本文主要是介绍四大场景化模型算法搞定贷中营销场景|实操与效果比对,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在信贷产品业务的贷中期间,银行等金融机构往往会在营销方面实施一些策略,以较大程度挖掘在贷客户的营销价值,从而提升整体业务的综合收益,最常见的营销方式便是金融机构对客户群体的优惠券发放,而优惠券的类型具体包括利息减免券、临时调额券、商家活动券等。
在实际业务场景中,金融机构对客户的优惠券发放并不是随意赠予,而是通过系统中的相关模型策略进行有方向的选择,以此才能实现业务上有针对性的创造收益,这不仅是信贷业务的营销理念,而且是信贷产品的风控要求。因此,对于银行等业务方,如何构建与具体场景紧密联系的营销模型,是产品在贷中或贷后环节中营销风控的重点内容之一。
为了深入理解信贷营销相关模型的开发与应用,本文围绕营销优惠券使用的具体场景,介绍下优惠券使用预测模型的构建思路与实践过程,并结合实例样本数据,通过数据清洗、特征工程、模型训练、模型评估等建模环节,完成模型的整个开发过程。同时,本文选择多种机器学习模型算法来联合构建模型,主要为了尽可能降低由单一模型出现的较大偏差问题,也就是通过多个模型结果来进行融合,并综合应用在实际模型决策中,这样可以有效提高模型的准确性与稳定性,从而更好的发挥模型的综合应用价值。在具体模型构建的过程中,我们将会采用逻辑回归、随机森林、XGBoost、LightGBM共4种分类算法来实现,以完成多个模型的融合应用。
1、场景介绍与样本分析
某商业银行通过三方数据机构引入若干特征数据,希望结合自有存量客群的标签数据来构建一个机器学习模型,以此预测客户群体的营销价值,而实际场景的价值体现是客户对营销优惠券的使用状态。现有一份建模样本数据,包含10000条样本与12个特征,部分样例如图1所示,其中id为样本主键,x01~x10为特征变量,target为目标变量,具体特征字典如图2所示。

图1 样本数据
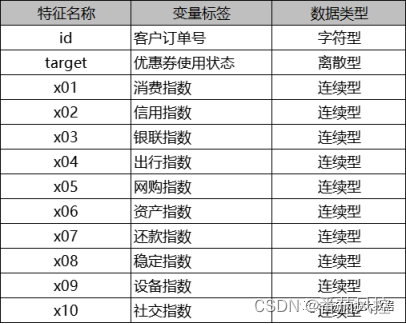
图2 特征字典
对于目标变量target,取值为二分类1和0,分别代表是否使用优惠券,具体定义逻辑是根据客户样本在某一段表现期内是否使用优惠券的实际状态来决定,而特征x01~x10均为客群在观察期的行为数据表现。下面我们通过图3的代码实现过程,来简单探索下样本数据的特征分布情况,包括所有特征变量的分布指标,以及目标变量的占比分布,具体结果如图4、图5所示。
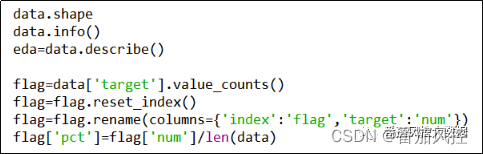
图3 样本指标实现
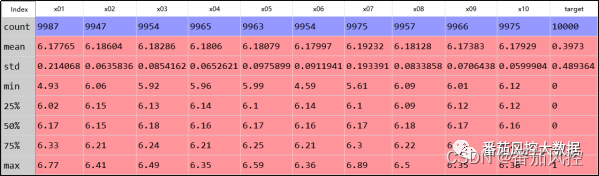
图4 特征变量分布

图5 目标变量分布
从图4特征变量的指标分布count取值可知,x01x10的非缺失数量均小于样本数量10000,因此x01x10都存在缺失值情况,由于其取值类型均为连续型,因此这里采用平均值来进行统一填充,实现过程如图6所示,当然也可以采用中位数、众数等方式处理。
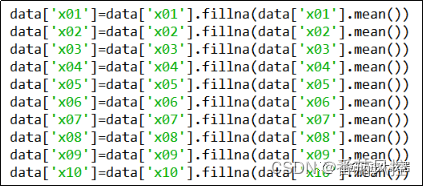
图6 缺失值处理
针对特征变量池,我们通过corr()函数的pearson系数方法,来分析下特征之间的相关性程度,结果分布如图7所示。
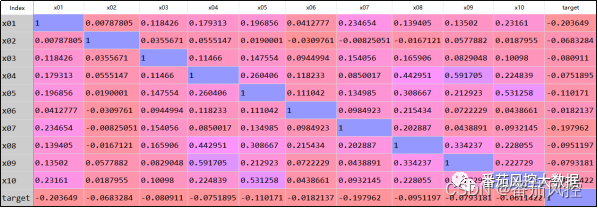
图7 特征相关系数
由上图结果可知,特征变量之间的相关性系数普遍表现较小,多数取值小于0.3,仅有个别几个变量组合的相关系数大于0.5,但最大值也只有0.591705(x04与x09),这与实际场景以0.5~0.7作为特征字段相关性筛选阈值还有一定空间,因此这里可以说明特征变量之间的相关性程度整体较弱,我们这里将所有特征变量予以保留。
2、模型训练与模型评估
接下来我们将根据以上特征预处理后的样本数据,依次采用逻辑回归、随机森林、XGBoost、LightGBM共4种分类算法,来构建营销优惠券使用的预测模型,并选取准确率accuracy指标来评估模型的性能。在模型拟合建立之前,我们将建模样本数据按照常见7:3比例拆分为训练集与验证集,分别用来模型训练与模型测试,具体实现过程如图8所示。

