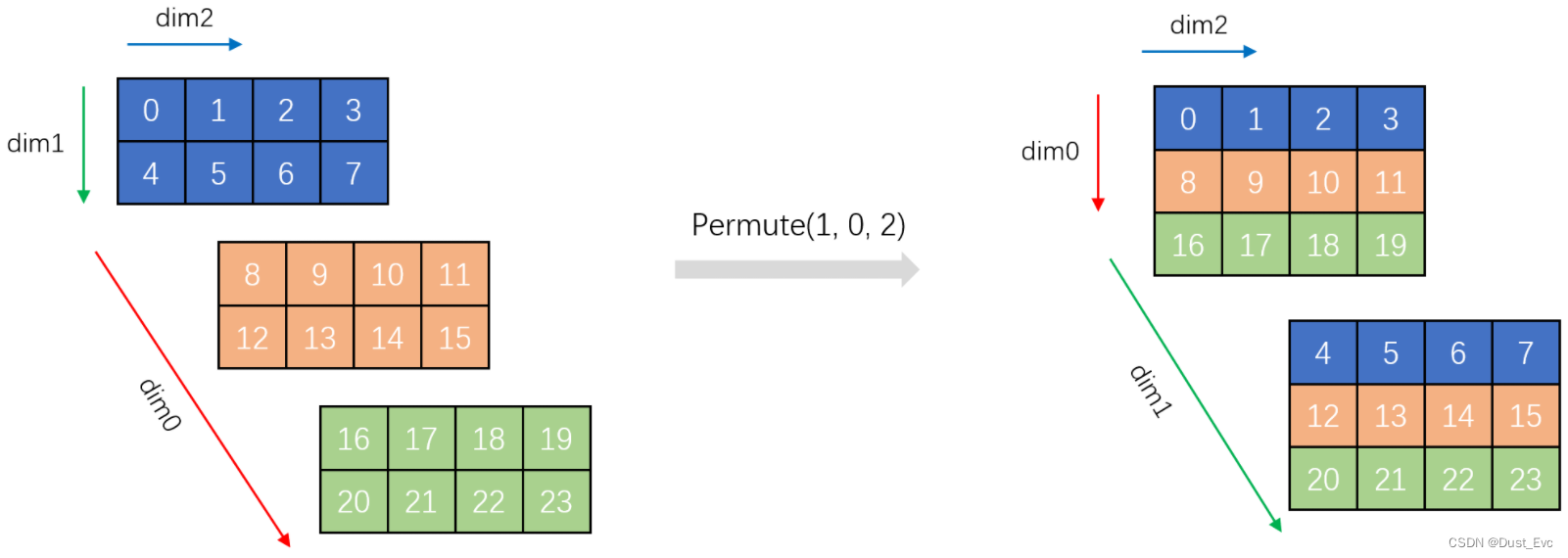
参考:https://coderlemon17.github.io/posts/2022/08-19-view/
这篇关于张量/数组存储方式与向量化展开/展平、view、reshape、permute对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






