本文主要是介绍基于pytorch使用一维卷积网络CNN的单特征的风速预测项目实战(适用于单特征预测问题),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、项目简介
本项目基于Pytorch使用一维卷积网络(CNN)实现时间序列(风速)的预测,只使用风速一个特征来预测风速,适用于单特征序列的预测问题,适用于初学预测的小伙伴。大部分代码参考多个网络上的代码,本人主要对整个项目分解到各个py文件中形成一个完整项目的基本框架,其他类似项目可以用这个框架进行修改,此外本人还对部分细节进行了修改,例如增加和修改了loss计算和相应的绘图,还增加了对pth文件的使用。
二、数据集
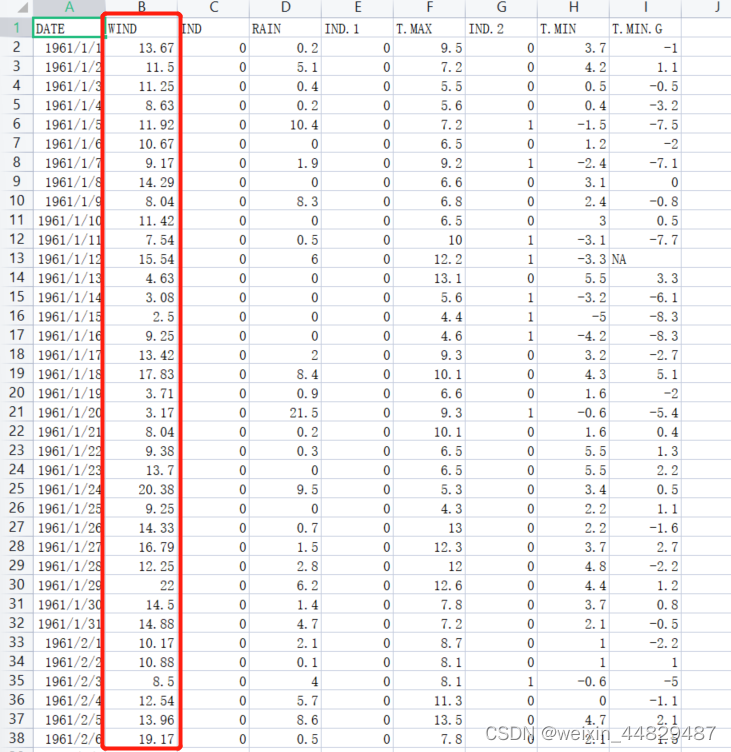
采用的是wind_dataset.csv,数据集时间、风速、降雨量等等参数,本项目只采用风速特征来预测未来一天的风速,即WIND这一列。数据展示如下
三、我的实验环境
平台:window11 语言:python3.9 编译器:Pycharm Pytorch:1.13.1+cu116
四、实验内容及文件说明
1、model.py
model.py定义了项目用到的网络模型,本项目用到的模型是三层的一维卷积网络,使用relu激活,全连接层输出预测结果。
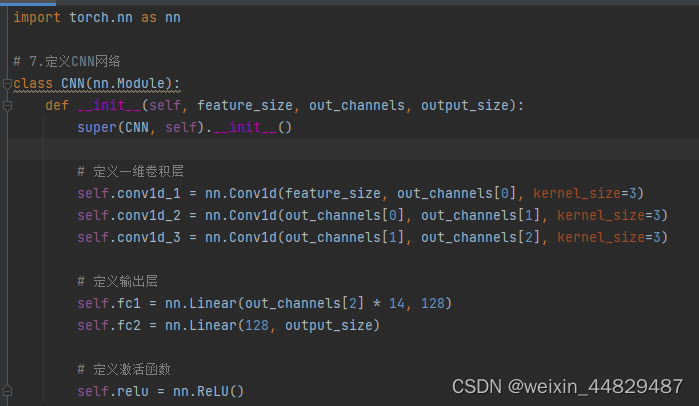
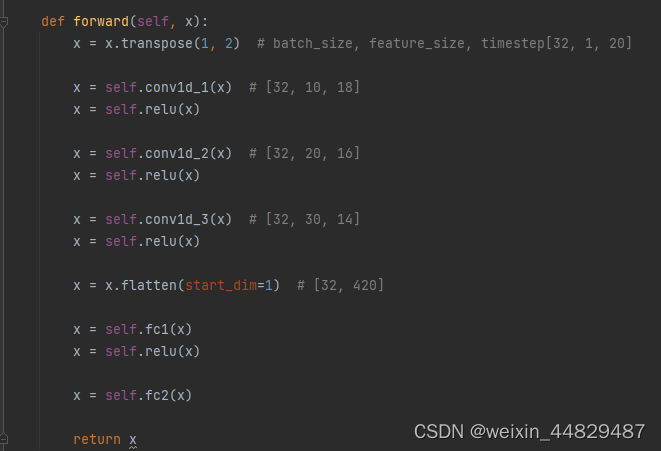