图8 建模样本拆分
通过逻辑回归、随机森林、XGBoost、LightGBM算法实现模型的训练过程,模型学习器的参数配置,除了随机种子random_state赋值便于数据验证外,其余参数均采用默认参数组合。当然,在实际场景中可以通过交叉验证与网格搜索等方法来进行参数调优,已获得相对较优的模型,这里为了重点介绍最终多个模型融合的实现过程,对各模型的构建过程都按照通用情况来完成。各算法的模型训练与模型评估过程分别如图9~12所示。
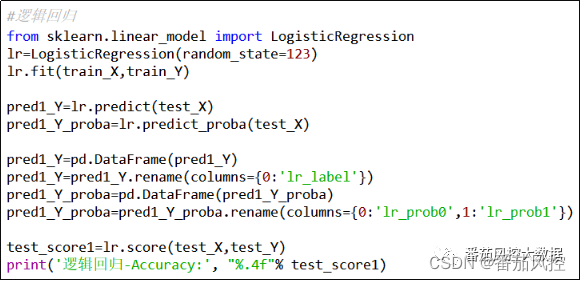
图9 逻辑回归
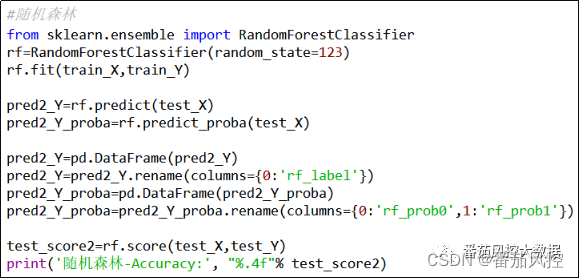
图10 随机森林
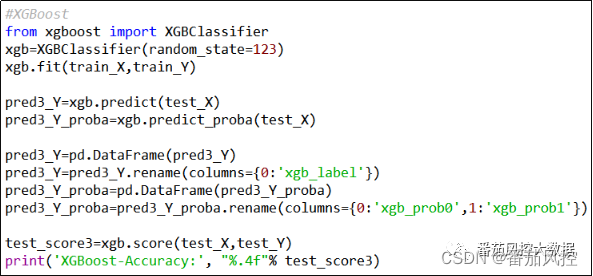
图11 XGBoost
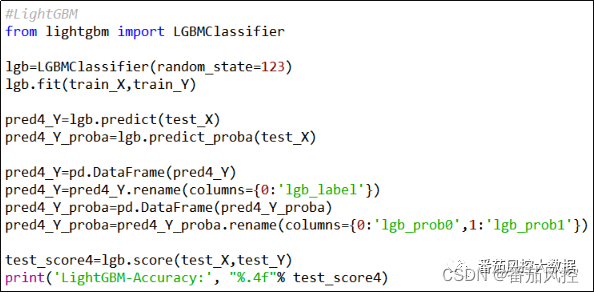
图12 LightGBM
以上过程先后实现了逻辑回归、随机森林、XGBoost、LightGBM的模型训练与模型评估,最终将模型对预测样本的预测标签pred_Y、预测概率pred_Y_proba输出。同时,模型在测试样本数据上的泛化能力表现,通过模型准确率Accuracy指标来进行评价。我们将各模型的准确率指标进行统一打印输出,具体结果如图13所示。
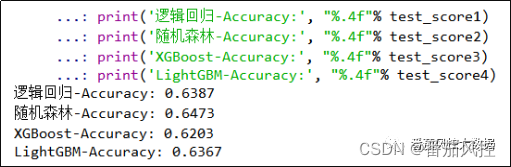
图13 模型准确率指标
通过各模型的准确率指标结果可知,由于各模型的原理逻辑不同,最终得到的模型性能必然存在一定差异,虽然这些量化指标可以直接反映模型的效果,但由于样本数据的分布、模型算法的选择、模型参数的配置等因素,模型很可能出现过拟合、欠拟合、易波动等情况。因此,为了有效提升模型的应用效果,可以尝试采用多种机器学习算法来构建模型,并通过模型融合的思想将各模型的性能进行综合。通常情况下,为实现模型融合的效果,对于不同模型结果会赋予相应权重,或者平均分配或者差异分配,例如本文模型最终预测结果可以取各模型的平均值,下面我们按照模型平均性能的思想来实现模型的融合应用。
现将逻辑回归、随机森林、XGBoost、LightGBM各模型在测试样本数据的预测结果(优惠券是否使用)、目标预测概率(优惠券使用概率)进行汇总,其中预测概率结果分别为lr_prob1、rf_prob1、xgb_prob1、lgb_prob1,并对各模型的预测概率求平均值prob_mean。同时,这里仍以0.5作为标签分类阈值,判断用户是否使用优惠券的预测结果,也就是当平均预测概率prob_mean>=0.5时,预测标签结果prob_label为1(使用优惠券);当平均预测概率prob_mean<0.5时,预测标签结果prob_label为0(未使用优惠券)。以上输出的具体实现过程如图14所示,最终结果的部分样例如图15所示。

图14 模型融合实现
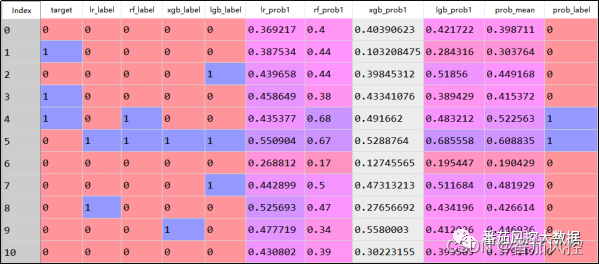
图15 模型融合结果
通过模型融合预测结果可知,模型最终的预测概率结果prob_mean综合考虑了各模型的预测性能,有效降低了由于其中某个模型出现过拟合等情形对预测结果带来的影响,同时也将不同模型的泛化能力进行融合,较大程度提升了模型的区分度与稳定性等效果,这对于模型的实际应用是非常有利的。
当模型融合后,为了评估模型的综合性能,我们仍然选取准确率accuracy指标来评估模型的效果,现根据图15数据的真实标签target与预测标签prob_label,来构建分类模型的混淆矩阵TP、TN、FP、FN,依此来进一步得到模型的accuracy结果,具体实现过程如图16所示。

图16 模型融合指标
模型融合后的指标accuracy为0.6480,现与前边图13输出的各模型结果进行对比可知,模型融合后的准确率accuracy大于任一个子模型的结果,这也直观说明了模型融合的性能提升。当然,以上对比分析结果虽然从数值上差异并不是很大,其原因有模型训练阶段未对模型进行参数调优、建模样本数据的特征分布特点、模型性能评估指标可以增加其他维度等,但模型融合思想对模型效果提升的过程已经得到体现。在实际场景中,可以结合样本数据、模型方法、业务需求等情况,来有效使用模型融合的方法,从而更好的发挥模型在风控或营销中的价值。
3、模型预测的场景应用
当模型构建完成后,包括采用新的测试样本数据评估模型的性能,便可以实现模型在实际场景中应用。本文案例模型为营销优惠券使用预测模型,用来对存量客户群体是否使用优惠券的行为进行预测,其业务流程大致有以下几个步骤:
(1)确定模型应用的存量客户群体样本id,并获取加工模型所需的相关特征变量数据x01~x10;
(2)通过线上或线下模式,通过模型对各样本客户进行预测分析,具体逻辑为先后经过逻辑回归、随机森林、XGBoost、LightGBM共4个子模型,并得到对应预测目标1的概率值,然后取其概率平均值;
(3)根据平均概率值大小判断预测标签结果,当概率>=0.5时预测标签为1,当概率<0.5时预测标签为0;
(4)预测结果为1说明客户使用优惠券的可能性较高,可以发放优惠券;预测结果为0说明客户使用优惠券的可能性较低,不予发放优惠券。
以上过程便实现信贷优惠券使用预测模型的实际场景应用,这为银行等金融机构针对存量客户群体的价值挖掘与活动营销,提供模型策略实施的重要支持,这也是风控模型在场景营销中应用的典型体现。
综合以上内容,我们围绕实际信贷营销业务场景,采用模型融合的思想构建了营销优惠券使用预测的分类模型,无论从模型融合的性能指标分析,还是从模型预测的场景实现效果,都充分认识到模型构建与模型应用的有效结合,为实际业务场景带来了很高的商业价值。为了便于大家进一步熟悉并掌握以上相关内容,我们准备了与本文同步的样本数据与python代码,供大家参考学习,详情请移至知识星球查看相关内容。
…
~原创文章
这篇关于四大场景化模型算法搞定贷中营销场景|实操与效果比对的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