2、Config.py
Config.py文件定义了项目所需要用到的所有参数,把这些参数统一整合到一个文件中,实现参数的统一管理。
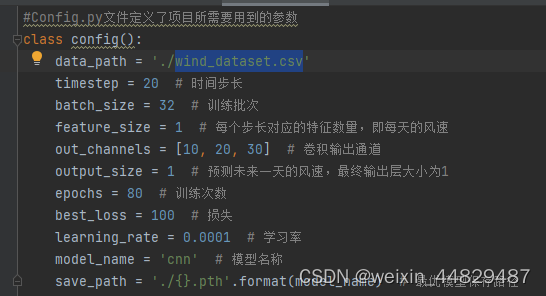
3、train.py
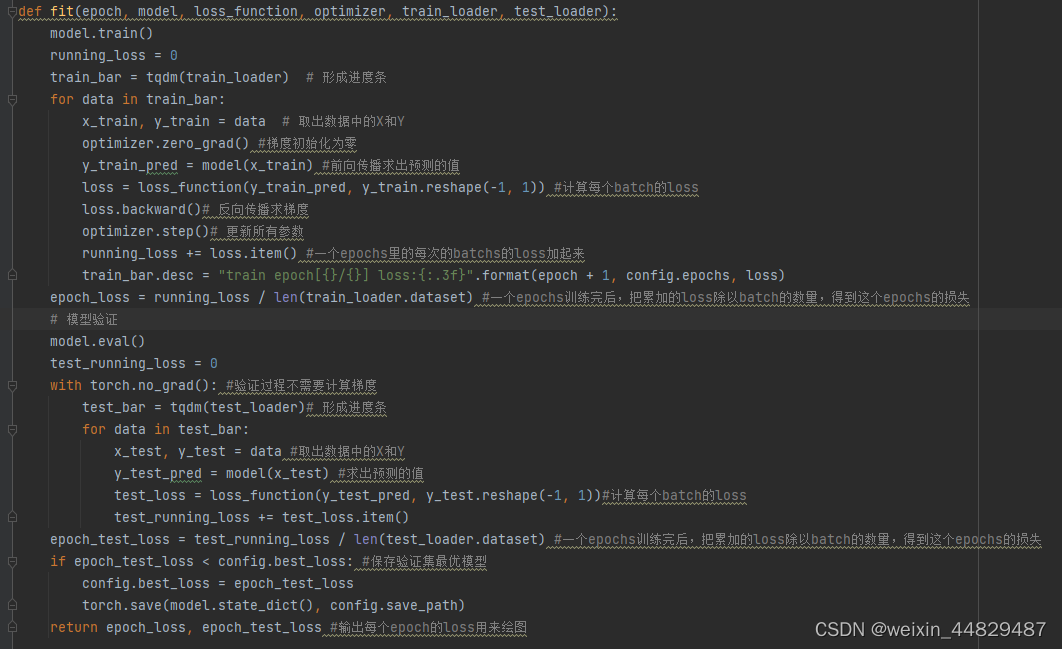
train.py是项目训练过程的通用代码,其他项目也可以在它的基础上修改后使用。
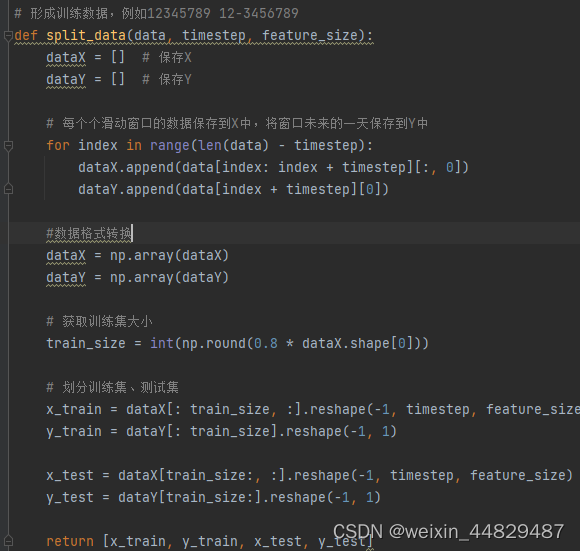
4、DataSplit.py 数据划分
DataSplit.py 是实现数据划分的函数,通过滑动窗口,将每个timestep大小的数据作为训练数据,将其后面一个数据作为预测结果,再进行划分训练数据和标签,最后分成训练集和验证集
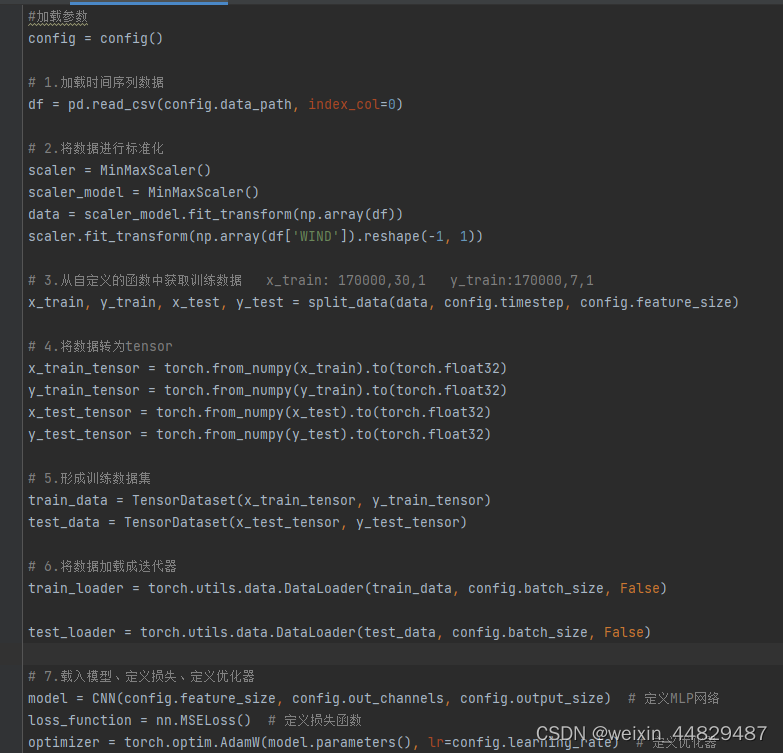
5、test_wind_CNN.py 训练文件
该py文件实现整体训练流程并做绘图操作。依次实现加载数据、数据标准化、取出WIND数据、划分训练集测试集、数据转化为Tensor、形成数据更迭器、载入模型、定义损失、定义优化器、开始训练、损失可视化、显示预测结果。
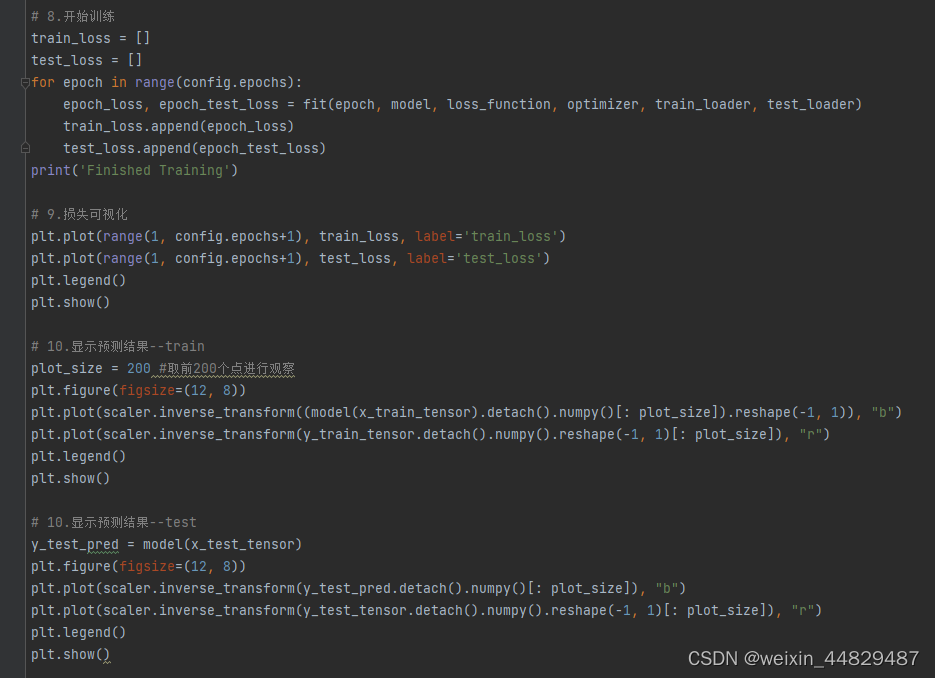
五、实验结果
以下实验结果展示的是epochs=80的训练过程,使用进度条展示训练过程
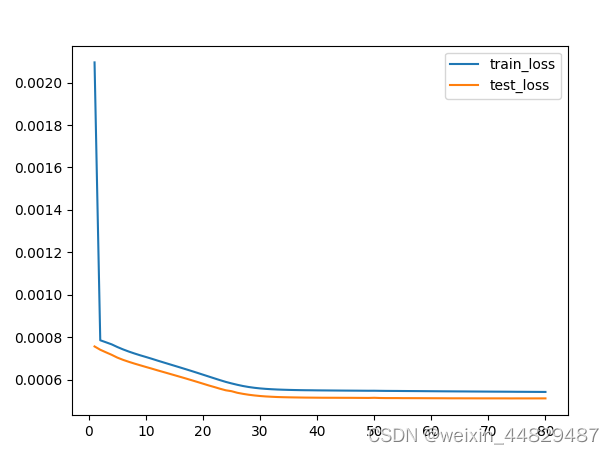
训练完成后输出损失对比如图所示。
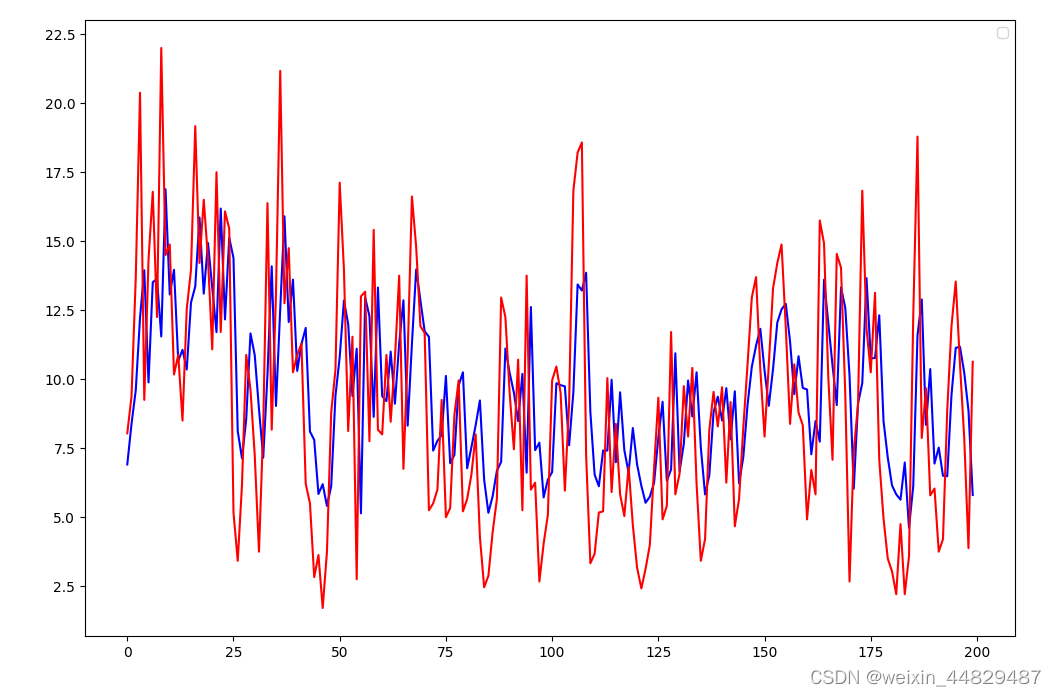
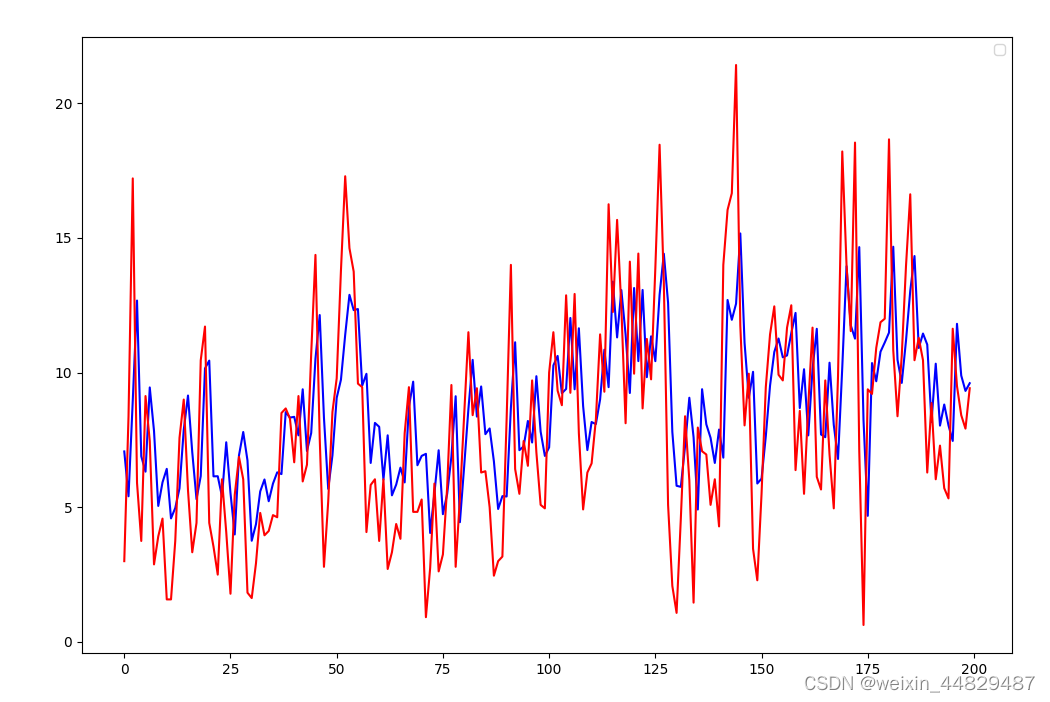
选取200个点进行预测展示,其中蓝色是预测的数据,红色的实际的,第一张图是训练数据的预测效果,第二张图是测试集的训练效果。可以看出来,一些极端值的预测效果不太好。
六、总结及资源
此篇作为毕设笔记记录下来,若有朋友需要源码,可以关注OurTwenty公众号,回复【风速预测cnn】,即可获得。
这篇关于基于pytorch使用一维卷积网络CNN的单特征的风速预测项目实战(适用于单特征预测问题)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





